







项目描述:李宏毅机器学习作业4-语句分类
- 本次作业是要让同学接触自然语言处理当中一个简单的任务 —— 语句分类(文本分类)
- 给定一个语句,判断他有没有恶意(负面标 1,正面标 0)
数据集介绍
有三个文件,分别是 training_label.txt、training_nolabel.txt、testing_data.txt
- training_label.txt:有标签的训练数据(句子配上 0 or 1,+++$+++ 只是分隔符号,不要理它)
- e.g., 1 +++$+++ are wtf … awww thanks !
- training_nolabel.txt:没有标签的训练数据(只有句子),用来做半监督学习
- ex: hates being this burnt !! ouch
- testing_data.txt:你要判断测试数据里面的句子是 0 or 1
id,text
0,my dog ate our dinner . no , seriously … he ate it .
1,omg last day sooon n of primary noooooo x im gona be swimming out of school wif the amount of tears am gona cry
2,stupid boys … they ’ re so … stupid !
项目要求
- 用一些方法 pretrain 出 word embedding (e.g., skip-gram, CBOW. )
- 请使用 RNN 实现文本分类
- 不能使用额外 data (禁止使用其他 corpus 或 pretrained model)
以下内容参考飞桨官方教程
首先介绍使用RNN实现自然语言情感分析的原理和流程,然后再实现项目。
第一部分
自然语言情感分析
自然语言情感分析和文本匹配是日常生活中最常用的两类自然语言处理任务,本文主要介绍情感分析实现和典型模型,以及如何使用飞桨完成情感分析任务。
人类自然语言具有高度的复杂性,相同的对话在不同的情景,不同的情感,不同的人演绎,表达的效果往往也会迥然不同。例如"你真的太瘦了",当你聊天的对象是一位身材苗条的人,这是一句赞美的话;当你聊天的对象是一位肥胖的人时,这就变成了一句嘲讽。感兴趣的读者可以看一段来自肥伦秀的视频片段,继续感受下人类语言情感的复杂性。
从视频中的内容可以看出,人类自然语言不只具有复杂性,同时也蕴含着丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
简单的说,我们可以将情感分析(sentiment classification)任务定义为一个分类问题,即指定一个文本输入,机器通过对文本进行分析、处理、归纳和推理后自动输出结论,如图1所示。
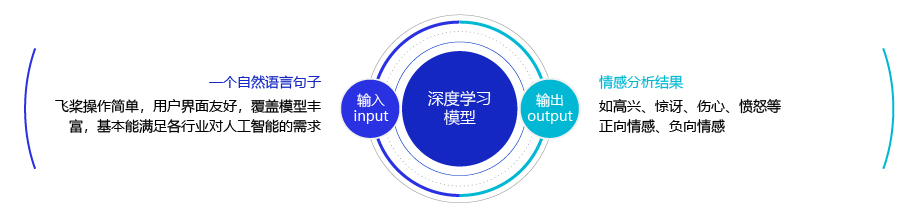
图1:情感分析任务
通常情况下,人们把情感分析任务看成一个三分类问题,如 图2 所示:

图2:情感分析任务
- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
使用深度神经网络完成情感分析任务
每个单词转换成向量的方式,可以完成单词语义计算任务。把每个自然语言句子也转换成一个向量表示,并使用这个向量表示完成情感分析任务。
在日常工作中有一个非常简单粗暴的解决方式:就是先把一个句子中所有词的embedding进行加权平均,再用得到的平均embedding作为整个句子的向量表示。然而由于自然语言变幻莫测,我们在使用神经网络处理句子的时候,往往会遇到如下两类问题:
变长的句子: 自然语言句子往往是变长的,不同的句子长度可能差别很大。然而大部分神经网络接受的输入都是张量,长度是固定的,那么如何让神经网络处理变长数据成为了一大挑战。
组合的语义: 自然语言句子往往对结构非常敏感,有时稍微颠倒单词的顺序都可能改变这句话的意思,比如:
