






Chen, Xinshi, et al. "RNA Secondary Structure Prediction By Learning Unrolled Algorithms." ICLR (2020).
引言
众所周知,RNA(核糖核酸) 是生物体内重要的遗传信息载体。构成RNA的碱基主要有4种,即A(腺嘌呤)、G(鸟嘌呤)、C(胞嘧啶)、U(尿嘧啶) 。虽然RNA是单链结构的,但在我们的身体里,RNA中的部分碱基往往会相互配对,形成复杂的二级结构。如图一所示,一条长长的RNA单链,其内部互相配对形成复杂的网络结构。
图一 RNA的二级结构 (via Wikipedia)
那么,如果给定了某个RNA的碱基顺序,又应该如何来预测该RNA的二级结构呢?对于这一问题,传统的解决方法是将它看做一个类似于字符串匹配的问题,并用类似动态规划一类的算法解决。而这篇ICLR文章采用深度学习和优化问题相结合的方式设计模型,其效果远超传统方法。下面就让我们一起来学习一下文中解决问题的具体方法和设计思路。
背景与挑战
RNA单链作为由四种碱基(A,G,C,U)构成的单链,可以被看做一个一维序列。而它的二级结构可以被看做一张图,配对的节点之间互相连边。模型需要预测的,就是这张图的邻接矩阵。在过去,这一类问题往往是用动态规划算法来解决的。然而,动态规划算法面临着两个明显的问题。
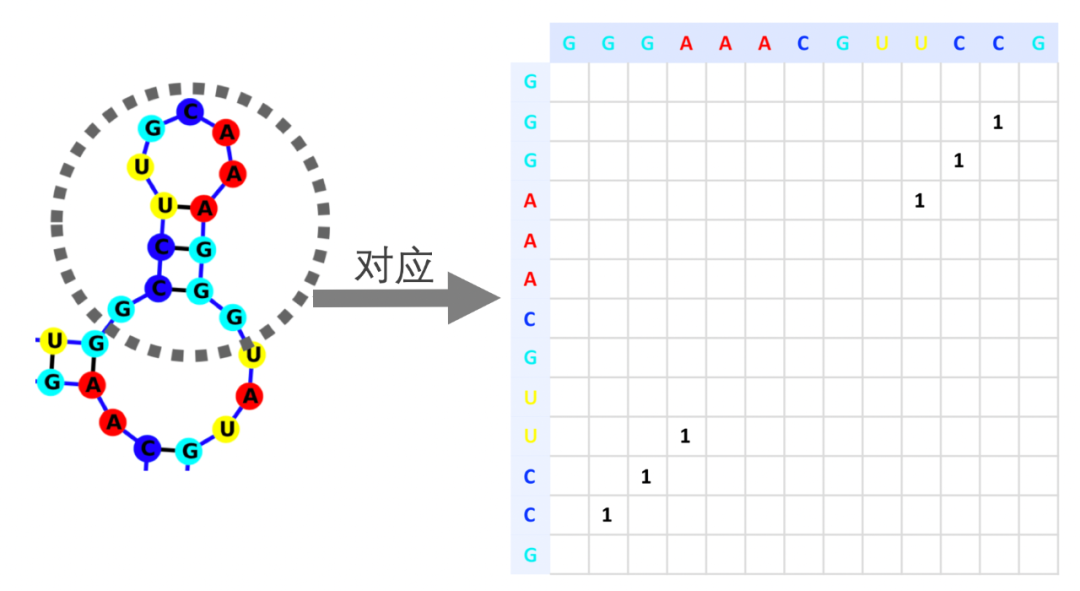
