






在数据分析领域中,用到最多的包是numpy(用于数学计算)、pandas(基于numpy的数据分析工具,方便对表的数据结构进行分析)和matplotlib(图形绘制库,用于数据分析结果的可视化)。本文首先了解下Numpy和pandas在数据分析中的一些基本操作。
本文结构如下:
一、一维数据分析
二、二维数据分析
三、案例:销售数据分析
一、一维数据分析
Numpy中表示一维数组的是array,pandas表示一维数组的是Series。Series是建立在numpy基础上的,比array有更多的功能。使用这两个数组首先用import导入numpy和pandas这两个包。
(一)Numpy 一维数组array
- 定义一个数组:

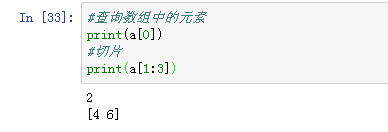
- 查询访问array中的元素:
- 通过for i in 数组名遍历数组中的元素:

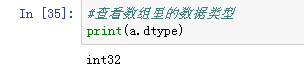
- 通过数组名.dtype查看数组中元素的数据类型:
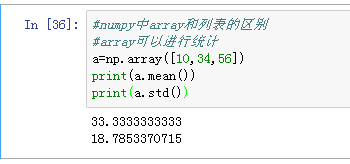
Numpy数组array和列表的区别:
1、array可以进行统计功能,如求平均值mean(),标准差std()
2、array可以进行向量化运算(相加、乘法)
查看下图中array和列表相加结果的区别。

3、array中元素必须是同一种数据类型,列表中的元素可以是不同数据类型。

如图,虽然数组array1中的元素1和3看起来是数据类型,但是在打印出来之后,1和3都作为字符串类型了。而列表list1中的1和3打印出来是数据类型。
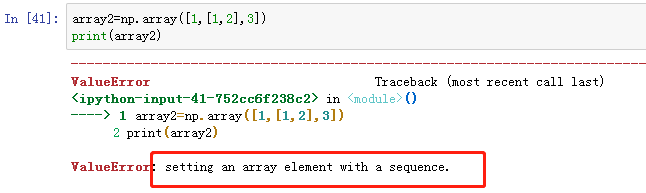
上图array2中的元素包含列表和字符串,两种数据类型不相同,在打印的时候就会报错,如果将1和3也改成列表,就可以打印了:
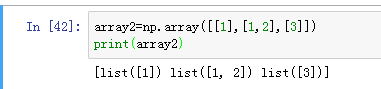
可以看到array2里的元素是3个列表。
(二)pandas 一维数组Series
- Series和array的主要区别是Series可以通过索引定位数组中的数据。在定义的时候通过index定义索引。

要注意这里的Series首字母应大写,不然会报错。而定义array的时候首字母不用大写。Series后面接小括号,小括号前半部分是列表形式的元素,后半部分是用index=[]指定每个元素的索引,方便以后通过索引访问其中的元素。
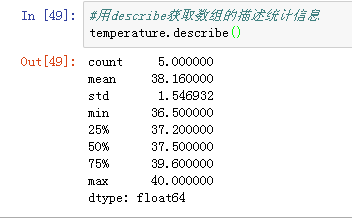
- 可以通过describe获取数组的描述统计信息(元素个数,平均值,标准差,四分位数,最大最小值),数组名.describe():
- 获取数组中的元素:
方法一:用iloc属性根据位置获取元素

方法二:用loc属性根据索引获取对应的元素

- Series向量运算:
1、用加号+直接相加,索引值相同的元素才会相加,只出现在一个数组里的索引相加之后的值为空值。
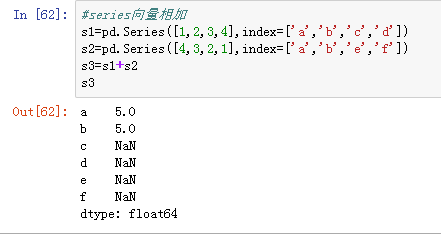
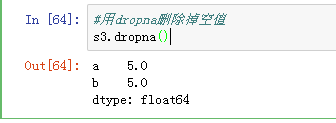
在数据分析中,可以通过Ser.dropna()删除掉空值。
2、用add将两个数组相加,并用fill_value指定一个数据来填充缺失值。下面两个图展示了用0和1分别进行填充,比如’c’在s1中,但s2中没有’c’,就用0填充s2中的’c’


二、二维数据分析
相比于一维数据,二维数据既有行也有列,相当于Excel里的表格。
Numpy中通过array创建二维数组,pandas中通过DataFrame(数据框)创建二维数组。
- numpy创建二维数组
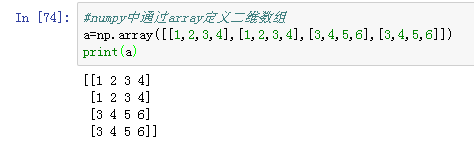
通过array创建二维数组,用中括号包括起来,中括号里面是中括号(列表)包括起来的每一行数据,列表之间通过逗号隔开。每个列表中元素个数代表列个数。
- 查询和获取元素:
查询二维数组中的元素,通过行号和列号查找,二维数组的行列号都是从0开始的,数组名.[a,b],其中a代表行号,b代表列号:
查询其中一个元素:

获取第一行(切片功能‘:’):

获取第一列(切片功能‘:’):

- numpy二维数组描述统计
如果直接使用sum(),mean()统计数组,得出的是包含所有元素的描述统计信息。如:

但在实际数据分析中,对于一个二维表格,通常行列是不同类型的数据,一般不会统计所有元素的描述统计信息,只需要统计某些列/行的描述统计信息,这时可以在函数后面加axis指定行列计算,即为numpy的数轴参数,这种方式叫做按轴计算。其中axis=1代表按行计算每行的描述统计信息,axis=0代表按列计算。