你等一下我做完作业就走。
我等一下你做完工作就走。
我不爱吃你做的饭。
你不爱吃我做的饭。
我瞅你咋地。
你瞅我咋地。
因此,我们需要找到一个可以考虑词和词之间顺序(关系)的神经网络,用于更好地实现自然语言句子建模。
循环神经网络RNN和长短时记忆网络LSTM
RNN相当于将神经网络单元进行了横向连接,处理前一部分输入的RNN单元不仅有正常的模型输出,还会输出“记忆”传递到下一个RNN单元。而处于后一部分的RNN单元,不仅仅有来自于任务数据的输入,同时会接收从前一个RNN单元传递过来的记忆输入,这样就使得整个神经网络具备了“记忆”能力。
但是RNN网络只是初步实现了“记忆”功能,在此基础上科学家们又发明了一些RNN的变体,来加强网络的记忆能力。但RNN对“记忆”能力的设计是比较粗糙的,当网络处理的序列数据过长时,累积的内部信息就会越来越复杂,直到超过网络的承载能力,通俗的说“事无巨细的记录,总有一天大脑会崩溃”。为了解决这个问题,科学家巧妙的设计了一种记忆单元,称之为“长短时记忆网络(Long Short-Term Memory,LSTM)”。在每个处理单元内部,加入了输入门、输出门和遗忘门的设计,三者有明确的任务分工:
- 输入门:控制有多少输入信号会被融合;
- 遗忘门:控制有多少过去的记忆会被遗忘;
- 输出门:控制多少处理后的信息会被输出;
RNN网络结构
RNN是一个非常经典的面向序列的模型,可以对自然语言句子或是其它时序信号进行建模,网络结构如图3所示。
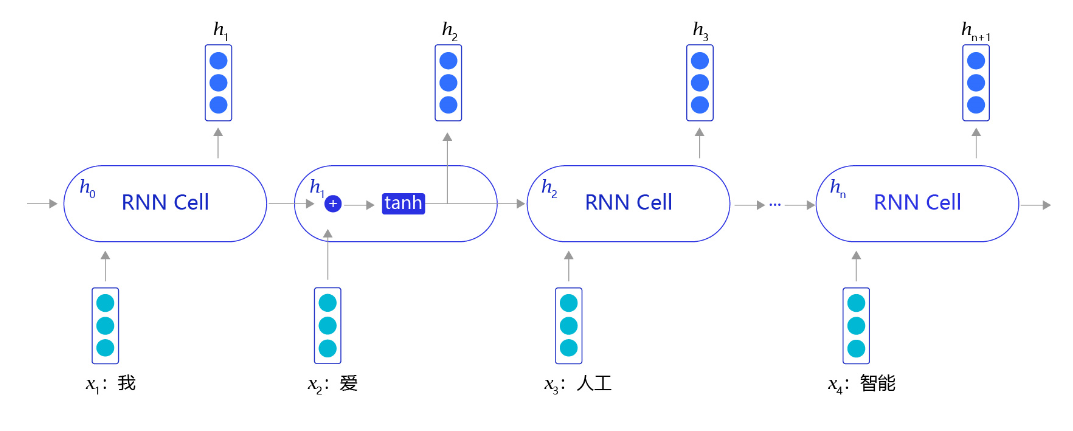
图3:RNN网络结构
LSTM网络结构
上述方法听上去很有效(事实上在有些任务上效果还不错),但是存在一个明显的缺陷,就是当阅读很长的序列时,网络内部的信息会变得越来越复杂,甚至会超过网络的记忆能力,使得最终的输出信息变得混乱无用。长短时记忆网络(Long Short-Term Memory,LSTM)内部的复杂结构正是为处理这类问题而设计的,其网络结构如 图4所示。
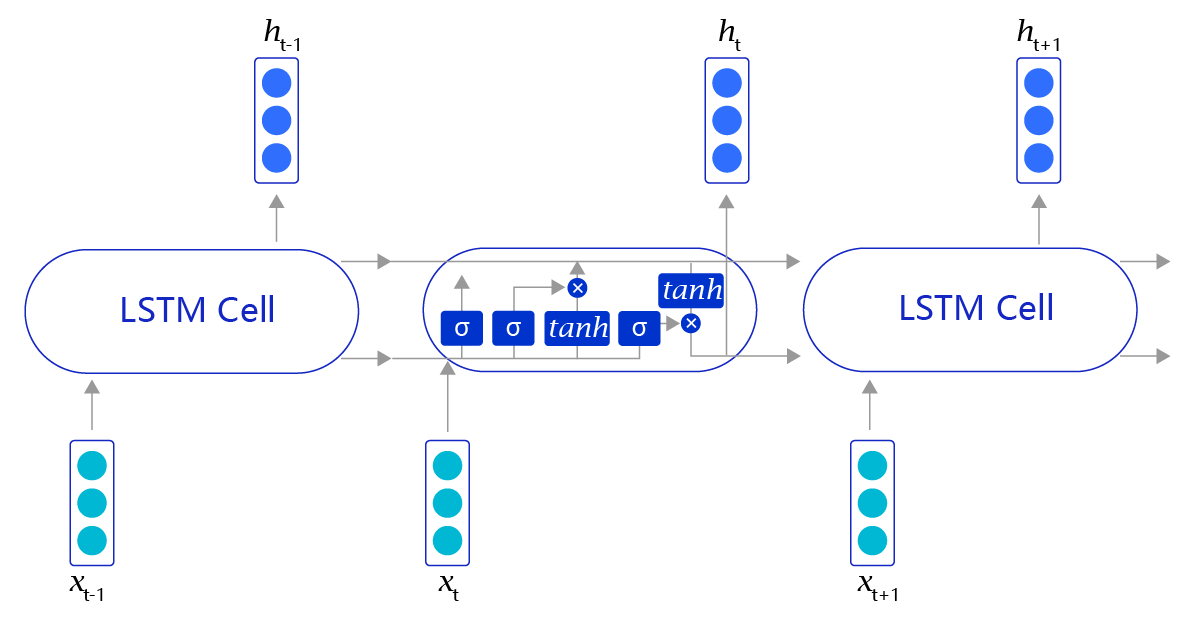
图4:LSTM网络结构
长短时记忆网络的结构和循环神经网络非常类似,都是通过不断调用同一个cell来逐次处理时序信息。每阅读一个新单词xt,就会输出一个新的输出信号ht ,用来表示当前阅读到所有内容的整体向量表示。不过二者又有一个明显区别,长短时记忆网络在不同cell之间传递的是两个记忆信息,而不像循环神经网络一样只有一个记忆信息,此外长短时记忆网络的内部结构也更加复杂,如 图5所示。
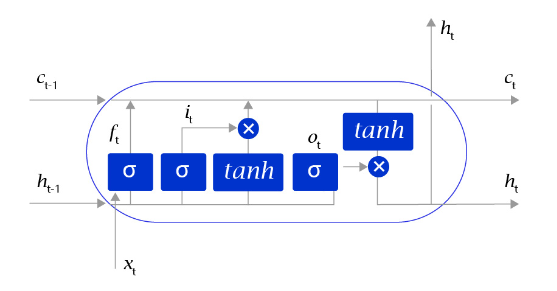
图5:LSTM网络内部结构示意图
区别于循环神经网络RNN,长短时记忆网络最大的特点是在更新内部记忆时,引入了遗忘机制。即容许网络忘记过去阅读过程中看到的一些无关紧要的信息,只保留有用的历史信息。通过这种方式延长了记忆长度。
使用LSTM完成情感分析任务
借助长短时记忆网络,我们可以非常轻松地完成情感分析任务。如 图6 所示。对于每个句子,我们首先通过截断和填充的方式,把这些句子变成固定长度的向量。然后,利用长短时记忆网络,从左到右开始阅读每个句子。在完成阅读之后,我们使用长短时记忆网络的最后一个输出记忆,作为整个句子的语义信息,并直接把这个向量作为输入,送入一个分类层进行分类,从而完成对情感分析问题的神经网络建模。
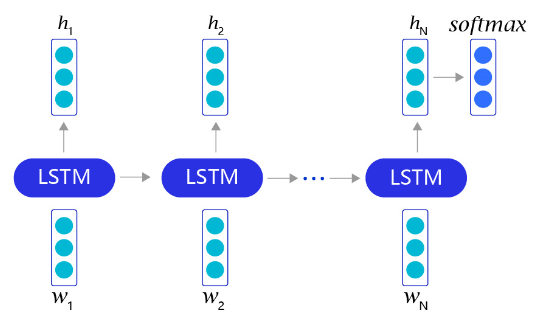
图6:LSTM完成情感分析任务流程
使用飞桨实现基于LSTM的情感分析模型
接下来让我们看看如何使用飞桨实现一个基于长短时记忆网络的情感分析模型。在飞桨中,不同深度学习模型的训练过程基本一致,流程如下:
-
1 数据处理:选择需要使用的数据,并做好必要的预处理工作。
-
2 网络定义:使用飞桨定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。
-