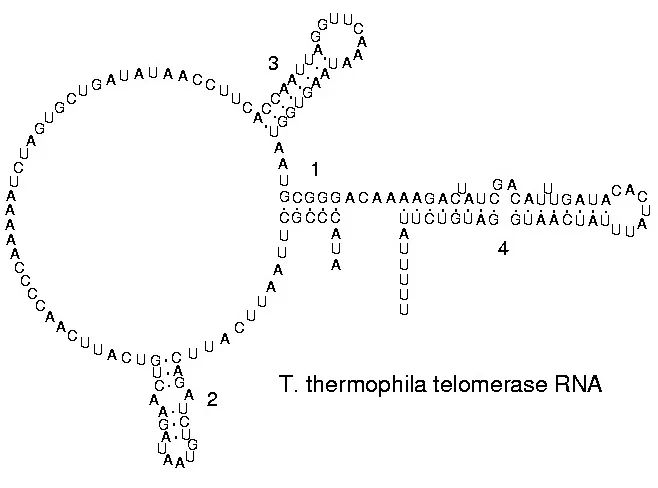
图二 一段RNA和它对应的邻接矩阵
第一,这一类算法速度太慢。如果用动态规划解决这一问题,容易知道,当RNA的长度为L时,算法的时间和空间复杂度应都为O(L2)左右。某些优化算法可能可以达到线性复杂度,可这必定以牺牲准确度为代价。
第二,动态规划算法计算的结果往往不是完全正确的,因为现实中RNA的二级结构可以颇为复杂。比如图二中,两个环之间的碱基又互相配对,形成复杂的三维结构。
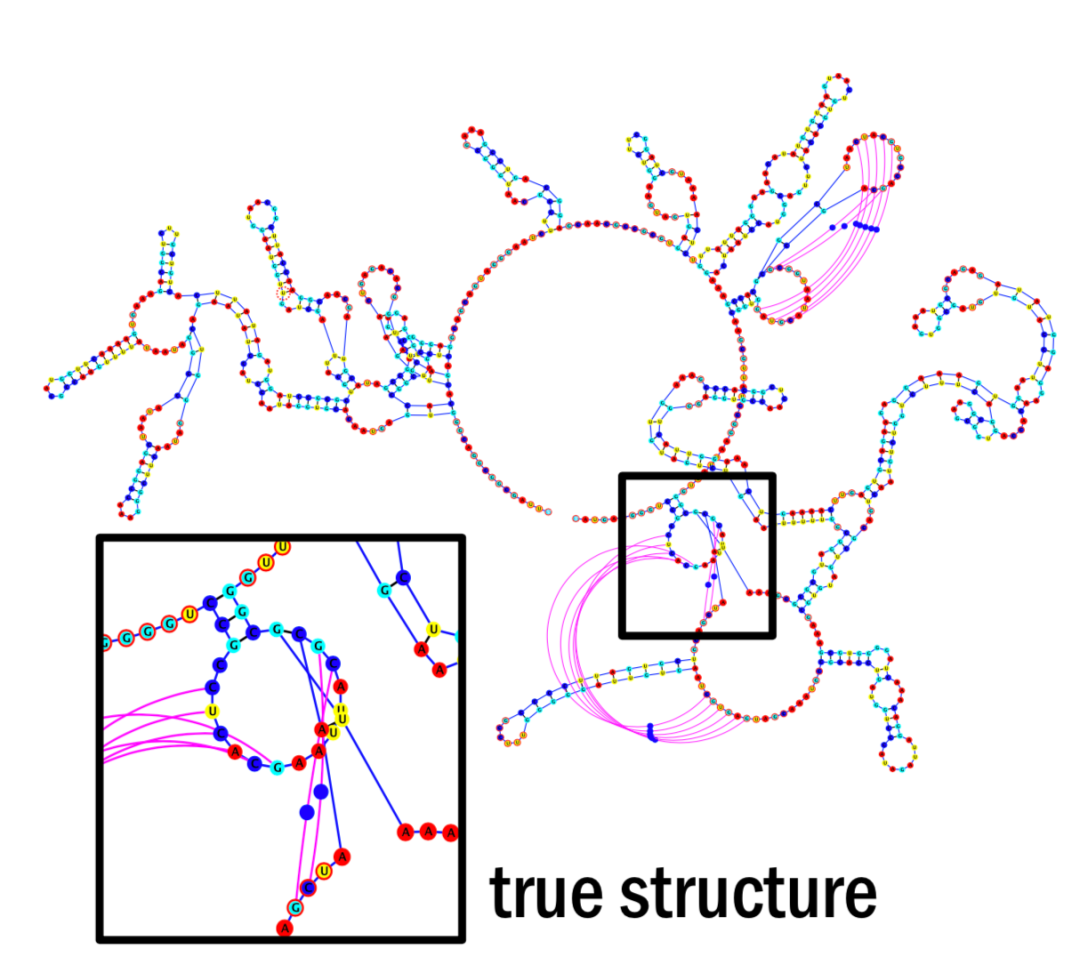
图三 一种复杂的碱基配对模式
而另一方面,如果用一个深度学习模型来预测RNA的结构呢?很容易想到,深度学习模型也会遇到诸多挑战。
首先,模型的损失函数难以确定。如果用深度学习模型来解决这一问题的话,模型应当接受一维的RNA序列(假设长度为L)作为输入,输出则应是一个二维的邻接矩阵(大小为L*L)。可以看出,这一问题和传统的分类或回归任务皆不同,因而传统的损失函数难以适应这一任务。
第二,RNA碱基之间的配对是遵循一定规则的。比如只有A与U,C与G和G与U之间才有可能存在配对关系。还有,如果两个碱基之间相隔比较近时,它们就算互相匹配也不会生成稳定的氢键,因为整条RNA长链不会在中间有尖锐的弯折。在这么多的规则约束下,如何训练一个更高效的神经网络,使得它的每一个输出都符合上面的这些规则呢?
