






1. 接口使用不当
1)GLES中的glAAx 形式的接口使用,glTranslatex,glRotatex,glScalex等函数。
float posx = 100.0f, posy = 100.0f, posz = 100.0f;
glTranslatef(posx, posy, posz);
//等价于
int fpX = (int)(posx * 65536), fpY = (int)(posy * 65536), fpZ = (int)(posz * 65536);
glTranslatex(fpX, fpY, fpZ);
2. GLEnum使用不当
1)离线渲染框架中,通过帧缓存测试绘制任意凹凸多边形,framebuffer中设置帧缓冲区很隐晦:
错误做法:为深度缓冲区创建一个GL_DEPTH_COMPONENT24格式的RenderBuffer;为模板缓冲区创建一个GL_STENCIL_INDEX格式的RenderBuffer。
正确做法:模板、深度 共用一个RenderBuffer,而且格式是GL_DEPTH24_STENCIL8。具体参见:http://www.linuxidc.com/Linux/2014-03/98792.htm
2)获取模型视图矩阵用GL_MODELVIEW_MATRIX而不是GL_MODELVIEW,获取投影视图矩阵用GL_PROJECTION_MATRIX而不是GL_PROJECTION;
涂点用GL_POINTS而不是 GL_POINT;画线用GL_LINES而不是GL_LINE。GL_POINT、GL_LINE、GL_FILL 用来指定多边形填充模式。
BTW:Android中比较怪,java层gles1.0没法直接查询变量的值,native层gl.h可以。java层GL10中没有查询数据的GLenum和接口函数,GL11中有;android-ndk-r7c\platforms\android-8\arch-x86\usr\include\GLES\gl.h 比较全面。
3. 隐晦的逻辑问题
1)绘制过程开启了GL_CULL_FACE,建模过程中三角形顶点顺序为CW导致绘制无结果。默认是GL_CCW
调试方法:修改多边形填充模式GL_LINE确认图形轮廓线是否绘制成功;或者禁掉背面剔除:glDisable(GL_CULL_FACE);
解决方法:glFrontFace( GL_CW / GL_CCW )修改默认配置。
2)关闭深度测试,导致混合失效??
3)深度缓冲区溢出
Android GLSurfaceView默认采用16bit的深度缓冲区,精度在0-65536,参见:http://www.linuxidc.com/Linux/2014-03/98791.htm
public void setRenderer(Renderer renderer) {
checkRenderThreadState();
if (mEGLConfigChooser == null) { // here
mEGLConfigChooser = new SimpleEGLConfigChooser(true);
}
if (mEGLContextFactory == null) {
mEGLContextFactory = new DefaultContextFactory();
}
if (mEGLWindowSurfaceFactory == null) {
mEGLWindowSurfaceFactory = new DefaultWindowSurfaceFactory();
}
mGLThread = new GLThread(renderer);
mGLThread.start();
}
/**
* This class will choose a RGB_565 surface with
* or without a depth buffer.
*
*/
private class SimpleEGLConfigChooser extends ComponentSizeChooser {
public SimpleEGLConfigChooser(boolean withDepthBuffer) {
super(5, 6, 5, 0, withDepthBuffer ? 16 : 0, 0);
}
}
4)android中不同资源目录导致纹理资源被隐式修改:2幂次的纹理放在drawable目录下,在高分屏android机器上从drawable中加载纹理资源后进行1.2倍隐式扩充,导致纹理不再是2的幂次。http://www.linuxidc.com/Linux/2014-03/98793.htm
4. gl状态
1)上次适配AntTweakBar GLES时,它库中EndDraw函数结束绘制时将当前矩阵堆栈设为TEXTURE_MATRIX,下次进入渲染函数时在BeginDraw中各种尝试修改模型视图失效实际修改的都是纹理矩阵,glGetError返回也为0。
2)批量绘制地图上路网数据, 阈值达到一定程度,随机性crash!
调试:glVertexPointer上传顶点,禁掉VertexArray,ColorArray,TextureArray后调用glDrawElements不会crash,说明问题出在上面这三个状态设置,进一步检查发现上传顶点中只有位置和颜色,但是GL_TEXTURE_ARRAY没有禁掉。所以才会出现随机性crash。
5. 性能Tips
1)纹理打包,避免使用小纹理;可以一定程度实现批处理。
TextureAtlas思想,一系列Icon静态打包到一个资源中,通过纹理坐标索引不同的资源。纹理烘焙思想。
2)避免纹理动态申请、释放,地图渲染中涉及大量的瓦片,而且他们的格式和尺寸都一致。旧做法:glTexImage2D创建纹理,淘汰瓦片时glDeleteTextures删除瓦片纹理。改进后的做法:淘汰瓦片时glTexSubImage2D用新的瓦片内容替换就瓦片显存内容。
3)顶点数据批量上传,batch batch batch,尽可能减少opengl 函数调用次数,draw calls
需求:100个item缩放动画
// 所有item同步做动画
glScale(scalex, scaley, scalez);
batch_draw_100_itmes();
// 不同步动画
// V1 通过opengl做动画
for (int cursor = 0; cursor < 100; cursor++)
{
glScale3fv(items[cursor].scaleVar);
items[cursor].single_draw_item();
}
// V2 CPU对顶点进行计算,然后批量绘制
for (int cursor = 0; cursor < 100; cursor++)
{
cpu_scale_vertices(items[cursor].scaleVar);
}
batch_draw_100_items();
当每个item动画个异步执行时,V1的实现item缩放过度依赖于opengl,而且没法实现批处理! V2牺牲点CPU计算性能换来GPU的批量绘制。
改进:cpu_scale_vertices操作可以单独在update线程中执行, batch_draw_100_items在GL绘制线程中。
4)一帧绘制中,FBO不能切换过频繁。做路况渲染中,为每个256*256的瓦片建立一个FBO,FBO直接与纹理关联;每帧可能绘制3-5个瓦片,即进行3-5次FBO切换。实测发现FBO切换开销远大于数据上传OpenGL的开销。
5)一些非常耗性能操作:
通过glReadPixels获取帧缓存区内容,导致GPU中断,效率非常低。网上有一种PBO异步方式获取帧缓存的做法效率不错,适合PC。
通过glCopyTexImage2D将帧缓区内容拷内到纹理,会导致渲染中断,如下图十分耗时。替代做法:将纹理与FBO绑定,直接渲染到纹理,RTT。
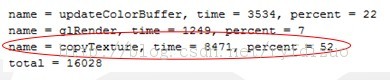
大纹理切换开销也十分大,手机端一般别超过1024*1024,不同手机支持纹理最大尺寸可以通过接口查询。
相关阅读:















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