3 网络训练:将准备好的数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。
-
4 网络评估:使用测试集合测试训练好的神经网络,看看训练效果如何。
第二部分
这部分为代码实现过程,参考项目
1 数据处理
import paddle
import numpy as np
import matplotlib.pyplot as plt
import paddle.nn as nn
import os
import random
import numpy as np
print(paddle.__version__)
2.0.1
生成字典
def open_label(data_path): # 打开文件并读取数据
'''
这里数据读取适合与‘label’和‘nolabel’,因为data文件数据是标签 + 文本 读取出来的数据不正确
'''
dict_set = set() # 新建一个集合(内容不可重复)
with open(data_path, 'r', encoding='utf-8') as f: # 读取数据到f
for line in f.readlines(): # 逐行获取f的内容
# print(1)
title = line.split('+++$+++')[-1].replace('\n', '').split(' ') # 此处效果查看上一个code
for s in title[1:]: # 循环内容
dict_set.add(s) # 数据存入集合
# print(dict_set)
print(f'{data_path}数据读取完毕')
return dict_set
def open_data(data_path): # 打开文件并读取数据
dict_set = set() # 新建一个集合(内容不可重复)
with open(data_path, 'r', encoding='utf-8') as f: # 读取数据到f
for line in f.readlines(): # 逐行获取f的内容
# print(1)
title = line.replace(',', ' ').replace('\n', '').split(' ')
for s in title[1:]: # 循环内容
dict_set.add(s) # 数据存入集合
# print(dict_set)
print(f'{data_path}数据读取完毕')
return dict_set
def create_dict(label_path, nolabel_path, data_path, dict_path):
'''
把数据生成字典
'''
print('正在读取数据……')
label_data = open_label(label_path) # 读取数据
nolabel_data = open_label(nolabel_path)
data_data = open_data(data_path)
dict_set = label_data | nolabel_data | data_data # 使用并集获得数据
print('正在生产字典……')
dict_list = [] # 新建一个空列表
i = 0
for s in dict_set: # 循环集合
dict_list.append([s, i]) # 存入集合并新建一个单独对应的数值
i += 1
dict_txt = dict(dict_list) # 强制转换成 字典
end_dict = {"<unk>": i} # 添加未知字符<unk>
dict_txt.update(end_dict) # 空字符数据存入
# 把这些字典保存到本地中
with open(dict_path, 'w', encoding='utf-8') as f:
f.write(str(dict_txt)) # 把字典存入文本
print("数据字典生成完成!")