Numpy一维数组中的元素必须都是同一类型,同样的,二维数组中的元素也必须都是同一类型,但对于表述Excel中的数据,就不适用了,因为Excel中每列的数据类型一般都不一样。这时就需要用pandas中的二维数组dataframe数据框。
(二)pandas创建二维数据
Pandas二维数组相比numpy二维数组有两个优点:
- 数据框的每一列都可以是不同类型的数据,方便表示Excel中的数据。
- 有类似pandas中series里的索引功能,即二维数组的每行每列都有一个索引值,很适合用来存放表格数据。
- 创建一个二维数组,首先通过键(列名)值(列名对应的值)对创建一个字典,再用pandas中的dataframe将字典转换成二维数组。
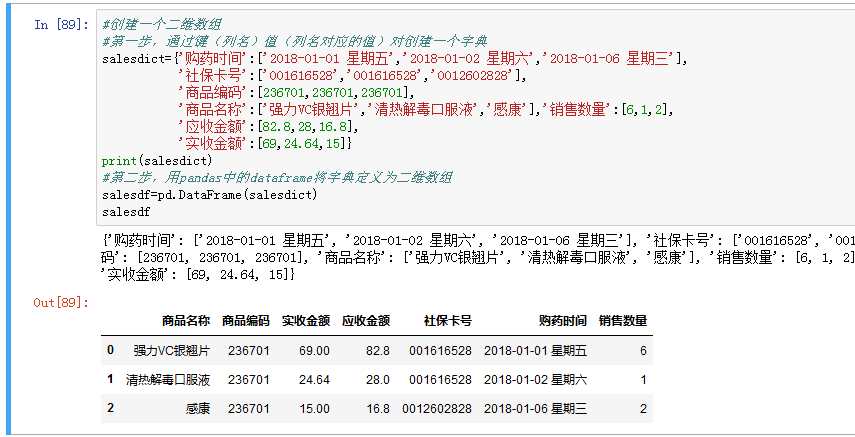
上图中可以看出数组中的列顺序与定义字典时的顺序不一致,为了更好的展示原数据结构,可以通过有序字典OrderedDict先对字典排序,再转换成数组,见下图:
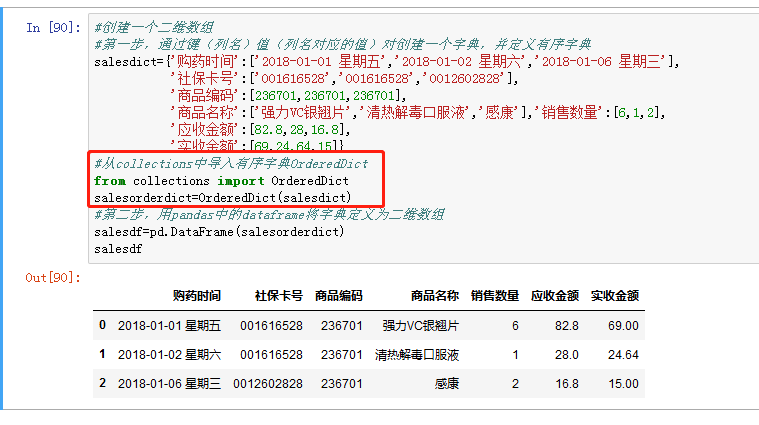
- 求平均值
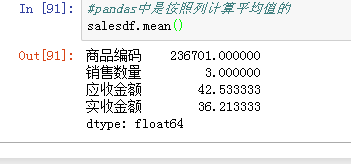
由于数据框中每一列数据类型不同,在计算平均值时,pandas是按照每列计算平均值的,而且只是对数据类型是数值的列计算平均值。数组名.mean()
- 查询获取数据框中的数据
方法一:iloc,是根据元素的位置查询的
查询元素:数组名.iloc[a,b] ,a,b为元素的位置
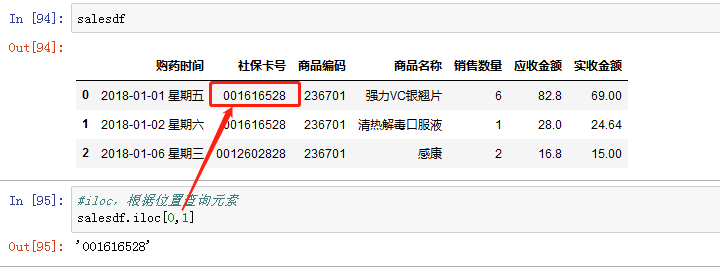
获取某一行:数组名.iloc[a,:] ,a为行号
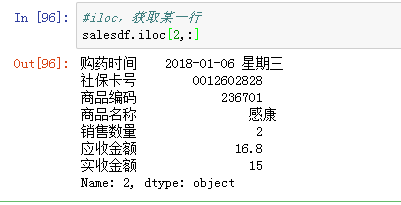
获取某一列:数组名.iloc[:,b] ,b为列号

