





全文共 7016字,预计学习时长 40分钟或更长

现代科技时代产生和收集的数据越来越多。然而在机器学习中,太多的数据可不是件好事。某种意义上来说,特征或维度越多,越会降低模型的准确性,因为需要对更多的数据进行泛化——这就是所谓的“维度灾难”。
降维是一种降低模型复杂性和避免过度拟合的方法。特征选择和特征抽取是两种主要的降维方式。特征选择是从原有特征集中选出一部分子集,而特征抽取是从原有特征集收集一部分信息来构建新的特征子空间。
本文将会带你学习特征抽取。在实际应用中,特征抽取不仅可以扩大储存空间,提高学习算法的计算效率,通过避免维度灾难,还可以提升预测性能——尤其是在使用非正则化的模型时。
具体来说,我们将会讨论使用主成分分析算法(PCA)将数据集压缩至一个更低维的特征子空间,同时保留大部分相关信息。我们将会学到:
· PCA的概念及背后的数学知识
· 如何使用Python一步一步执行PCA
· 如何使用Python库来执行PCAscikit-learn机器学习
现在开始吧!

本教程改编自Next Tec的Python机器学习系列的第二部分,该系列会带领小白成功学会用Python进行机器学习和深度学习算法。本教程包含浏览器嵌入式沙箱环境,预先安装好了所有必要的软件和库,还有使用公共数据集的一些项目。

1. 主成分分析法导论
主成分分析法是一种非监督式的线性变换方法,被广泛应用于诸多领域,主要是用于特征抽取和降维。其他热门应用还有探索性数据分析、排除股票交易市场嘈杂信号、以及生物信息学中对基因组数据和基因表达水平的分析。
PCA基于特征之间的联系识别出数据中的模型。简言之,PCA旨在找出高维数据中最大方差的方向,并将其投影到一个新的维数相同或更低的的子空间中。
在新特征轴互相正交的条件下,新子空间的正交轴(主成分)可以视为为最大方差方向,如下图所示:
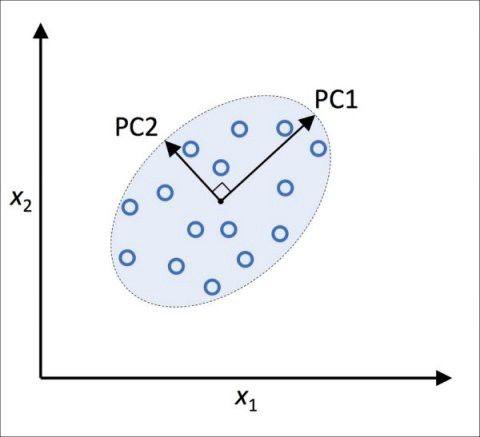
在上图中,x1和x2是原始特征轴,PC1和PC2是主成分。
如果使用PCA进行降维,构造一个d×k维变换矩阵W,可以将一个样本中的向量x映射到新的k维特征子空间(k比d小)。
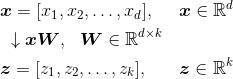
由于将原先d维的数据映射到新的k维子空间(通常k远小于d),第一个主成分会有最大的可能方差,并且如果其他的主成分都互不相关的话,他们也会有最大方差——即使输入特征互相关联,产生的主成分也会相互正交(不相关)。
注意:数据缩放对PCA方向有很大的影响,如果特征是在不同的规模下测量的,同时又想赋予这些特征相同的重要性,需要在PCA之前对这些特征进行标准化。
在详细学习用于降维的PCA算法之前,用简单的几步将其概括一下:
1. 对d维数据集进行标准化。
2. 构建协方差矩阵。
3. 将协方差矩阵分解为特征向量和特征值。
4. 对特征值进行降序排序,对相应的向量进行排序。
5. 选取与k个最大特征值对应的k个特征向量,其中k为新特征子空间的维数(k ≤ d)。
6. 根据那k个特征向量构建投影矩阵W。
7. 通过投影矩阵W将d维输入数据集X变换为新的k维数据子空间。
现在使用Python来一步步执行PCA作为练习。然后,看看如何使用scikit-learn机器学习来更好地执行PCA。
2. 逐步抽取主成分
我们将使用UCI机器学习存储库中的Wine数据集作为示例。该数据集包含178个葡萄酒样品,用了13个特征描述它们的化学性质。
本节将学习PCA四步曲的第一步,然后再学习剩下的三步。可以使用Next Tech沙箱来学习本教程中的代码,它预先安装了所有必要的库,或者也可以在本地环境中运行代码片段。
一旦沙箱加载完毕,我们将从直接从存储库加载Wine数据集开始。
import pandas as pd df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/' 'machine-learning-databases/wine/wine.data', header=None)df_wine.head()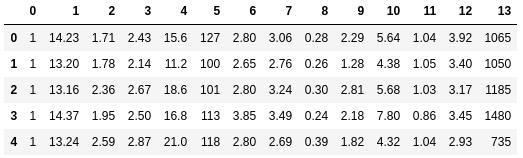