print(f'字典长度为:{len(dict_txt.keys())}')
return dict_txt
label_path = 'work/data/training_label.txt'
data_path = 'work/data/testing_data.txt'
nolabel_path = 'work/data/training_nolabel.txt'
dict_path = './dict.txt'
word_dict = create_dict(label_path, nolabel_path, data_path, dict_path)
正在读取数据……
work/data/training_label.txt数据读取完毕
work/data/training_nolabel.txt数据读取完毕
work/data/testing_data.txt数据读取完毕
正在生产字典……
数据字典生成完成!
字典长度为:245076
print(word_dict['deux']) # 选择查看
print(word_dict['<unk>']) # 选择查看
131942
245075
2 监督式学习
使用training_label.txt作为训练集
数据集处理
# 创建数据集和数据字典
with open('work/data/training_label.txt', 'r', encoding='utf-8') as f_data: # 读取文件
data_list = [] # 新建列表
for line in f_data.readlines(): # 逐行读取
# print(line)
title = line.split('+++$+++')[-1].replace('\n', '').split(' ') # 获取文本数据列表
l = line.split()[0] # 获取标签
labs = ""
for s in title[1:]: # 循环得到数据
lab = str(word_dict[s]) # 获取数据对应标签
labs = labs + lab + ',' # 逐个添加数据并加上,
labs = labs[:-1] # 去掉最后一个,
labs = labs + '\t' + l + '\n' # 获得文本数据加上tab加上标签加上换行
data_list.append(labs) # 添加进数据
random.shuffle(data_list) # 打乱数据
val_len = int(len(data_list)*0.8) # 按照8:2进行切割
val_data = data_list[val_len:] # 后面20%
train_data = data_list[:val_len] # 前面80%
with open('./val.txt', 'w', encoding='utf-8') as f_val:
f_val.write(str(val_data)) # 写入数据
with open('./train.txt', 'w', encoding='utf-8') as f_train:
f_train.write(str(train_data))
print("数据列表生成完成!")
print(f'训练集数据{len(train_data)}条')
print(f'验证集数据{len(val_data)}条')
数据列表生成完成!
训练集数据160000条
验证集数据40000条
vocab_size = len(word_dict) + 1 # 字典长度加一 备用
print(vocab_size)
seq_len = 36 # 数据集长度(需要扩充的长度)
batch_size = 256 # 批处理大小
epochs = 20 # 训练轮数
pad_id = word_dict['<unk>'] # 空的填充内容值
# 生成句子列表
def ids_to_str(ids):
# print(ids)
words = []
for k in ids: # 循环列表
w = list(word_dict)[eval(k)] # 获取对应索引的值
words.append(w if isinstance(w, str) else w.decode('ASCII')) # 写入数据
return " ".join(words) # 返回拼接的数据
245077
for i in train_data: # 循环数据
# i = i
print(i) # 输出原始数据
sent = i[:-3].split(',') # 数据处理
label = int(i[-2]) # 获取标签
print('sentence list id is:', sent)
print('sentence label id is:', label)
print('--------------------------')
print('sentence list is: ', ids_to_str(sent))
print('sentence label is: ', label)
break
9340,138266,104740,154830,9549,173858,195786,140148,97453,81404,44777,41893 1
sentence list id is: ['9340', '138266', '104740', '154830', '9549', '173858', '195786', '140148', '97453', '81404', '44777', '41893']
sentence label id is: 1
--------------------------
sentence list is: going to a clients house warming party they ' re so sweet
sentence label is: 1
# 读取数据扩充并查看
def create_padded_dataset(dataset):
padded_sents = []
labels = []
for batch_id, data in enumerate(dataset): # 循环得到数据
data = data.replace('\n', '').replace('\t', ',').split(',') # 对数据做处理得到列表
# print(data)
sent, label = data[:-2], data[-1] # 返回数字化文本及标签
padded_sent = np.concatenate([sent[:seq_len], [pad_id] * (seq_len - len(sent))]).astype('int64') # 数字化文本扩充
# print(padded_sent)
padded_sents.append(padded_sent) # 添加到数字化文本列表
labels.append(label) # 添加到标签列表
# print(padded_sents)
return np.array(padded_sents), np.array(labels).astype('int64').reshape(len(labels),1) # 返回数据
# 对train、val数据进行实例化
train_sents, train_labels = create_padded_dataset(train_data)
val_sents, val_labels = create_padded_dataset(val_data)
# 查看数据大小
print(train_sents.shape)
print(train_labels.shape)
print(val_sents.shape)
print(val_labels.shape)
(160000, 36)
(160000, 1)
(40000, 36)
(40000, 1)
for i in train_sents: # 查看train数据
print(i)
break
[128221 30302 142063 69274 158186 110374 32104 93947 167799 212475
115170 190591 61282 20114 132417 241386 187157 142063 26145 147123
146913 241304 93947 167568 245075 245075 245075 245075 245075 245075
245075 245075 245075 245075 245075 245075]
# 继承paddle.io.Dataset对数据进行处理
class Dataset(paddle.io.Dataset):
'''
继承paddle.io.Dataset类进行封装数据
'''