方法二:loc,是根据元素的索引查询的
在数据较多的时候,查找行号和列号不太方便,这时可以用loc属性,通过索引来查询元素。查询元素,数组名.loc[a,b],a、b为索引值:
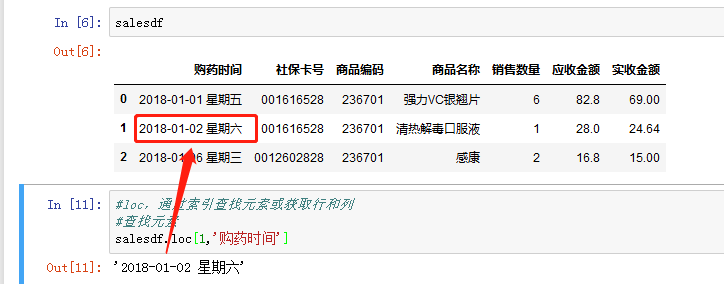
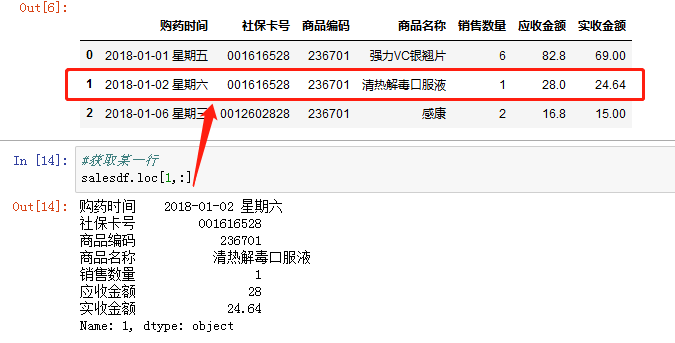
获取某一行,数组名.loc[a,:] a为索引(在本例中行的索引默认为行号)
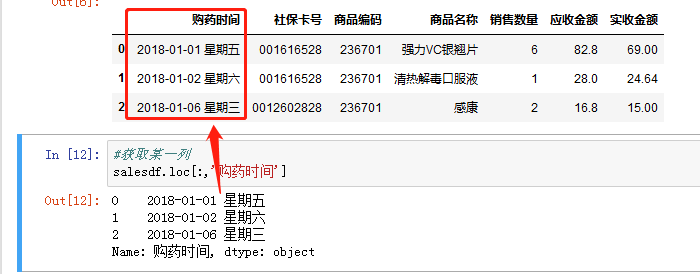
获取某一列,通过切片功能,数组名.loc[:,’b’] b为列名:
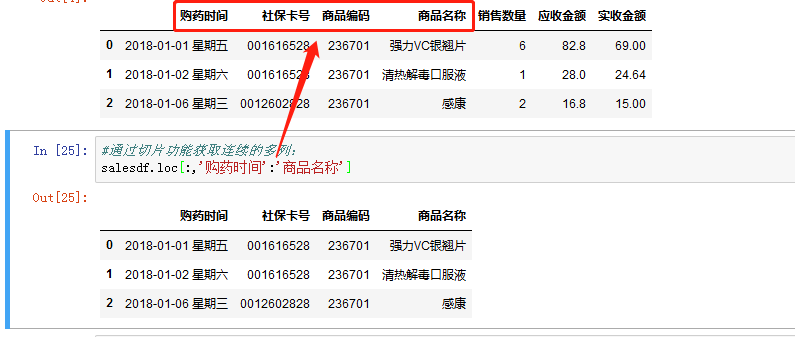
如果获取连续的多列,可以使用切片功能,数组名.loc[:,列名1:列名2]:
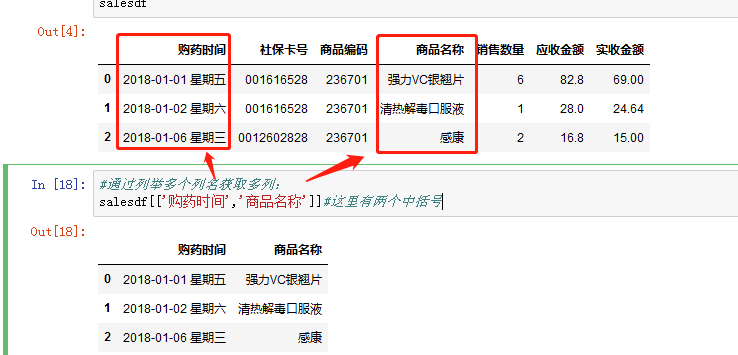
获取某一列的简单方法是直接在数组名后面的方括号中给出列名即可,数组名[‘列名’]:
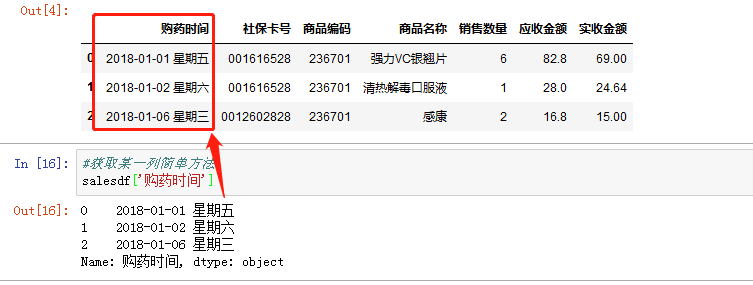
也可以在后面列出多个列名,获取多列(不连续),数组名.[[列名1,列名2]],注意是方括号里加了指定列名的列表(两个方括号):
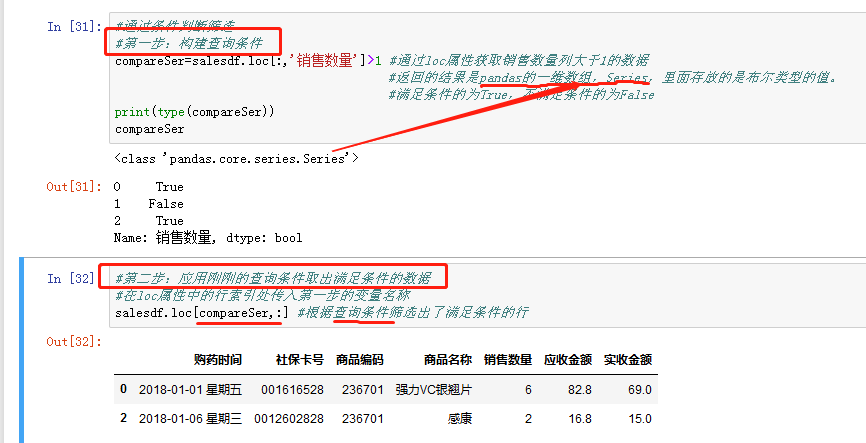
- 通过条件判断筛选
有两步,第一:构建查询条件 第二:应用查询条件
- 数据框还可以查看数据集里的描述统计信息
首先通过pandas的ExcelFile功能读入Excel文件:

要注意文件路径中应为,不然会报错:

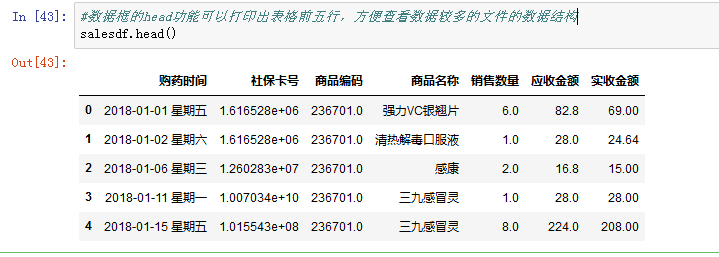
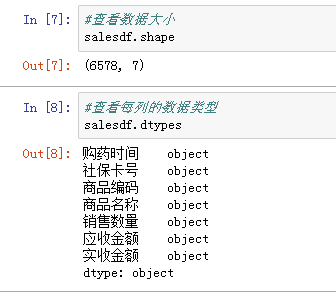
- 在数据较多时,可以通过数据框的head()功能查看前五行数据,了解表格结构:
- 可以通过loc属性和dtype查看某一列的数据类型:

- 通过shape属性,可以查看数据框有多少行多少列:

接下来可以用describe获取数据集的描述统计信息(每一列的总数、平均数、标准差、四分位数):
三、案例:销售数据分析
数据分析的过程:
- 提出问题:数据分析的目标是为了解决生活和工作中的问题,明确问题可以为以后的分析提供大的方向和目标
- 理解数据:包括采集数据(根据问题采集相关数据)、导入数据(Excel中,数据库中,接口中,需要导入到pandas中)、查看数据信息(从整理上理解数据,比如描述统计信息)
- 数据清洗:数据预处理。
- 构建模型:对清洗后的数据进行分析,得出指标或者用机器学习算法训练模型
- 数据可视化:将得出的结果用图表表示出来
以下通过一个实例展示怎么用Python进行数据分析。
- 提出问题
有一份医院的药品销售数据,需要知道以下业务指标是多少?
- 月均消费次数
- 月均消费金额
- 客单价
- 消费趋势
如果对提出问题部分中的业务指标含义不理解,可以先上网搜索含义,如果找不到,再向提供数据的部门进行询问。
2.理解数据
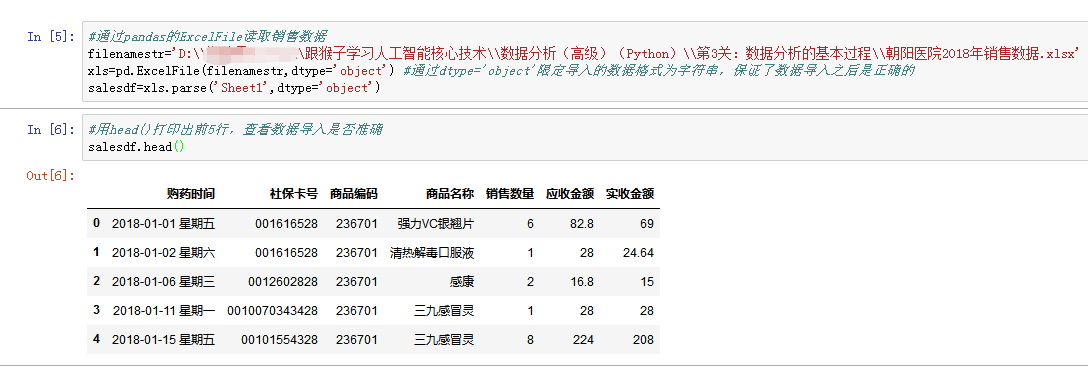
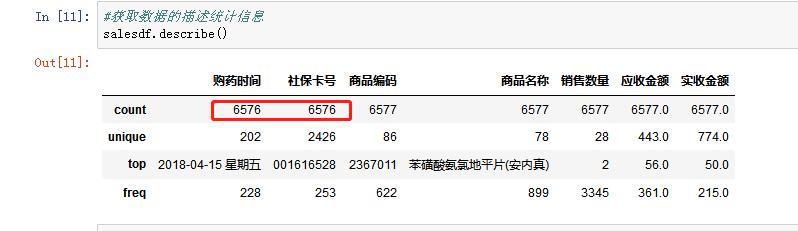
首先用pandas的ExcelFile方法将销售数据文件读取到数据框中,为了保证某些列的数据在读取之后保持正确,可以用dtype=’object’使导入的数据都是字符串格式,并用head()打印出前5行,查看数据导入是否正确,都有哪些数据,以便了解原数据的特点(比如应收金额是药品原价,实收金额是打折优惠之后的价格),通过describe()了解数据的描述统计信息。
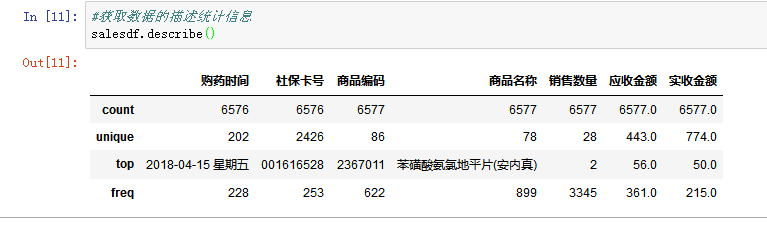
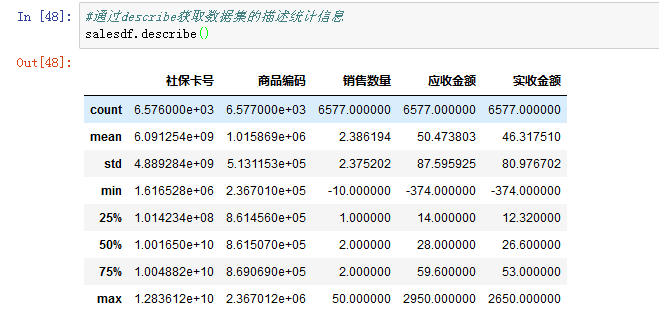
上图中的describe()方法,得出的结果的索引是count(非空值数),unique(唯一值数),top(频数最高者),freq(最高频次)。
通过描述统计信息可以看出,
- 购药时间的计数一共是6576个,而数据框大小的结果是6578行,说明有2行的购药时间为空值。统计时间一共202天,在2018年4月15日这一天销售次数最多,达到了228次。
- 一共有2426名患者有购药记录,其中社保卡号为001616528的患者购买次数最多,达到了253次。
- 售出的药物一共有78中,购买频次最多的是苯磺酸氨氯地平片(安内真),有899次的购买记录。
- 有3345次药品购买数量都是2。
Pandas中的describe()方法说明:
在本文第二部分二维数据分析中(见下图),我们也使用了describe()方法,但是当时的结果的索引值是count,mean,std,四分位数。这是因为第一次我们导入数据的时候,由于我们没有限定导入数据的类型,社保卡号、商品编码、销售数量、应收实收金额都以数值的形式导入了,describe()在默认情况下是对数值型的列进行统计,所以统计了刚说的5列,而购药时间、商品名称没有统计到。在第二次使用describe()时,因为我们在导入数据时限定了都以字符串的形式导入(dtype=’object’),数值型数据的描述统计结果索引不适用字符串数据,所以字符串描述统计结果是count,unique,top,freq。
3.数据清洗
数据清洗的目标是把数据处理成易于分析的样子,便于后续的探索和分析。
数据清洗的过程:
- 选择子集:选择我们需要的列作为研究的对象
- 列名重命名:列名不符合阅读习惯,不便于书写理解时,进行列名重命名
- 缺失值处理:对空值进行处理
- 数据类型转换:将应是数值类型的数据从字符串类型转换为数据类型。
- 数据排序:排序有助于发现更多有价值的东西
- 异常值处理:数值太大、太小,超出定义的范围,需要进行处理
- 选择子集:
可以通过loc的切片功能从数据框中选择子集,本文要分析所有的数据,不用选择子集,但通过以下代码了解下怎么选择子集。
选取指定连续的列,通过loc的切片功能:
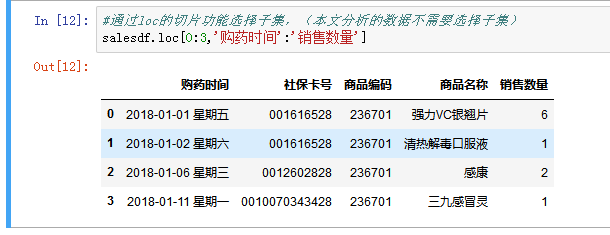
选取不连续的列:用loc属性,里面包含要选取的列名组成的列表:

- 列名重命名
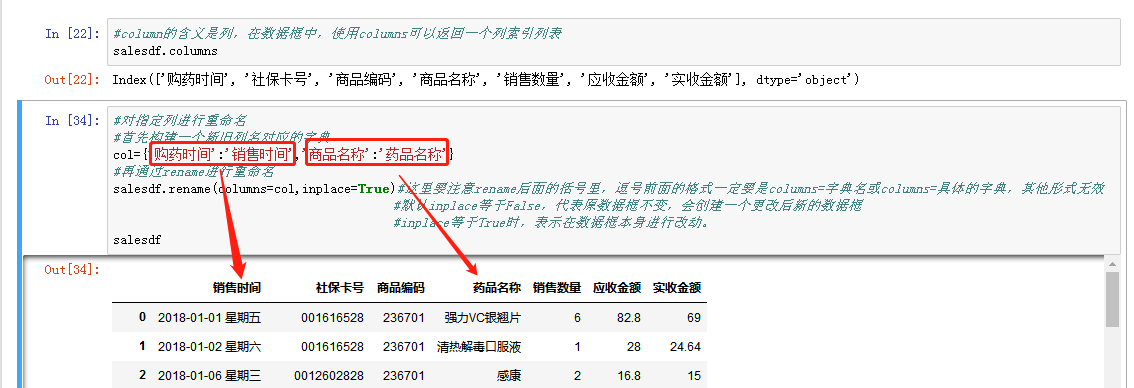
使用columns和rename进行指定列重命名。
在数据框中使用columns可以返回一个列索引的列表,先用columns构建一个新旧列名对应的字典,再通过rename进行重命名。
这里要注意rename后面的括号里,逗号前面的格式一定要是columns=字典名或columns=具体的字典,其他形式无效;
默认inplace等于False,代表原数据框不变,会创建一个更改后新的数据框,inplace等于True时,表示在数据框本身进行改动。
- 删除缺失值
如果缺失值较少,可以删除缺失值,如果缺失值太多,可以通过建立模型,通过插值补充缺失值。本文因为缺失值较少,直接删除。

