





【晓白】今天更新图像分割:U-Net&FusionNet希望对图像分割入门的同学有帮助!如果您打算入门并精通深度学习知识,有任何疑问也可以私信讨论,我们一起进步,互相学习。还是那句话,咱们是一个特别正经的技术类分享知乎号。谢谢大家!感兴趣的朋友可以关注我,继续阅读其他的文章。代码设计有很多细节,如果需要代码和数据集,可以点关注私信进一步交流获取。如果对基础知识掌握不熟可以阅读我的其他论文,或者私信与我讨论,进入我们的学习家族,一起进步。如果对大家有帮助的话,可以点赞,收藏,喜欢,赞赏,关注支持一下.关注私信,可获得机器学习的面试资料哦,小伙伴们儿抓紧行动吧!
U-Net&FusionNet
《U-Net: Convolutional Networks for Biomedical Image Segmentation》
作 者: O l a f R o n n e b e r g e r , P h i l i p p F i s c h e r , a n d T h o m a s
B r o x
单 位: 香 港 大 学 与 德 国 弗 莱 堡 大 学
发 表会 议 及 时 间 : M I C C A ( 国 际 医 学 图 像 计 算 和 计 算 机 辅 助 干 预 会
议 ) 2 0 1 5
《FusionNet: A deep fully residual convolutional neural network for image segmentation in connectomics》
作者 : T r a n M i n h Q u a n , D a v i d G . C . H i l d e b r a n d ,
a n d W o n - K i J e o n g
单位 : 蔚 山 国 家 科 学 技 术 研 究 院 & 哈 佛 大 学
主题 及 时 间 : C o m p u t e r V i s i o n a n d P a t t e r n R e c o g n i t i o n 2 0 1 6
医学图像分割
Biomedical Image Segmentation
医学图像分割是医学图像处理与分析领域的 复杂而关键的步骤,目的是将医学图像中具
有某些特殊含义的部分分割出来,并提取相 关特征,为临床诊疗和病理学研究提供可靠
的依据,辅助医生作出更为准确的诊断。当 前,医学图像分割仍在从手动分割或半自动
分割向全自动分割发展。
Ø 处理对象:各种不同成像机理的医学影像,主要有X-射线成像(X-CT)、核磁共振成
像(MRI)、核医学成像(NMI)和超声波成像(UI)、电子显微镜成像(EM)
Ø 应用方向:医疗教学、手术规划、手术仿真及各种医学研究
Ø 应用场景:病变检测、图像分割、图像配准及图像融合
Ø 应用思路:首先对二维切片图像进行分析和处理,实现对人体器官、软组织和病变
体的分割提取,然后进行三维重建和三维显示,可以辅助医生对病变体及其它感兴
趣区域进行定性甚至定量的分析,从而大大提高医疗诊断的准确性和可靠性
难点
1. 数据量少。一些挑战赛只提供不到100例的数据
2. 图片尺寸大。单张图片尺寸大、分辨率高,对模型的处理速度有一定的要求
3. 要求高。医学图像边界模糊、梯度复杂,对算法的分割准确度要求极高