def __init__(self, sents, labels):
# 数据读取
self.sents = sents
self.labels = labels
def __getitem__(self, index):
# 数据处理
data = self.sents[index]
label = self.labels[index]
return data, label
def __len__(self):
# 返回大小数据
return len(self.sents)
# 数据实例化
train_dataset = Dataset(train_sents, train_labels)
val_dataset = Dataset(val_sents, val_labels)
# 封装成生成器
train_loader = paddle.io.DataLoader(train_dataset, return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
val_loader = paddle.io.DataLoader(val_dataset, return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
for i in train_loader : # 查看封装后的数据
print(i)
break
[Tensor(shape=[256, 36], dtype=int64, place=CUDAPinnedPlace, stop_gradient=True,
[[55413 , 18259 , 26521 , ..., 245075, 245075, 245075],
[206951, 158070, 3754 , ..., 245075, 245075, 245075],
[30302 , 142063, 69274 , ..., 245075, 245075, 245075],
...,
[10745 , 150219, 167899, ..., 245075, 245075, 245075],
[93947 , 18718 , 193823, ..., 245075, 245075, 245075],
[145662, 192433, 24218 , ..., 245075, 245075, 245075]]), Tensor(shape=[256, 1], dtype=int64, place=CUDAPinnedPlace, stop_gradient=True,
[[0],
[1],
[1],
[0],...]
3 搭建网络
RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!
3.1 搭建模型
class MyRNN(paddle.nn.Layer):
def __init__(self):
super(MyRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, 256) # 嵌入层用于自动构造一个二维embedding矩阵
self.rnn = nn.SimpleRNN(256, 256, num_layers=2, direction='forward',dropout=0.5) # 使用简易的RNN模型
self.linear = nn.Linear(in_features=256*2, out_features=2) # 分类器
self.dropout = nn.Dropout(0.62)
def forward(self, inputs):
emb = self.dropout(self.embedding(inputs))
#output形状大小为[batch_size,seq_len,num_directions * hidden_size]
#hidden形状大小为[num_layers * num_directions, batch_size, hidden_size]
#把前向的hidden与后向的hidden合并在一起
output, hidden = self.rnn(emb)
hidden = paddle.concat((hidden[-2,:,:], hidden[-1,:,:]), axis = 1)
#hidden形状大小为[batch_size, hidden_size * num_directions]
hidden = self.dropout(hidden)
return self.linear(hidden)
# 可视化定义
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=20) # 标题
plt.xlabel("iter", fontsize=15) # x轴
plt.ylabel(label, fontsize=15) # y轴
plt.plot(iters, data,color=color,label=label) # 画图
plt.legend()
plt.grid()
plt.savefig('{}.jpg'.format(label))
plt.show()
3.2 模型配置
# 训练模型
# 训练集16万条句子,验证集4万条句子
batch_size = 256 # 批处理大小
epochs = 20 # 训练轮数
def train(model):
model.train()
# 设置学习率,余弦退火
def create_optim(parameters):
step_each_epoch = len(train_data) // batch_size
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=5.6e-4,
T_max=step_each_epoch * epochs)
return paddle.optimizer.Adam(learning_rate=lr,parameters=parameters
)
opt = create_optim(model.parameters())
# 初始值设置
steps = 0
Iters, total_loss, total_acc = [], [], []
for epoch in range(epochs): # 训练循环
for batch_id, data in enumerate(train_loader): # 数据循环
steps += 1
sent = data[0] # 获取数据
label = data[1] # 获取标签
logits = model(sent) # 输入数据
loss = paddle.nn.functional.cross_entropy(logits, label) # loss获取
acc = paddle.metric.accuracy(logits, label) # acc获取
batch_id+=1
if batch_id % 200 == 0: # 每300次输出一次结果
Iters.append(steps) # 保存训练轮数
total_loss.append(loss.numpy()[0]) # 保存loss
total_acc.append(acc.numpy()[0]) # 保存acc
print("epoch: {}, batch_id: {}, accuracy: {}, loss: {}".format(epoch, batch_id, acc.numpy(), loss.numpy())) # 输出结果
# 数据更新
loss.backward()
opt.step()
opt.clear_grad()
# 每一个epochs进行一次评估
model.eval()
val_acc = []
val_loss = []
Iter = []
STEP = 0
for batch_id, data in enumerate(val_loader): # 数据循环读取
STEP += 1
sent = data[0] # 训练内容读取
label = data[1] # 标签读取
logits = model(sent) # 训练数据
loss = paddle.nn.functional.cross_entropy(logits, label) # loss获取
acc = paddle.metric.accuracy(logits, label) # acc获取
Iter.append(STEP)
val_acc.append(acc.numpy()) # 添加数据
val_loss.append(loss.numpy())
avg_acc, avg_loss = np.mean(val_acc), np.mean(val_loss) # 获取loss、acc平均值
print('Eval begin...')
