





编辑推荐:
本文来自于csdn,文章介绍了Python自然语言处理如何识别它们,分析它们的结构,给它们分配词汇类别,以及获得它们的含义,希望对您的学习有所帮助。
目的是要回答下列问题:
(1)如何使用形式化语法来描述无限的句子集合的结构?
(2)如何使用句法树来表示句子结构?
(3)解析器如何分析句子并自动构建语法树?
一、一些语法困境
#语言数据和无限可能性
文法的目的是给出一个明确的语言描述。而我们思考文法的方式与我们认为什么是一种语言紧密联系在一起。观察到的言语和书面文本是否是一个大却有限的集合呢?关于文法句子是否存在一些更抽象的东西,如有能力的说话者能理解的隐性知识?或者是两者的某种组合?我们不会解决这个问题,而是将介绍主要的方法。
#普遍存在的歧义
重要的目的是自然语言understanding,当识别一个文本所包含的语言结构时,可以从中获得多少文本的含义?一段程序在通读了一个文本后,它能否足够“理解”文本,并回答一些简答的问题,如“发生了什么事“或”谁对谁做了什么“?还像以前一样,我们将开发简单的程序来处理已注释的语料库,并执行有用的任务。
二、文法的用途
#超越n-grams
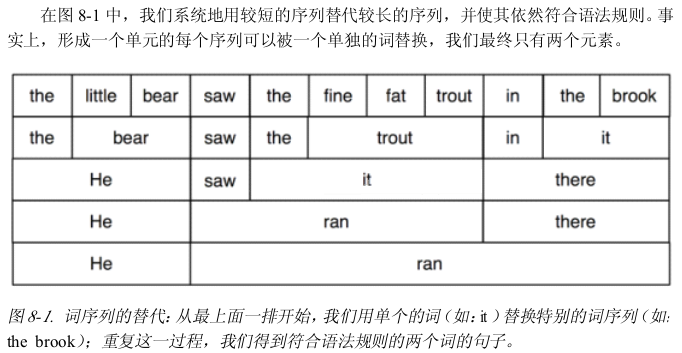
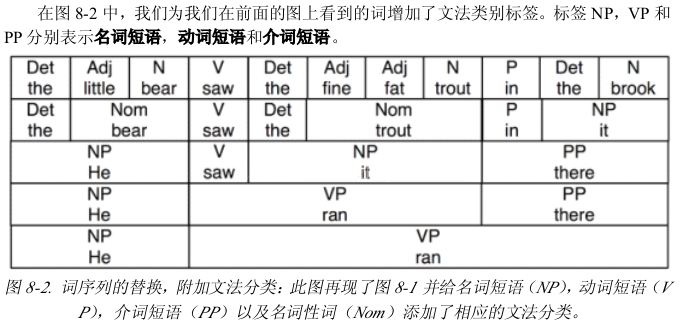
3、上下文无关文法
#一种简单的文法
在NLTK中,上下文无关文法定义在nltk.grammar模块
import nltk
from nltk import CFG
//grammar1 = CFG.fromstring("""
grammar1 = nltk.parse_cfg("""
s -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" |
"Bob" | Det N | Det N PP
Det -> "a" | "an" | "the"
| "my"
N -> "man" | "dog" | "cat"
| "telescope" | "park"
P -> "in" | "on" | "by"
| "with"
""")
sent = "Mary saw Bob".split()
rd_parser = nltk.RecursiveDescentParser(grammar1)
for tree in rd_parser.nbest_parse(sent):
print tree
如果使用上述文法分析句子The dog saw a man in the park,结果将得到两棵树,被称为结构上有歧义
#编写你自己的文法
编写mygrammar.cfg
grammar1 = nltk.data.load('file:mygrammar.cfg')
#句法结构中的递归
产生式左侧的文法类型也出现在右侧,那么这个文法被认为是递归的
四、上下文无关文法分析
解析器根据文法产生式处理输入的句子,并建立一个或多个符合文法的组成结构。
例如问答系统对提交的问题首先进行文法分析
在本节中,我们将看到两个简单的分析算法,一种自上而下的方法称为下降递归分析,一种自下而上的方法称为移进-归约分析。
以及更复杂的算法,一种称为左角落分析的带自下而上过滤的自上而下的方法:一种称为图表分析的动态规划技术
#递归下降解析器
nltk.RecursiveDescentParser(grammar1)
#移进-归约分析
nltk.ShiftReduceParser(grammar1)
#左角落解析器
带自下而上过滤的自上而下的解析器
#符合语句规则的子串表
五、依存关系和依存文法
短语结构文法是关于词和词序列如何结合形成句子成分的。
一种独特且互补的方式,依存文法,集中关注的是词与其他词之间的关系。
依存关系是一个中心词与其从属之间的二元非对称关系。一个句子的中心词通常是动词,所有其他词要么依赖于中心词,要么通过依赖路径与它相关联。
与短语结构文法相比,依存文法可以作为一种依存关系用来直接表示语法功能。
#配价与词汇