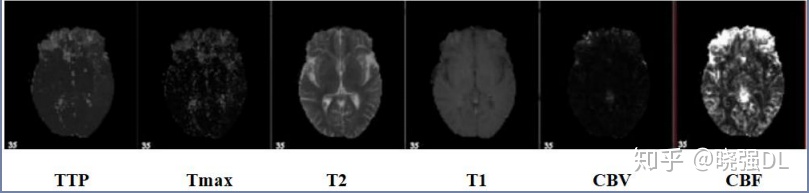
4. 多模态。以ISLES脑梗竞赛为例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多种模
态的数据
ISBI
ISBI challenge
ISBI:IEEE International Symposium on Biomedical Imaging
IEEE国际生物医学影像研讨会
致力于涵盖所有观察规模的生物和生物医学影像的数学,算法和计算方面。ISBI是IEEE
信号处理协会(SPS)和IEEE医学与生物学工程学会(EMBS)的一项联合计划。要求高质
量的论文,包括图像形成和重建,图像处理和分析,动态成像,可视化,图像质量评估,
大图像数据的机器学习以及物理,生物学和统计建模。
生物影像学已经在从诊断到个性化治疗再到对生物过程的机械理解的广泛应用中不断发
展。对更健壮的方法以及与临床和分子数据集成的需求不断增长,该领域继续受到挑战。
连接组学
Connectomics
连接组学绘制与研究神经连接组:一种刻画有机体神经系统
(尤其是脑和眼)的连接方式的完整线路图。连接组学旨在全
面地映射神经系统中发现的神经元网络的结构,以便更好地理
解大脑如何工作。该过程需要以纳米级分辨率(通常使用电子
显微镜)对 3D 脑组织进行成像,然后分析所得到的图像数据,
追踪大脑的神经节并识别各个突触连接。
由于成像的高分辨率,即使是1mm³的脑组织也可以产生超
过 1,000TB 的数据.再加上这些图像中的结构可能非常微妙和
复杂,构建大脑映射的主要瓶颈并不是获取数据本身,而是自
动解释这些数据。
研究成果及意义
Research Results and Research Meaning
1. 赢得了ISBI cell tracking challenge 2015
2. 速度快,对一个512*512的图像,使用一块GPU只需要不到一秒的时间
3. 成为大多做医疗影像语义分割任务的baseline,也启发了大量研究者去思考U型语义分割网络
4. U-Net结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依 据),完美适用于医学图像分割。
U-Net摘要
Abstract of U-Net
Ø 主要贡献:本文提出了一个网络和训练策略,使用数据增强,以便更有效的使用可用的带标签
样本
Ø 网络结构:网络由两部分组成,定义一个收缩路径来获取全局信息,同时定义一个对称的扩张
路径用以精确定位
Ø 网络效果:该网络可以用很少的图片进行端到端训练,处理速度也比较快
Ø 实验结果:以很大的优势赢得了2015 ISBI细胞跟踪挑战赛
FusionNet摘要
Abstract of FusionNet
Ø 主要贡献:本文提出了一种新的深度神经网络FusionNet,用于自动分割连接组学数据中的神
经元结构
Ø 主要方法:引入了基于求和的跳跃连接,允许更深入的网络结构以实现更精确的分割
Ø 实验结果:通过与ISBI-EM分割挑战中的最新方法比较,我们展示了方法的新性能。还展示了 两个其他任务的分割结果,包括细胞膜和细胞体的分割以及细胞形态学的统计分析
引言
Introduction