print("[validation] avg_acc: {}, avg_loss: {}".format(avg_acc, avg_loss)) # 输出值
model.train()
# 每10个epoch保存一下模型
epoch = epoch+1
if epoch % 10 ==0:
paddle.save(model.state_dict(),"ckp/{}ckp.pdparams".format(str(epoch))) # 保存训练文件
draw_process("training loss","red",Iters,total_loss,"train loss") # 画出train loss图
draw_process("training acc","green",Iters,total_acc,"train acc") # 画出train acc图
draw_process("validation loss","red",Iter,val_loss,"val_loss") # 画出val_loss图
draw_process("validation acc","green",Iter,val_acc,"val_acc") # 画出val_acc图
3.3 模型训练
model = MyRNN() # 模型实例化
train(model) # 开始训练
epoch: 0, batch_id: 200, accuracy: [0.5], loss: [0.7014531]
epoch: 0, batch_id: 400, accuracy: [0.484375], loss: [0.6935514]
epoch: 0, batch_id: 600, accuracy: [0.515625], loss: [0.6918366]
Eval begin...
[validation] avg_acc: 0.49984976649284363, avg_loss: 0.6931562423706055
epoch: 1, batch_id: 200, accuracy: [0.46484375], loss: [0.695241]
epoch: 1, batch_id: 400, accuracy: [0.5625], loss: [0.6909167]
epoch: 1, batch_id: 600, accuracy: [0.4921875], loss: [0.6933026]
Eval begin...
[validation] avg_acc: 0.5044320821762085, avg_loss: 0.6931865215301514
epoch: 2, batch_id: 200, accuracy: [0.515625], loss: [0.69394255]
epoch: 2, batch_id: 400, accuracy: [0.50390625], loss: [0.69159836]
epoch: 2, batch_id: 600, accuracy: [0.5], loss: [0.6946838]
Eval begin...
[validation] avg_acc: 0.5085136294364929, avg_loss: 0.6932063698768616
epoch: 3, batch_id: 200, accuracy: [0.53125], loss: [0.68819106]
epoch: 3, batch_id: 400, accuracy: [0.5], loss: [0.6933438]
epoch: 3, batch_id: 600, accuracy: [0.578125], loss: [0.67811036]
Eval begin...
[validation] avg_acc: 0.49859777092933655, avg_loss: 0.6973714828491211
epoch: 4, batch_id: 200, accuracy: [0.57421875], loss: [0.68346256]
epoch: 4, batch_id: 400, accuracy: [0.5703125], loss: [0.6817767]
epoch: 4, batch_id: 600, accuracy: [0.63671875], loss: [0.6646446]
Eval begin...
[validation] avg_acc: 0.5954777598381042, avg_loss: 0.6798470616340637
epoch: 5, batch_id: 200, accuracy: [0.6328125], loss: [0.66024244]
epoch: 5, batch_id: 400, accuracy: [0.65625], loss: [0.64282537]
epoch: 5, batch_id: 600, accuracy: [0.6015625], loss: [0.6709965]
Eval begin...
[validation] avg_acc: 0.5765224099159241, avg_loss: 0.6759021282196045
epoch: 6, batch_id: 200, accuracy: [0.66015625], loss: [0.64031386]
epoch: 6, batch_id: 400, accuracy: [0.640625], loss: [0.64100415]
epoch: 6, batch_id: 600, accuracy: [0.609375], loss: [0.63711953]
Eval begin...