接下来,用70:30的分割将Wine数据处理为单独的训练和测试集,并将其标准化为单位方差。
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler # split into training and testing setsX, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].valuesX_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, stratify=y, random_state=0)# standardize the featuressc = StandardScaler()X_train_std = sc.fit_transform(X_train)X_test_std = sc.transform(X_test)完成必要的预处理后,现在进入第二步:构建协方差矩阵。对称的d×d维协方差矩阵(d是数据集的维度),包含了不同特征间的成对协方差。例如,特征x_j和x_j在总体水平上的协方差可由下式计算:
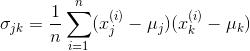
这里μ_j和μ_k分别是特征j和特征k的样本均值。
注意:如果对数据集进行了标准化,样本均值则为0。如果两个特征间是正值协方差,意味着二者同增减;若是负值协方差,意味着二者变化方向相反。例如,三个特征的协方差矩阵可以写成(注意:Σ表示希腊大写字母sigma,而不是表示和):
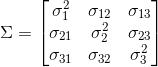
协方差矩阵的特征向量表示主分量(最大方差方向),对应的特征值定义其大小。从Wine数据集13×13维协方差矩阵中,可以得到13个特征向量和特征值。
第三步,从协方差矩阵中获取特征值。特征向量v满足以下条件:
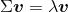
λ是一个标量:特征值。由于手动计算特征向量和特征值有些复杂繁琐,我们将使用NumPy的linalg.eig函数得到Wine协方差矩阵的特征对。
import numpy as np cov_mat = np.cov(X_train_std.T)eigen_vals, eigen_vecs = np.linalg.eig(cov_mat)使用numpy.cov函数计算标准化数据集的协方差矩阵。使用linalg.eig函数进行特征分解,得到一个包含13个特征值及对应的特征向量的向量(特征值),它们都作为列存储在一个13×13维的矩阵(特征向量)中。

3. 总方差和可释方差
由于想通过压缩数据集得到一个新的特征子空间来降低数据集的维数,我们只选择包含大部分信息(方差)的特征向量(主成分)的子集。
在收集这k个具有最大信息量的特征向量之前,先计算特征值的特征方差贡献率。特征值λ_j的特征方差贡献率就是特征值λ_j与特征值的总和之比。
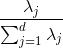
使用NumPy cumsum函数计算出方差贡献的总和,接下将用matplotlib’s step函数来描述:
import matplotlib.pyplot as plt# calculate cumulative sum of explained variancestot = sum(eigen_vals)var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)]cum_var_exp = np.cumsum(var_exp) # plot explained variancesplt.bar(range(1,14), var_exp, alpha=0.5, align='center', label='individual explained variance')plt.step(range(1,14), cum_var_exp, where='mid', label='cumulative explained variance')plt.ylabel('Explained variance ratio')plt.xlabel('Principal component index')plt.legend(loc='best')plt.show()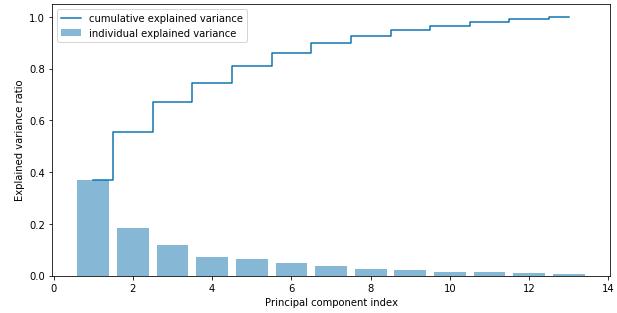