Padding

拓展:卷积的三种模式:full, same , valid;橙色部分为image,蓝(灰)色部分为卷积核,白色部分 填充为0

full: 从卷积核和image刚开始 相交就进行卷积
same: •same模式是比较常见的模式 •当卷积核的中心和image的边角重合时,开始
做卷积运算,此时的filter范围比full模式小 了一圈 •卷积过后输出的feature map尺寸与原图像的 大小一致. (不过,大小的问题与卷积步长也有 关系.)
valid: 卷积核全部在image中间的 时候,进行卷积运算,可 见,filter的移动范围更加 小了
算法架构
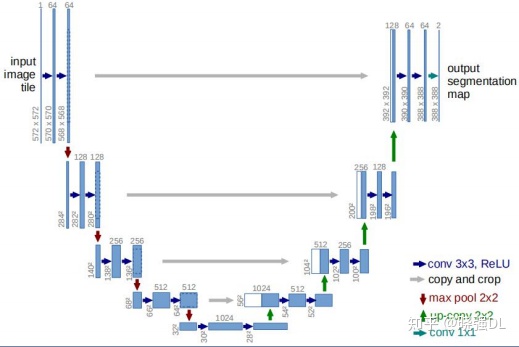

U-Net的输入和输出

具体操作
Skip Architecture

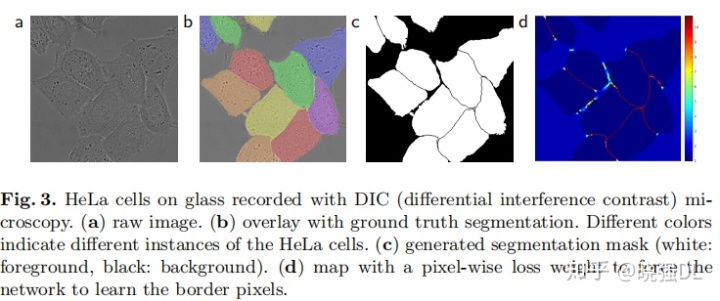
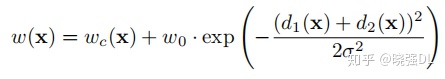
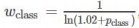
医学分割指标介绍
Introduction of Medical Segmentation Indexes
Pixel error、Rand error、Warping error:
Pixel error:评估图像分割问题最简单的方法。比较预测的label和实际的label,错误的点
除以总数,就是像素误差。
Rand error:兰德指数是两个数据聚类的相似性评价方法,改造之后用来衡量分割性能
给定一张图片S,有n个像素点,同时有两个分割X和Y(实际和预测)
a:两个分割中同属于一个聚类的像素点数量
b:两个分割中都不属于一个聚类的像素点数量
Rand指数:
RI是用来衡量相似度的,越高越好。和误差相反,兰德误差如下:
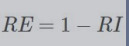
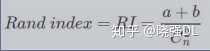
W a r p i n g e r r o r:主要来衡量分割目标的拓扑形状效果。给定候选标注T
(预测值)和参考标注L(实际值)的warping error可以认为是L对于T最
好的汉明距离。
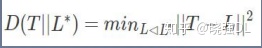
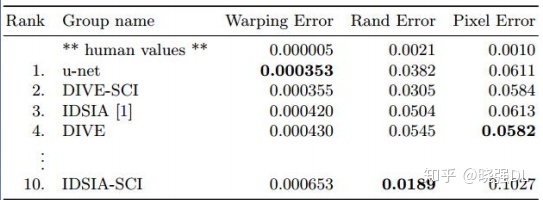
实验分析
Experimental analysis
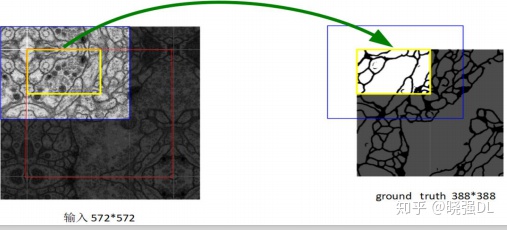
训练数据为30幅图像(512x512像素),来自果蝇第一龄幼虫腹神经索(VNC)的连续切片透射
电镜。每幅图像都有一个完整标注的细胞(白色)和膜(黑色)的真实分割图。测试集是公开的,
但它的标签是保密的。通过将预测的膜概率图发送给组织者,可以得到评估结果。
实验分析
Experimental analysis
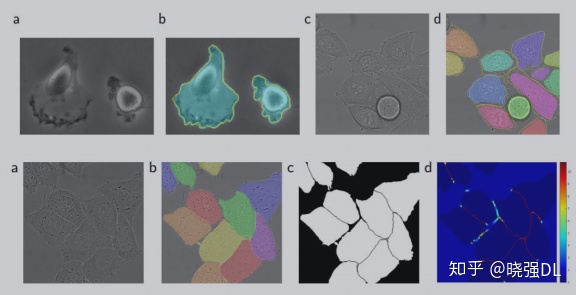
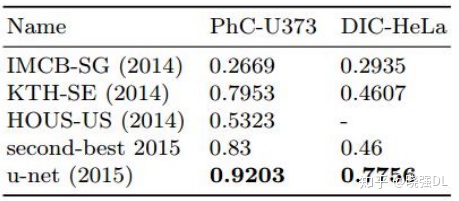
在“PHC-U373”数据集和“DIC-HeLa”数据集上的IOU对比:
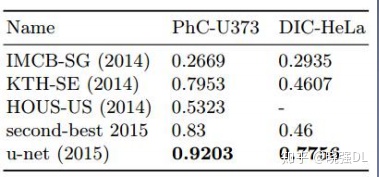
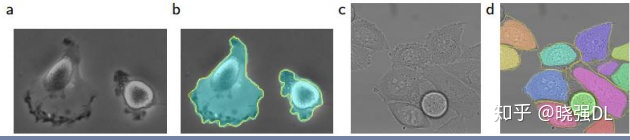
(A)“PHC-U373”数据集 输入图像的一部分。 (C)“DIC-HeLa”数据集 的输入图像
论文总结
Summary of the paper
U-Net关键点&创新点
• 设计了严格对称的U型结构
• 使用镜像折叠补充输入图像
• 使用加权损失函数
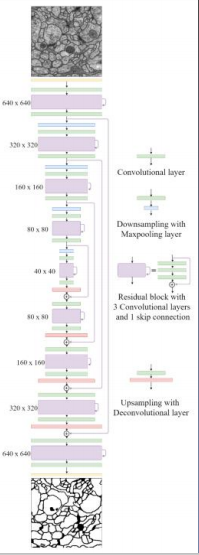
FusionNet关键点&创新点
• 改编U-Net,加入padding
• 加入残差块
• 短跳+长跳
import FusionNet:
import torch.nn as nn
import torch
def conv_block(in_dim,out_dim,act_fn,stride=1):
model = nn.Sequential(