[validation] avg_acc: 0.6332131624221802, avg_loss: 0.6366085410118103
epoch: 7, batch_id: 200, accuracy: [0.65234375], loss: [0.6513518]
epoch: 7, batch_id: 400, accuracy: [0.6953125], loss: [0.6013512]
epoch: 7, batch_id: 600, accuracy: [0.71875], loss: [0.5901048]
Eval begin...
[validation] avg_acc: 0.6379457116127014, avg_loss: 0.63725346326828
epoch: 8, batch_id: 200, accuracy: [0.65234375], loss: [0.6219841]
epoch: 8, batch_id: 400, accuracy: [0.6953125], loss: [0.60392636]
epoch: 8, batch_id: 600, accuracy: [0.66015625], loss: [0.6314429]
Eval begin...
[validation] avg_acc: 0.6436548233032227, avg_loss: 0.6273004412651062
epoch: 9, batch_id: 200, accuracy: [0.68359375], loss: [0.60898435]
epoch: 9, batch_id: 400, accuracy: [0.66015625], loss: [0.61758804]
epoch: 9, batch_id: 600, accuracy: [0.66015625], loss: [0.6245533]
Eval begin...
[validation] avg_acc: 0.642653226852417, avg_loss: 0.6276955008506775
epoch: 10, batch_id: 200, accuracy: [0.6875], loss: [0.58255136]
epoch: 10, batch_id: 400, accuracy: [0.671875], loss: [0.62539446]
epoch: 10, batch_id: 600, accuracy: [0.703125], loss: [0.6012002]
Eval begin...
[validation] avg_acc: 0.6625601053237915, avg_loss: 0.6220404505729675
epoch: 11, batch_id: 200, accuracy: [0.7421875], loss: [0.56108147]
epoch: 11, batch_id: 400, accuracy: [0.69140625], loss: [0.587453]
epoch: 11, batch_id: 600, accuracy: [0.6796875], loss: [0.6313712]
Eval begin...
[validation] avg_acc: 0.6417768597602844, avg_loss: 0.6486363410949707
epoch: 12, batch_id: 200, accuracy: [0.6640625], loss: [0.6129787]
epoch: 12, batch_id: 400, accuracy: [0.65625], loss: [0.61287415]
epoch: 12, batch_id: 600, accuracy: [0.7265625], loss: [0.5415983]
Eval begin...
[validation] avg_acc: 0.668043851852417, avg_loss: 0.6173667907714844
epoch: 13, batch_id: 200, accuracy: [0.74609375], loss: [0.52598614]
epoch: 13, batch_id: 400, accuracy: [0.77734375], loss: [0.47085267]
epoch: 13, batch_id: 600, accuracy: [0.8046875], loss: [0.4610673]
Eval begin...
[validation] avg_acc: 0.7451422214508057, avg_loss: 0.540494978427887
epoch: 14, batch_id: 200, accuracy: [0.76171875], loss: [0.54218376]
epoch: 14, batch_id: 400, accuracy: [0.765625], loss: [0.5079912]
epoch: 14, batch_id: 600, accuracy: [0.73828125], loss: [0.532635]
Eval begin...
[validation] avg_acc: 0.7618439793586731, avg_loss: 0.519909679889679
epoch: 15, batch_id: 200, accuracy: [0.79296875], loss: [0.4892076]
epoch: 15, batch_id: 400, accuracy: [0.78515625], loss: [0.478628]
epoch: 15, batch_id: 600, accuracy: [0.83984375], loss: [0.3609721]
Eval begin...
[validation] avg_acc: 0.7523788213729858, avg_loss: 0.5090236067771912
epoch: 16, batch_id: 200, accuracy: [0.80859375], loss: [0.45524317]
epoch: 16, batch_id: 400, accuracy: [0.7890625], loss: [0.45182455]
epoch: 16, batch_id: 600, accuracy: [0.828125], loss: [0.39013717]
Eval begin...
[validation] avg_acc: 0.7633463740348816, avg_loss: 0.4987851083278656
epoch: 17, batch_id: 200, accuracy: [0.7890625], loss: [0.48315755]
epoch: 17, batch_id: 400, accuracy: [0.80859375], loss: [0.44130948]
epoch: 17, batch_id: 600, accuracy: [0.8359375], loss: [0.41250637]
Eval begin...
[validation] avg_acc: 0.7655248641967773, avg_loss: 0.5056511163711548
epoch: 18, batch_id: 200, accuracy: [0.859375], loss: [0.36119157]
epoch: 18, batch_id: 400, accuracy: [0.80859375], loss: [0.44725162]
epoch: 18, batch_id: 600, accuracy: [0.85546875], loss: [0.35680088]
Eval begin...
[validation] avg_acc: 0.7639973759651184, avg_loss: 0.5168789625167847
epoch: 19, batch_id: 200, accuracy: [0.85546875], loss: [0.31379104]
epoch: 19, batch_id: 400, accuracy: [0.84765625], loss: [0.4031881]
epoch: 19, batch_id: 600, accuracy: [0.84765625], loss: [0.3518069]
Eval begin...