在第2步理解数据中,我们得到了数据框的描述统计信息,里面的购药时间,社保卡号的非空值数都小于6578,说明有缺失值存在。
按销售实际情况分析,购药时间和社保卡号不能有缺失值,故将这两列含有缺失值的行删除掉。用dropna删掉,要配合subset,how,inplace,axis一起使用
- subset:list,表示在哪些列中查看缺失值,
- how='any'与省略掉的默认的axis=0配合使用,表示如何删掉缺失值:any表示只要有缺失值,就删掉对应行。
- inplace=False,表示将修改后的数据框新建一个
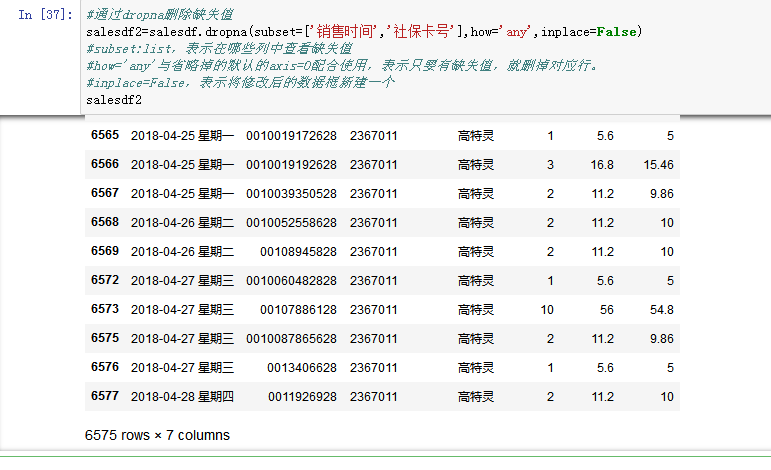
从上图可以看到删除缺失值之后剩余6575行了。
- 转换数据类型
销售数量,应收实收金额应为数值类型数据,通过astype进行转换。


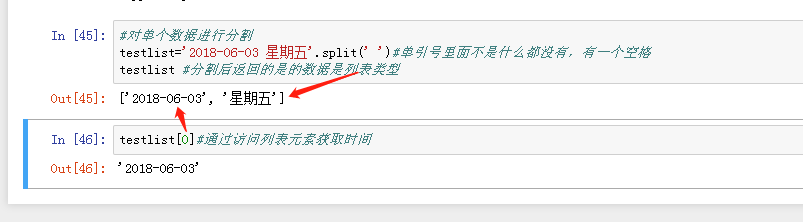
销售时间原来为日期加星期,通过字符串分割(split(‘分隔符’))拆分(选取列表指定元素)出日期,首先看一下怎么对单个日期进行分割:
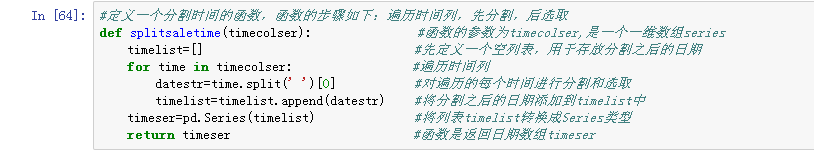
如果要对销售时间这一列进行分割,就需要列中的每个元素进行上述步骤,可以通过定义一个分割时间的函数。
接下来对取出销售数据中的销售时间列,并应用函数:
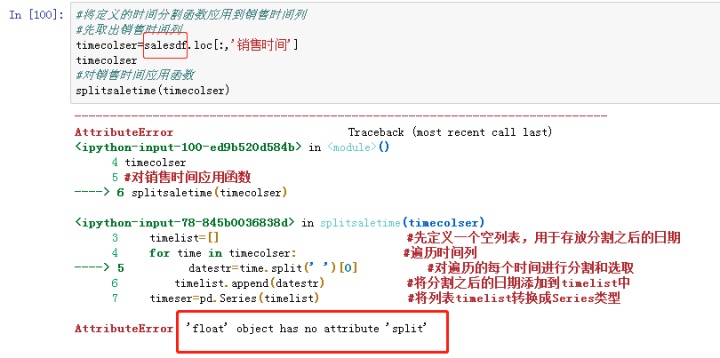
这里出现了报错:浮点型对象没有split属性。报错的原因是因为取得是salesdf中的销售时间,里面是有两个空值NaN(属于浮点型)。在第3步删除缺失值的时候,我们使用的dropna()里的inplace=False,表示将修改后的数据框新建一个:

所以新建的salesdf2里才没有空值,而salesdf里保留着空值。所以应从salesdf2中取出时间列进行分割:

再将分割之后的日期替换原来的销售时间:
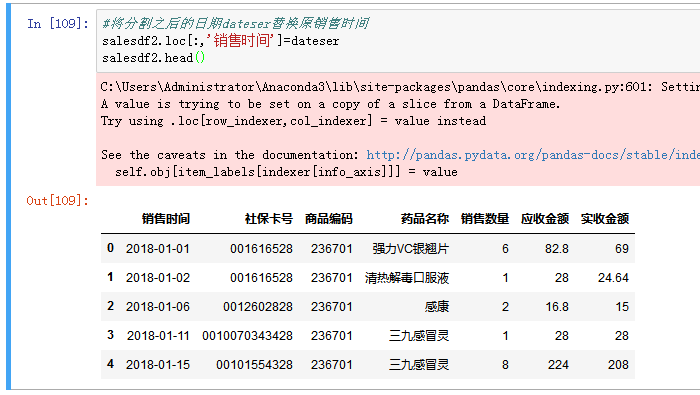
这里的销售时间在导入和分割之后都保持字符串的格式,应把其变为日期格式,用pandas里的to_datetime进行转换。
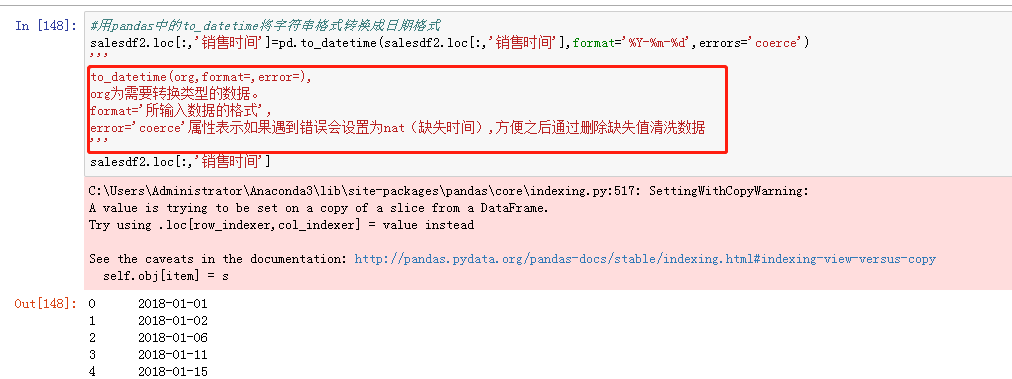
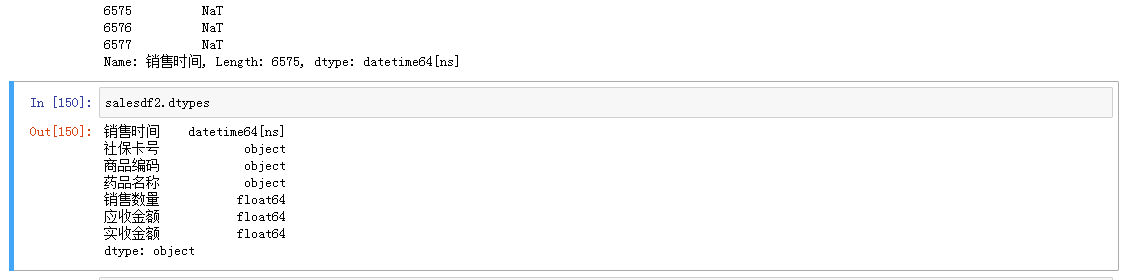
可以看到转换之后的数据格式为datetime64,错误值都被空值NaT填充了。
再用dropna()将缺失值删掉:
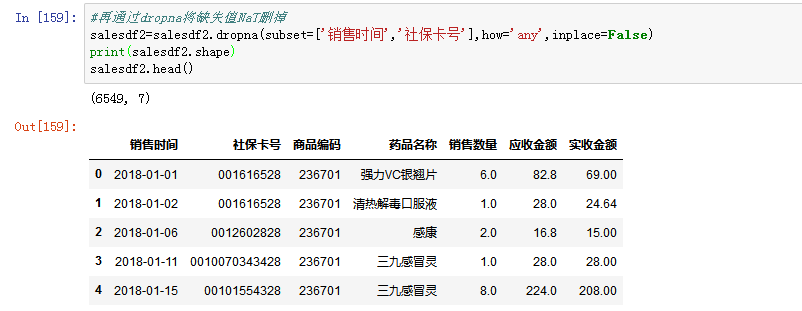
- 排序
为了方便分析和看到更多有用的信息,我们对销售时间进行排序.
用df.sort_values(by='列名', axis=0(默认为0,按列排序), ascending=True(升序排序), inplace=False(默认新建表))
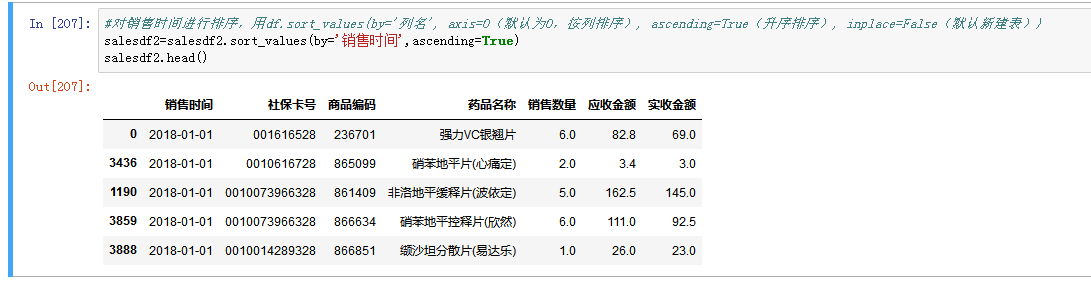
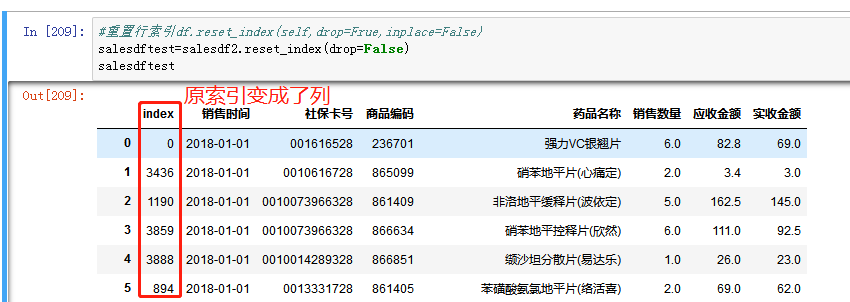
可以看到排序之后的行索引比较乱,为了方便以后根据行号查询数据,将行索引进行重置,即从0到N-1的整数升序排列。
用df.reset_index(self,drop=True,inplace=False),drop等于True时,表示删除原索引,用新的索引替换。为False时,表示将原索引转换为列,同时新的索引替换原索引位置。本文使用drop=True。
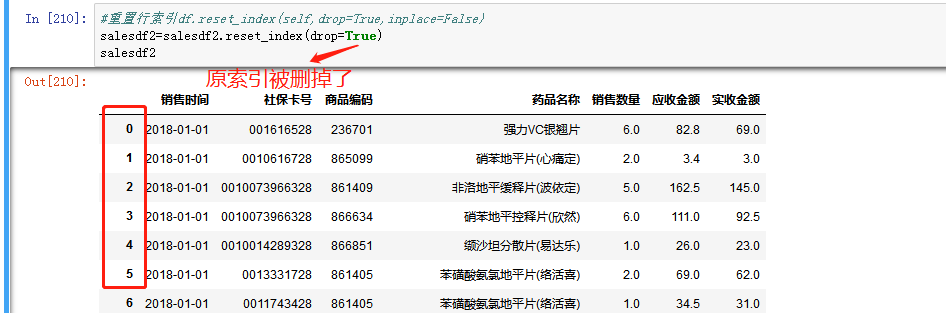
- 异常值处理:
截止目前数据清洗的工作已完成大部分,接下来用df.describe()方法获取数据框的描述统计信息,从整体上了解数据集信息,并查看是否有异常值。
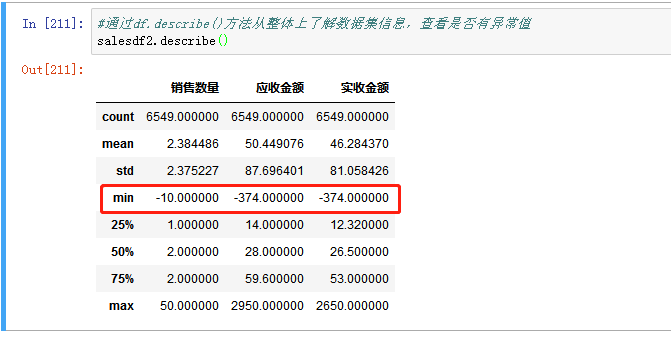
可以看到这三列的最小值都是负数,为异常值,销售数量为负数造成了金额为负数,应将销售数量小于0的删掉。