nn.Conv2d(in_dim, out_dim, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def conv_trans_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=3, stride=2, padding=1,output_padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def conv_block_3(in_dim, out_dim, act_fn):
model = nn.Sequential(
conv_block(in_dim, out_dim, act_fn),
conv_block(out_dim, out_dim, act_fn),
nn.Conv2d(out_dim, out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
)
return model
class Conv_residual_conv(nn.Module):
def __init__(self, in_dim, out_dim, act_fn):
super(Conv_residual_conv, self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
act_fn = act_fn
self.conv_1 = conv_block(self.in_dim, self.out_dim, act_fn)
self.conv_2 = conv_block_3(self.out_dim, self.out_dim, act_fn)
self.conv_3 = conv_block(self.out_dim, self.out_dim, act_fn)
def forward(self, input):
conv_1 = self.conv_1(input)
conv_2 = self.conv_2(conv_1)
res = conv_1 + conv_2
conv_3 = self.conv_3(res)
return conv_3
class Fusionnet(nn.Module):
def __init__(self, input_nc, output_nc, ngf, out_clamp=None):
super(Fusionnet, self).__init__()
self.out_clamp = out_clamp
self.in_dim = input_nc
self.out_dim = ngf
self.final_out_dim = output_nc
act_fn = nn.ReLU()
act_fn_2 = nn.ELU(inplace=True)
# encoder
self.down_1 = Conv_residual_conv(self.in_dim, self.out_dim, act_fn)
self.pool_1 = conv_block(self.out_dim, self.out_dim, act_fn, 2)
self.down_2 = Conv_residual_conv(self.out_dim, self.out_dim * 2, act_fn)
self.pool_2 = conv_block(self.out_dim * 2, self.out_dim * 2, act_fn, 2)
self.down_3 = Conv_residual_conv(self.out_dim * 2, self.out_dim * 4, act_fn)
self.pool_3 = conv_block(self.out_dim * 4, self.out_dim * 4, act_fn, 2)
self.down_4 = Conv_residual_conv(self.out_dim * 4, self.out_dim * 8, act_fn)
self.pool_4 = conv_block(self.out_dim * 8, self.out_dim * 8, act_fn, 2)
# bridge
self.bridge = Conv_residual_conv(self.out_dim * 8, self.out_dim * 16, act_fn)
# decoder
self.deconv_1 = conv_trans_block(self.out_dim * 16, self.out_dim * 8, act_fn_2)
self.up_1 = Conv_residual_conv(self.out_dim * 8, self.out_dim * 8, act_fn_2)