[validation] avg_acc: 0.7659755349159241, avg_loss: 0.5200071334838867




# 保存最后的模型
paddle.save(model.state_dict(),"ckp/model_final.pdparams")
3.4 模型评估
经过反复的调整超参数,模型在训练集和验证集的loss和acc曲线如下图所示,从曲线上看出虽然使用了droutpout,但是过拟合仍较为严重,模型在验证集的最终结果为下面的结果所示:avg_acc: 0.7659, avg_loss: 0.52
4 测试集数据处理及预测
4.1 测试集数据预处理
with open('work/data/testing_data.txt', 'r', encoding='utf-8') as f_data: # 读取文件
data_list = [] # 新建列表
for line in f_data.readlines(): # 逐行读取
# print(line)
title = line.replace(',', ' ').replace('\n', '').split(' ') # 数据处理(把序列号和内容进行删除)
# print(title)
if title[0] != 'id':
labs = []
for s in title[1:]: # 循环得到数据
lab = str(word_dict[s]) # 获取数据对应标签
labs.append(lab) # 逐个添加数据并加上,
# print(labs)
data_list.append(labs) # 添加进数据
# print(data_list)
def create_padded_dataset(dataset):
padded_sents = []
labels = []
for batch_id, data in enumerate(dataset): # 循环得到数据
# print(data)
sent = data # 返回数字化文本及标签
padded_sent = np.concatenate([sent[:seq_len], [pad_id] * (seq_len - len(sent))]).astype('int64') # 数字化文本扩充
# print(padded_sent)
padded_sents.append(padded_sent) # 添加到数字化文本列表
# print(padded_sents)
return np.array(padded_sents) # 返回数据
# 由于测试集的数据有20万条全部预测所花费的时间很久,
#可以在加载测试集的时候做这样的操作
# test_loader = create_padded_dataset(data_list[:1000])
test_loader = create_padded_dataset(data_list)
4.2 执行预测
# 生成句子列表
def ids_to_str(ids):
# print(ids)
words = []
for k in ids: # 循环列表
w = list(word_dict)[k] # 获取对应索引的值
words.append(w if isinstance(w, str) else w.decode('ASCII')) # 写入数据
return " ".join(words) # 返回拼接的数据
label_map = {0:"negative", 1:"positive"}
model_state_dict = paddle.load('ckp/model_final.pdparams') # 导入模型
model = MyRNN() # 实例化网络
model.set_state_dict(model_state_dict)
model.eval()
predictions = []
pre_labels = []
for batch_id, data in enumerate(test_loader): # 循环数据
# print(data)
results = model(paddle.to_tensor(data.reshape(1,36))) # 开始训练
for probs in results:
# 映射分类label
idx = np.argmax(probs) # 获取标签
label = label_map[idx] # 判断类型
pre_labels.append(idx)
predictions.append(label)
# 显示预测结果
# for i,pre in enumerate(predictions):
# print(' 数据: {} \n 情感: {}'.format(ids_to_str(data.tolist()), pre))
# print(idx)
# break
import pandas as pd
for i,pre in enumerate(predictions):
print(' 数据: {} \n 情感: {}'.format(ids_to_str(data.tolist()), pre))
print(idx)
break
数据: why do i get my hopes ? <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk> <unk>
情感: positive
1
# 输出预测结果
path_prefix = './'
ID = np.arange(len(pre_labels))
# 把预测结果写到csv
results = pd.DataFrame({"id":ID,"pre_labels":pre_labels,'predictions':predictions})
print("save csv ...")
results.to_csv(os.path.join(path_prefix, 'predict.csv'), index=False)
print("Finish Predicting")
save csv ...
Finish Predicting
# 统计预测的标签数量,负类与正类预测数量如下:
print(results.iloc[:,1].value_counts())
ge(len(pre_labels))
# 把预测结果写到csv
results = pd.DataFrame({"id":ID,"pre_labels":pre_labels,'predictions':predictions})
print("save csv ...")
results.to_csv(os.path.join(path_prefix, 'predict.csv'), index=False)
print("Finish Predicting")
save csv ...
Finish Predicting
# 统计预测的标签数量,负类与正类预测数量如下:
print(results.iloc[:,1].value_counts())
print(results.iloc[:,2].value_counts())
1 132522
0 67478
Name: pre_labels, dtype: int64
positive 132522
negative 67478
Name: predictions, dtype: int64
作者介绍
大家好,我是黄波波。希望能和大家共进步,错误之处恳请指出!
百度AI Studio个人主页, 我在AI Studio上获得白银等级,点亮2个徽章,来互关呀~
交流qq:3207820044


















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











