





参照论文:http://proceedings.mlr.press/v37/kusnerb15.pdf
论文论述了使用word embedding(词向量或者叫词嵌入)来计算文档距离在准确率上的优点,于是提出了用WMD算法来计算文档的距离。但WMD这个方法计算复杂度太高,于是作者提出了WCD,RWMD两种近似算法来加速计算文档距离。
1.概述
最通常表示一个文档的方法有BOW(bag of words, 词袋模型),TF-IDF(词频-逆向文档频率模型)。其共同特征是统计一个单词在一篇文档中的使用频率。
1.1BOW:
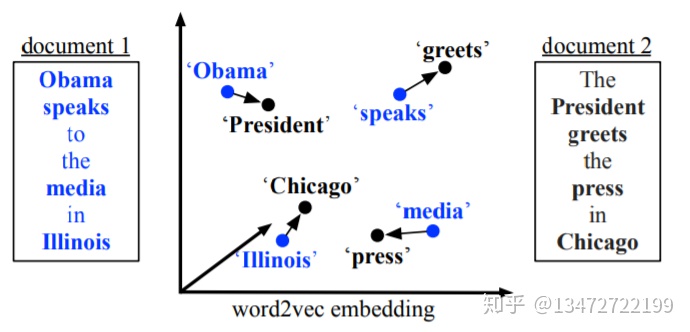
下面是两个文档的例子:
1. Obama speaks to the media in Illinois
2. The President greets the press in Chicago
步骤:
- 删除停用词
1. Obama speak media Illinois
2. President greet press Chicago
- 建立词典(key, index)
{'Obama':1, 'speak':2, 'media':3, 'Illinois':4, 'President':5, 'greet':6, 'press':7, 'Chicago':8}
- 对每个文档进行词频统计(index, count)
- {1:1, 2:1, 3:1, 4:1, 5:0, 6:0, 7:0, 8:0}
- {1:0, 2:0, 3:0, 4:0, 5:1, 6:1, 7:1, 8:1}
- 表示文档向量
- [1,1,1,1,0,0,0,0]
- [0,0,0,0,1,1,1,1]
但这个两文档向量由于正交而不适合表示它们之间的距离。
1.2TF-IDF
tf-idf模型的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。
计算tf计算公式:
w是某个单词, d是文档,
D是所有文档集来说,n是总文档数,
tf-idf可以衡量一个检索文章串q:
假如计算(停用词首先要除掉后计算)
q:1. Obama speaks to the media in Illinois
d: The President greets the press in Chicago,
计算为0值,不能看出它们有什么相似度。
LSI,LDA等技术试图用一个低维度表示潜在的语义来表示一个文档,由于它们只是BOW和TF-IDF的变体,因此它们在文档距离计算上难以取得绝对的优势。
1.3 WMD (word mover's distance)
本论文提出了单词搬运距离的思想,这个思想借鉴了一种word embedding技术word2Vec。word2vec生成的word embedding证实了一种语义的相关性。相近的单词的word embedding表征在空间中也是距离比较近的关系。WMD是将文本文档表示为嵌入词的加权点云。 两个文本文档A和B之间的距离是文档A中的单词需要行进的最小累积距离准确匹配文档B的点云。
WMD的好处:
- 不需要超参数,理解直接和使用
- 可解释性强
- 融合word2vec使高的检索准确率
2.WMD
把每个词通过embedding成一个m维向量,所有词向量矩阵
2.1 nBOW文档表示方式
每个文档d是使用词袋模型表示:
一些说一个文档记为这种nBow表示的文档。
2.2 Word travel cost
两个单词在word embedding空间的距离记为:
2.3 文档距离
设两个文档
那么两个文档之间的距离定义为如下式:
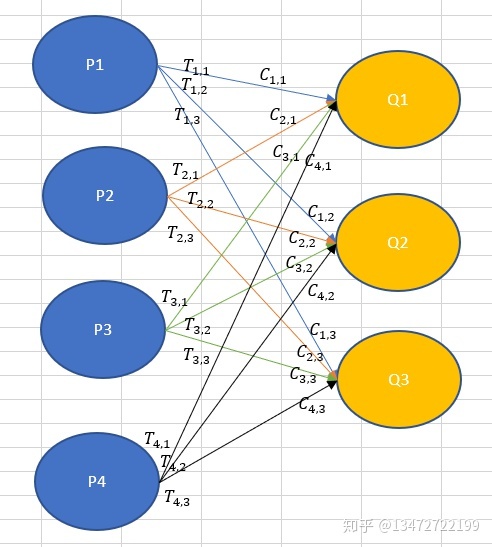
2.4 Transportation problem
把文档转化借鉴运输问题的思想,运输问题描述为:
生产地P产品数量(吨)
2.5 快速距离计算方法
WMD 按运输问题方式求解,那么平均的时间复杂是
2.5.1 单词质心距离
根据三角不等式上式满足:
=
=
=
这个算法复杂度是
用WCD算法找kNN候选。
2.5.1 松弛的WMD算法
虽然WCD是一个比较快速的算法,但和真实计算还不太逼近,因此有个RWMD算法作为WMD算法的优化,RWMD算法是去掉了WMD算法的一个约束项。这个优化算法是:
subject to:
大量事实证明WMD只有除掉一个约束后的WMD才有可能成为能优化solution。
这个优化solution是对在每个
单词i 与单词j距离最短:j =
则
否则
因此N*N的矩阵,是一个只有N个元素不为0的稀疏矩阵。
算法j =
=
假设通过两个松弛solution得到两个值
2.5.2 预抽取与修剪
为了选择k个最邻近,通过WCD,RWMD两个lower bound函数能显著减少WMD距离的计算量。使用WCD计算的距离进行排序选择与检索文档最近的k个文档。接下来遍历这个剩下的个文档。使用RWCD算法(比WCD更逼近真实距离)删除掉距离比
3.结论
WMD 比BOW, td-idf,BM25,Componential Counting Grid,mSDA,LDA,LSI等计算文档相似度进行来分类有更高的准确率。这种准确率归功于高质量通过word2vec技术学习大量数据而得到的word embedding。WMD另一个非常好的特性是算法的可解释性。
另外一个话题是计算单词距离加一些惩罚项,如果它们出现在文档中不同的区域。例如两个相近的单词一个出现在introduce部分,另一个在method部分。
4.进一步研究
本论文对讨论使用单词相似度来计算文档距离,显然比单纯使用相同单词计算文档距离有很大的进步,但我认为有些地方有不足之处。并且作者也使用词频作为单词移动权重。但一个词的权重不仅仅和词频有关,还和这个词在本文档中最相似距离的单词词频,句式结构,词语在文档中的位置有密切关系。















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