结果表明,第一个主成分约占方差的40%。此外,我们可以看到前两个主成分合起来占了数据集中近60%的方差。
4. 特征变换
在成功地将协方差矩阵分解为特征对之后,现在继续PCA的最后三个步骤,将Wine数据集变换到新的主成分轴上。
先通过按特征值的递减排序对特征对进行分类:
# Make a list of (eigenvalue, eigenvector) tupleseigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len(eigen_vals))] # Sort the (eigenvalue, eigenvector) tuples from high to loweigen_pairs.sort(key=lambda k: k[0], reverse=True)接下来,收集两个最大特征值对应的两个特征向量,来得到这个数据集中大约60%的方差。注意,为了便于说明,我们只选择了两个特征向量,因为我们将在本小节后面通过二维散点图来绘制数据。在实际应用中,主成分的数量由计算效率和分类器性能共同确定:
w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis]))print('Matrix W:', w) [Out:]Matrix W: [[-0.13724218 0.50303478] [ 0.24724326 0.16487119] [-0.02545159 0.24456476] [ 0.20694508 -0.11352904] [-0.15436582 0.28974518] [-0.39376952 0.05080104] [-0.41735106 -0.02287338] [ 0.30572896 0.09048885] [-0.30668347 0.00835233] [ 0.07554066 0.54977581] [-0.32613263 -0.20716433] [-0.36861022 -0.24902536] [-0.29669651 0.38022942]]通过执行前面的代码,根据上面的两个特征向量创建了一个13x2维的投影矩阵W。
利用投影矩阵,可以将一个样本x(一个1 x 13维的行向量)转换到PCA子空间(主成分1和主成分2)中,得到一个包含两个新特征的二维样本向量x′:
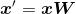
X_train_std[0].dot(w)同样,可以通过计算矩阵点积将124 x 13维训练数据集变换成两个主成分:
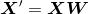
X_train_pca = X_train_std.dot(w)最后,将转换后的Wine训练集在一个二维散点图中进行可视化,存储为一个124 x 2维矩阵:
colors = ['r', 'b', 'g']markers = ['s', 'x', 'o']for l, c, m in zip(np.unique(y_train), colors, markers): plt.scatter(X_train_pca[y_train==l, 0], X_train_pca[y_train==l, 1], c=c, label=l, marker=m)plt.xlabel('PC 1')plt.ylabel('PC 2')plt.legend(loc='lower left')plt.show()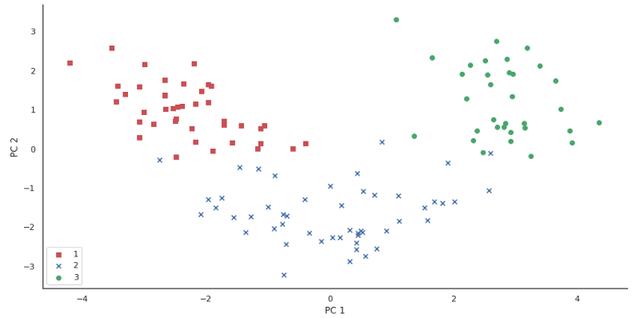
从图中可以看出,数据沿着x轴上(第一个主分量)分布的更多,这与之前创建的特征方差贡献率图形是一致的。然而,我们可以直观地看到,线性分类器应该可以很好地进行分类。
尽管在之前的散点图中为了解释说明,编码了类标签,但是记住,PCA是一种不使用类标签信息的无监督技术。
5. PCA与scikit-learn机器学习