在表中的动词被认为具有不同的配价。配价限制不仅适用于动词,也适用于其他类的中心词。
#扩大规模
文法是否可以扩大到能覆盖自然语言中的大型语料库
使用各种正规工具
六、文法开发
如何访问树库,及开发覆盖广泛文法所具有的挑战
#树库和文法
corpus模块定义了树库语料的阅读器,其中包含了宾州树库语料10%的样本
from nltk.corpus
import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
print t
(S
(NP-SBJ
(NP (NNP Pierre) (NNP Vinken))
(, ,)
(ADJP (NP (CD 61) (NNS years)) (JJ old))
(, ,))
(VP
(MD will)
(VP
(VB join)
(NP (DT the) (NN board))
(PP-CLR (IN as) (NP (DT a) (JJ nonexecutive) (NN
director)))
(NP-TMP (NNP Nov.) (CD 29))))
(. .))
!
def filter(tree):
#搜索树库找出句子的补语
child_nodes = [child.label for child in tree if
isinstance(child, nltk.Tree)]
#print tree.label
#print [t for t in tree if tree.label == 'NP']
return (tree.label == 'VP') and ('S' in child_nodes)
from nltk.corpus import treebank
[subtree for tree in treebank.parsed_sents()
for subtree in tree.subtrees(filter)]
entries = nltk.corpus.ppattach.attachments('training')
table = nltk.defaultdict(lambda: nltk.defaultdict(set))
for entry in entries:
key = entry.noun1 + '-' + entry.prep + '-' + entry.noun2
table[key][entry.attachment].add(entry.verb)
for key in sorted(table):
if len(table[key]) > 1:
print key, 'N:', sorted(table[key]['N']), 'V:',
sorted(table[key]['V'])
nltk.corpus.sinica_treebank.parsed_sents()[3450].draw()
#有害的歧义
歧义文法
#加权文法
处理歧义是开发覆盖广泛的解析器的主要任务。图表解析器提高了计算同一个句子的多个分析的效率,但它们仍然会因可能的分析数量过多而不堪重负。加权文法和概率分析算法为这些问题提供了有效的解决方案
def give(t):
return t.label == 'VP' and len(t) > 2 and t[1].label
== 'NP' \
and (t[2].label == 'PP-DTV' or t[2].label == 'NP')
\
and ('give' in t[0].leaves() or 'gave' in t[0].leaves())
def sent(t):
return ' '.join(token for token in t.leaves()
if token[0] not in '*-0')
def print_node(t, width):
output = "%s %s: %s / %s: %s" %\
(sent(t[0]), t[1].label, sent(t[1]), t[2].label,
sent(t[2]))
if len(output) > width:
output = output[:width] + "..."
print output
for tree in nltk.corpus.treebank.parsed_sents():
for t in tree.subtrees(give):
print_node(t, 72)
#概率上下文无关文法(PCFG)
grammar = nltk.parse_pcfg("""
S -> NP VP [1.0]
VP -> TV NP [0.4]
VP -> IV [0.3]
VP -> DatV NP NP [0.3]
TV -> 'saw' [1.0]
IV -> 'ate' [1.0]
DatV -> 'gave' [1.0]
NP -> 'telescopes' [0.8]
NP -> 'Jack' [0.2]
""")














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