self.deconv_2 = conv_trans_block(self.out_dim * 8, self.out_dim * 4, act_fn_2)
self.up_2 = Conv_residual_conv(self.out_dim * 4, self.out_dim * 4, act_fn_2)
self.deconv_3 = conv_trans_block(self.out_dim * 4, self.out_dim * 2, act_fn_2)
self.up_3 = Conv_residual_conv(self.out_dim * 2, self.out_dim * 2, act_fn_2)
self.deconv_4 = conv_trans_block(self.out_dim * 2, self.out_dim, act_fn_2)
self.up_4 = Conv_residual_conv(self.out_dim, self.out_dim, act_fn_2)
# output
self.out = nn.Conv2d(self.out_dim, self.final_out_dim, kernel_size=3, stride=1, padding=1)
def forward(self, input):
down_1 = self.down_1(input)
pool_1 = self.pool_1(down_1)
down_2 = self.down_2(pool_1)
pool_2 = self.pool_2(down_2)
down_3 = self.down_3(pool_2)
pool_3 = self.pool_3(down_3)
down_4 = self.down_4(pool_3)
pool_4 = self.pool_4(down_4)
bridge = self.bridge(pool_4)
deconv_1 = self.deconv_1(bridge)
skip_1 = (deconv_1 + down_4) / 2
up_1 = self.up_1(skip_1)
deconv_2 = self.deconv_2(up_1)
skip_2 = (deconv_2 + down_3) / 2
up_2 = self.up_2(skip_2)
deconv_3 = self.deconv_3(up_2)
skip_3 = (deconv_3 + down_2) / 2
up_3 = self.up_3(skip_3)
deconv_4 = self.deconv_4(up_3)
skip_4 = (deconv_4 + down_1) / 2
up_4 = self.up_4(skip_4)
out = self.out(up_4)
return out
if __name__ == "__main__":
import torch as t
rgb = t.randn(1, 3, 352, 480)
net = Fusionnet(3, 12, 64)
out = net(rgb)
print(out.shape)
至此今天的文章更新完毕,可以关注,点赞,赞赏一下,谢谢精神合伙人。
重要的事情说三遍!
重要的事情说三遍!
重要的事情说三遍!
关注我,阅读我专栏更多文章:
深度学习专栏zhuanlan.zhihu.com
想要了解机器学习深度学习,阅读NLP,图像处理等等,可点击下方链接:

或者想要了解贪心学院的课程,比如京东NLP和NLP,ML训练营等等系列,感兴趣报名,咨询通过如下方式:贪心+想要的小伙伴儿可以行动啦!贪心:
哈佛、剑桥学生都青睐的京东智联云NLP实战训练营开营mp.weixin.qq.com
向小姐姐和我咨询都可以哦!晓强Deep Learning的读书分享会,先从这里开始,从大学开始。大家好,我是晓强,计算机科学与技术专业研究生在读。我会不定时的更新我的文章,内容可能包括深度学习入门知识,具体包括CV,NLP方向的基础知识和学习的论文;网络表征学习的相关论文解读。当然我每天的读书心得也会分享给大家,可能涉及我们生活各个方面的书籍。我也会不定时回答大家的问题与大家一同进步,共同交流,互相监督,结交更多的朋友。希望大家多留言,多交流,多多关照。如果有转载请标明作者链接,有的内容来自其他网页,如果有侵权,可以私信我删除。















 2949
2949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