前一小节帮助我们了解了PCA的内部工作原理,现在将讨论如何使用在scikit-learn中实现的PCA 类模型。PCA class模型是scikit-learn的另一个转换器类,在使用相同的模型参数转换训练数据和测试数据集之前,我们首先使用训练数据来拟合模型。
在Wine训练数据集上使用PCA类模型,通过逻辑回归对变换后的样本进行分类:
from sklearn.linear_model import LogisticRegressionfrom sklearn.decomposition import PCA # intialize pca and logistic regression modelpca = PCA(n_components=2)lr = LogisticRegression(multi_class='auto', solver='liblinear') # fit and transform dataX_train_pca = pca.fit_transform(X_train_std)X_test_pca = pca.transform(X_test_std)lr.fit(X_train_pca, y_train)现在用一个常规的plot_decision_regions函数对决策区域进行可视化:
from matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, resolution=0.02): # setup marker generator and color map markers = ('s', 'x', 'o', '^', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # plot class samples for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.6, c=[cmap(idx)], edgecolor='black', marker=markers[idx], label=cl)# plot decision regions for training setplot_decision_regions(X_train_pca, y_train, classifier=lr)plt.xlabel('PC 1')plt.ylabel('PC 2')plt.legend(loc='lower left')plt.show()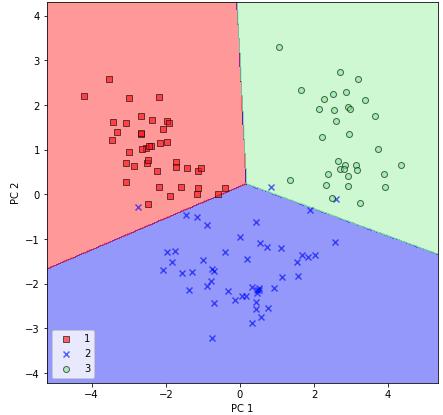
执行完前面的代码,现在应该看到训练数据的决策区域减少到两个主成分轴。
为了完整性,在转换后的测试数据集中绘制逻辑回归的决策区域,看看它是否能够很好地分类:
# plot decision regions for test setplot_decision_regions(X_test_pca, y_test, classifier=lr)plt.xlabel('PC1')plt.ylabel('PC2')plt.legend(loc='lower left')plt.show()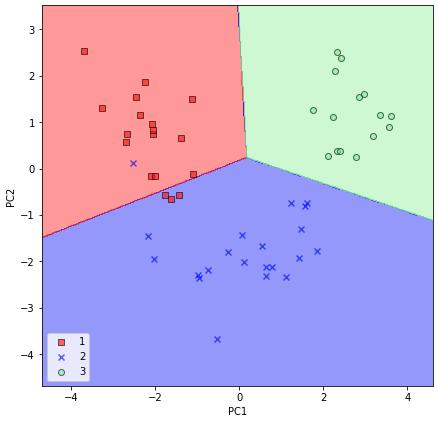
通过执行前面的代码为测试集绘制决策区域之后,我们可以看到逻辑回归在这个二维特征子空间中表现得非常好,并且在对测试数据集进行分类时只犯了很少的错误。
如果对特征方差贡献率感兴趣的话,可以简单地用n_components参数集对PCA 类进行初始化,所以所有主要成分的保存和特征方差贡献率的计算都可以通过explained_variance_ratio属性来实现:
pca = PCA(n_components=None)X_train_pca = pca.fit_transform(X_train_std)pca.explained_variance_ratio_注意:当对PCA类进行初始化时,即设置n_components=None,它将以分类的顺序返回所有的主成分,而不是执行降维操作。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









