



KMP算法(全称Knuth-Morris-Pratt字符串查找算法,由三位发明者的姓氏命名)是可以在文本串s中快速查找模式串p的一种算法。
要想知道KMP算法是如何减少字符串查找的时间复杂度的,我们不如来看暴力匹配方法是如何浪费时间的。所谓暴力匹配,就是逐字符逐字符地进行匹配(比较s[i]和p[j]),如果当前字符匹配成功(s[i]==p[j]),就匹配下一个字符(++i, ++j),如果失配,i回溯,j置为0(i=i-j+1, j=0)。代码如下:
// 暴力匹配
int i = 0, j = 0;
while (i < s.length())
{
if (s[i] == p[j])
{
++i;
++j;
}
else
{
i = i - j + 1;
j = 0;
}
if (j == p.length()) // 匹配成功,打印结果并回溯
{
cout << i - j << endl;
i = i - j + 1;
j = 0;
}
}
举例来说,假如s="abababcabaa", 我们暴力匹配,过程会是怎样?
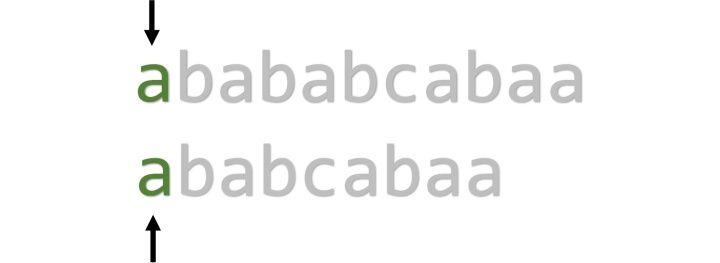
从头开始匹配,第一个字符是a,匹配成功。

第2~4个字符也匹配成功,继续。

下一位,匹配失败,回溯。
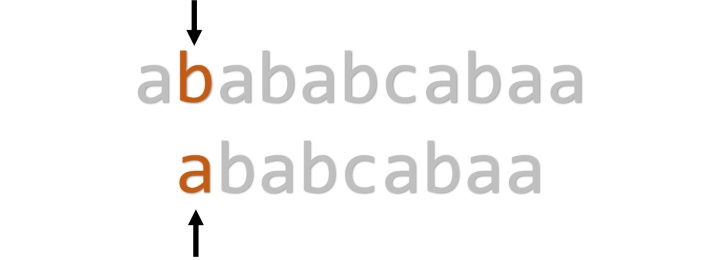
匹配失败,继续尝试。

下一位,匹配成功。

就这样一直匹配到结尾。
设两个字符串的长度分别为
j置为0,很可能会出现缺漏,如下图。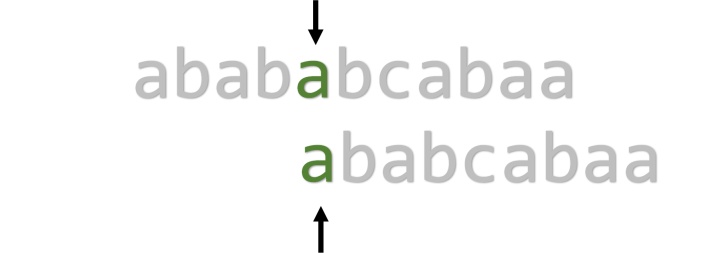
于是为了让j被赋为一个合适的值,我们引入了PMT(Partial Match Table,部分匹配表)。
j应该被赋值为多少,是只与模式串自身有关的。每个模式串,都对应着一张PMT,比如"ababcabaa"对应的PMT如下:

这是什么意思呢?简单地说,PMT[i]就是,从p[0]往后数、同时从p[i]往前数相同的位数,在保证前后缀相同的情况下,最多能数多少位。(但要小于p的长度)

专业点说,它是真前缀与真后缀的集合之交集中,最长元素的长度。(这里的“真”字与“真子集”中的“真”字类似)
为什么PMT可以用来确定j指针的位置呢?让我们先回到暴力匹配算法第一次失配时的情形:
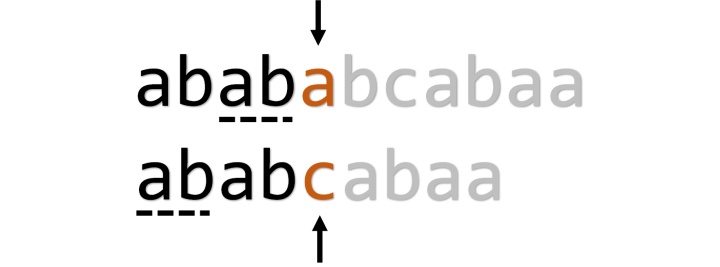
这时,s中的'a'与p中的'c'没有配上,我们计划保持i指针(上面的指针)不变,而把j指针左移。我们注意到,"abab"已经匹配成功了,它拥有一个前缀"ab",以及一个后缀"ab"(虚线部分),所以我们可以把这个"ab"利用起来,变成下面这样:

实际上这时我们正是在令j=pmt[j-1]。再举一个例子:
发生失配,我们令j=pmt[j-1](=3)(也就是符合条件的最长前缀所紧接着的下一位):
仍不匹配,我们继续:


这次取得了成功,继续匹配下去即得答案。
以上这些过程,转换为代码,是这样的:
for (int i = 0, j = 0; i < s.length(); ++i)
{
while (j >= 0 && s[i] != p[j]) // 失配,不断循环直到匹配成功。如果无论如何都无法匹配成功则得到-1
j = j ? pmt[j - 1] : -1;
++j; // 指针后移一位(如果匹配失败,相当于将指针置于字符串首)
if (j == p.length()) // 字符串匹配成功,打印结果并回溯
{
cout << i - j + 1 << endl;
j = pmt[j - 1];
}
}
很多文章中会使用next数组,即把PMT整体向右移一位(特别地,令next[0]=-1),表示在每一位失配时应跳转到的索引。也就是说,失配时,按照i -> next[i] -> next[next[i]] -> ...的顺序跳转。其实原理和实现都是差不多的。
现在问题来了,PMT怎么求?如果暴力求的话,时间复杂度是
p自己匹配自己(这相当于是用前缀去匹配后缀)。我们知道pmt[0]=0,而之后的每一位则可以通过在匹配过程中记录j值得到。还是以刚刚的模式串为例:
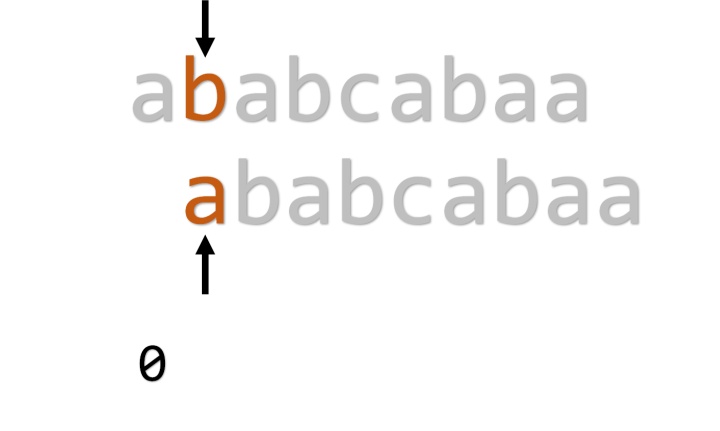
匹配失败,则pmt[1]=-1+1=0,i指针后移。

接下来匹配成功,可知pmt[2]=j+1=1,然后将两个指针都右移(其实为了代码简洁,可以先移动指针,即写成pmt[2]=++j)

继续匹配成功,pmt[3]=++j.

下一位失配,因为前面的pmt已经算出来了,我们可以像匹配文本串时那样地使用它。pmt[2-1]即pmt[1]等于0,所以退回到开头。

在开头处匹配失败,则pmt[4]=-1+1=0。接下来也按这种方法操作:

最后一位出现失配,这次我们先令j=pmt[j-1]=1:


再次匹配,匹配成功。自此,我们通过一趟自我匹配,求出了PMT,代码如下:
pmt[0] = 0;
for (int i = 1, j = 0; i < p.length(); ++i)
{
while (j >= 0 && p[i] != p[j])
j = j ? pmt[j - 1] : -1;
pmt[i] = ++j;
}
现在已经可以解决洛谷模板题了:
(洛谷P3375 【模板】KMP字符串匹配)
题目描述 如题,给出两个字符串和
,其中
为
的子串,求出
在
为了减少骗分的情况,接下来还要输出子串的前缀数组 next。 (如果你不知道这是什么意思也不要问,去百度搜 kmp算法 学习一下就知道了。) 输入格式 第一行为一个字符串,即为中所有出现的位置。
。 第二行为一个字符串,即为
输出格式 若干行,每行包含一个整数,表示。
在
中出现的位置 接下来 11 行,包括
个整数,表示前缀数组
的值。
#include <bits/stdc++.h>
using namespace std;
int pmt[1000005];
string s, p;
int main()
{
ios::sync_with_stdio(false);
cin >> s >> p;
pmt[0] = 0;
int cnt = 0;
for (int i = 1, j = 0; i < p.length(); ++i)
{
while (p[i] != p[j] && j >= 0)
j = j ? pmt[j - 1] : -1;
pmt[i] = ++j;
}
for (int i = 0, j = 0; i < s.length(); ++i)
{
while (s[i] != p[j] && j >= 0)
j = j ? pmt[j - 1] : -1;
++j;
if (j == p.length())
{
cout << i - j + 2 << endl; // 根据样例输出,这里要的是1-index数组,所以是加2
j = pmt[j - 1];
}
}
for (int i = 0; i < p.length(); ++i)
cout << pmt[i] << ' ';
cout << endl;
return 0;
}
(话说,说是输出next数组,其实要输出的是PMT…… )
上面的算法只能称作MP算法,真正的KMP算法还有一个Knuth提出的优化。
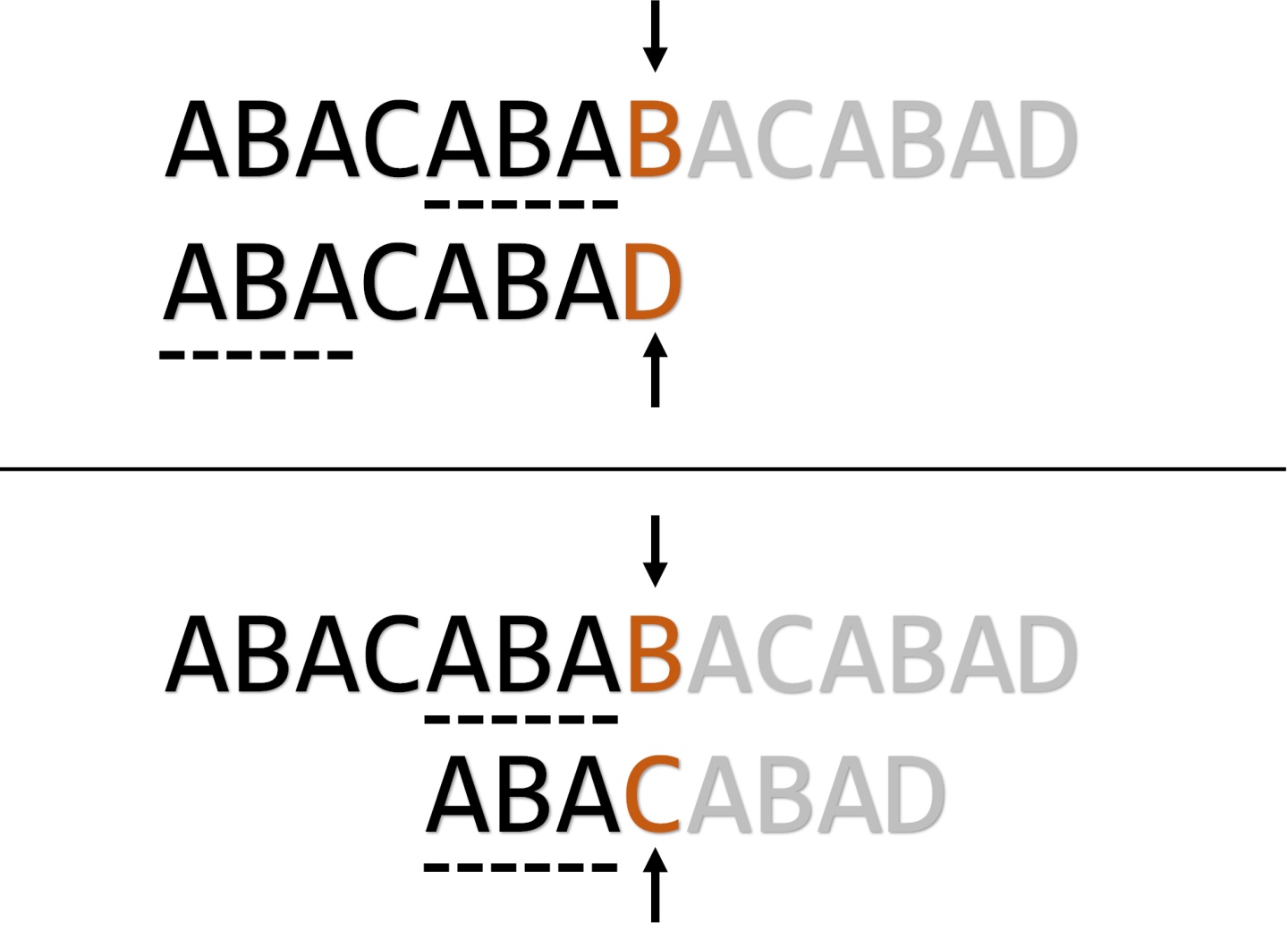
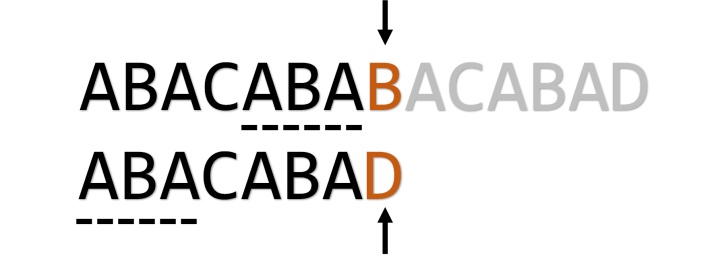
例如对于"abababc"这个模式串,如果我们用它来匹配"abababd",在最后处要跳转3次才能发现匹配失败:

其实中间这几次跳转毫无意义,我们明知道d和a是不能匹配的,却做了很多无用功。所以我们可以在计算pmt时做一点小改动 :
for (int i = 1, j = 0; i < p.length(); ++i)
{
while (j >= 0 && p[i] != p[j])
j = j ? pmt[j - 1] : -1;
pmt[i] = p[i + 1] == p[j + 1] ? pmt[j++] : ++j;
}
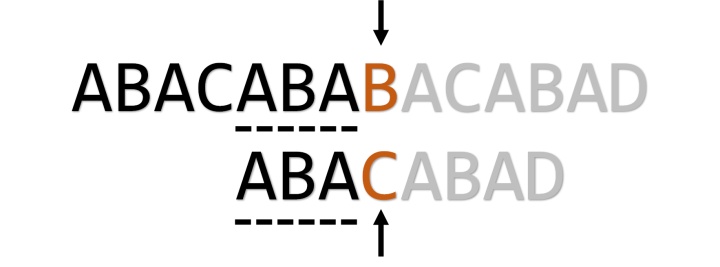
这是什么原理?如下图,这时自我匹配成功了,第i+1位在失配时按理会跳转到第j+1位,但是我们发现第i+1位和第j+1位的字符是一样的。我们知道第j+1位失配后会跳转到第pmt[j+1-1]即pmt[j]位,所以我们干脆跳过j+1直接到pmt[j]去。(注意这里是递推的)

相反,匹配到下图这种情形时,p[i+1]!=p[j+1],就可以像之前那样处理。
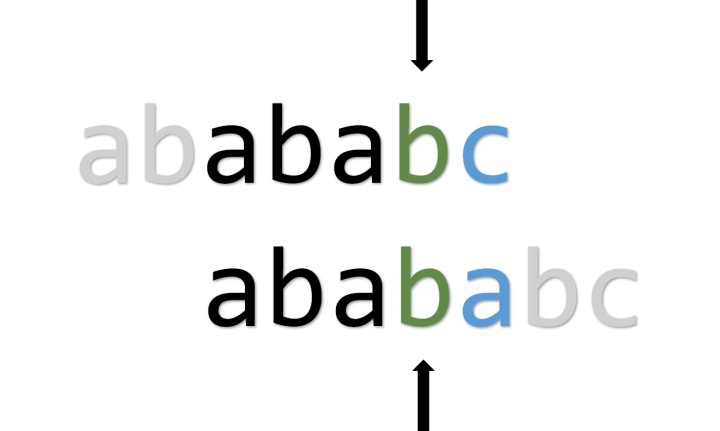
其实这样得到的pmt数组已经不符合我们定义的PMT的性质了,如果较真的话可以重新拿一个名为nextval之类的数组存。
KMP算法总的时间复杂度是
++i和++j都只进行了 j在过程中有减小,但j在任何时刻不可能小于 j减小的次数也不可能超过 Pecco:算法学习笔记(目录)zhuanlan.zhihu.com

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