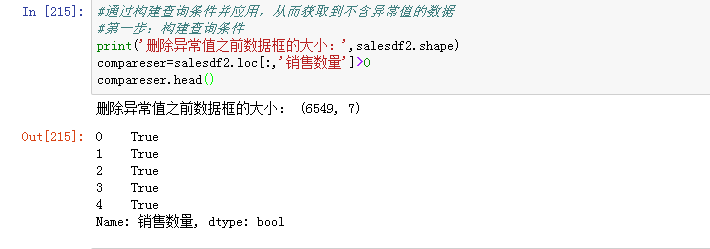
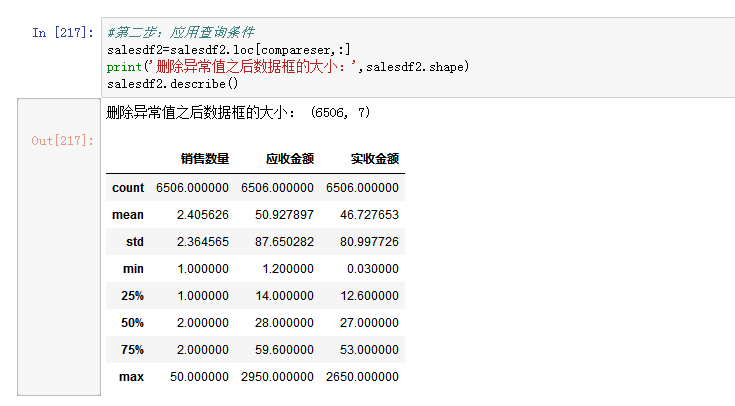
到此数据清洗的工作已完成。
4.构建模型
本部分内容为计算出提出问题部分的四个指标。
- 月均消费次数
- 月均消费金额
- 客单价
- 消费趋势
- 月均消费次数
月均消费次数=总消费次数/月份数(本文将同一天内一个人的多条消费记录一起看做一次消费)
首先计算总消费次数,应将销售时间和社保卡号都一样的重复数据删除,通过df.drop_duplicates(subset=[列名1,列名2],keep='first',inplace=True)
- subset表示将选取的列对应值相同的行进行去重
- keep=’fisrt’为默认值
- first表示保留第一次出现的重复行
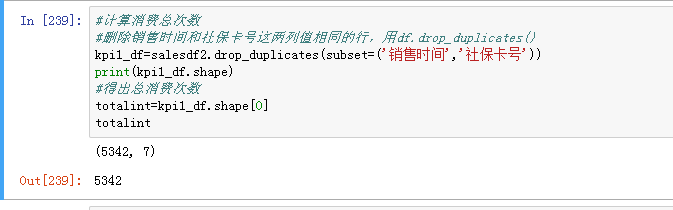
去重之后一共5342行,即总消费次数=5342。
计算月份数的思路:先计算按天计算的时间跨度,再除以30得出月份数
将kpi1_df的销售时间按升序排列,得到最早最晚的销售时间:

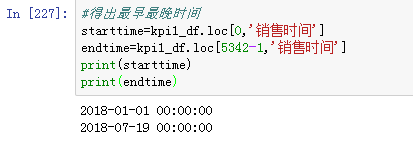
计算时间间隔,并除以30得出月份数,计算指标1:

得出指标1月均消费次数=890。
- 月均消费金额
月均消费金额=总消费金额/月份数

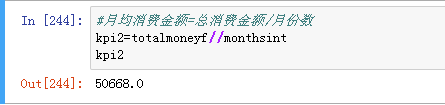
指标2月均消费金额为50668元
- 客单价
客单价=总消费金额/总消费次数
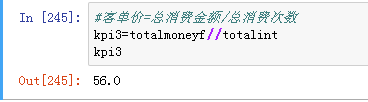
指标3客单价为56
- 消费趋势
需要用到pandas里更高级的功能和可视化内容,之后的文章再进行实操~














 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