今年的ICLR 2020 中,佐治亚理工大学和阿卜杜拉国王科技大学合作提出了一个深度模型E2Efold,来解决以上这些问题。下面就让我们来一起看看,这篇文章里是如何定位这些挑战的。
模型
这篇论文中提出的端到端模型由两部分模块构成:深度评分模型(Deep score model)和后处理神经网络(Post-processing network)。前者用来生成一个矩阵输出,其中的每个值描述了序列中两个节点的关联强弱,后者对这个矩阵进行处理,使得最终结果中矩阵的每个值接近0 或1 (无连接或有连接),且符合以下一系列规则约束。
规则一 只有三种碱基对可以结合:B = {AU, UA}U{GC, CG}U{GU, UG},若xi ,xj不属于B, 则 Aij = 0。
规则二 碱基配对形成的环中不存在尖角。若 |i - j| < 4,则Aij = 0。
规则三 每个碱基至多只能与一个其他碱基配对。对任意i,∑jAij <= 1。
在下面的章节,本文将具体描述深度评分模型和后处理神经网络中具体的技术细节,阐明模型是如何达到以上约束的。
模块一 深度评分模型(Deep score model)
图四介绍了深度评分模型(DEEP SCORE NETWORK)的结构。从图中可以看出,深度评分模型接受RNA序列的one-hot表达作为主要输入,通过Transformer Encoder 和2D 卷积层计算一个矩阵输出 U。
除此之外,模型还使用了各个节点的位置表达作为辅助输入。方法是,把各个核算的绝对位置(1, 2, 3, ..., L)和相对位置(1/L, 2/L, 3/L, .., 1)作为输入,其中L是输入序列的长度。在经过一系列特征映射(例如正弦函数,多项式函数等)和一个MLP之后,生成每个位置特定的表达。
经过深度评分模型后,输出U是一个L*L的矩阵,其中每个值代表了两个节点之间的关联大小。
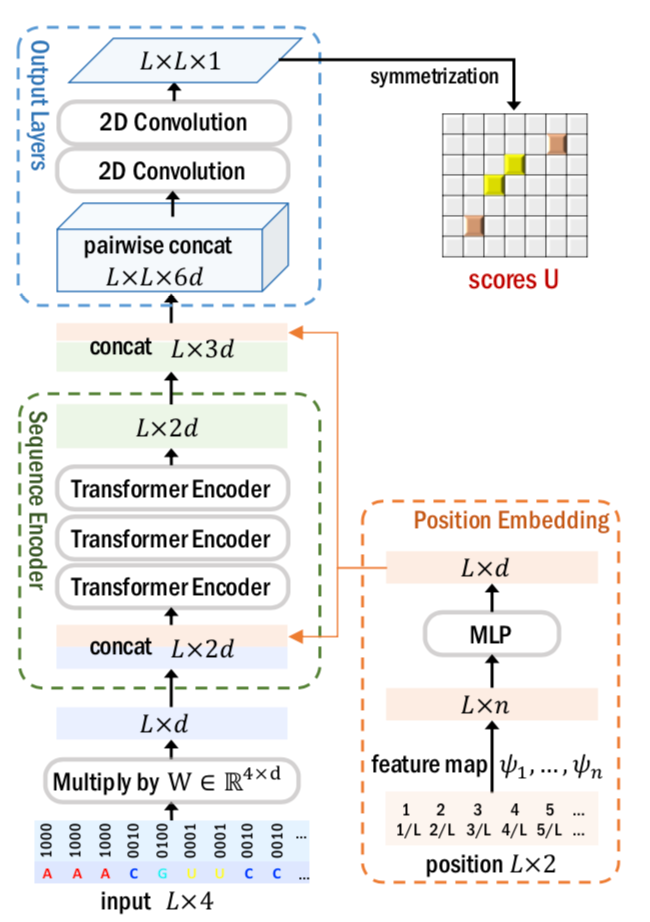
图四 深度评分模型(Deep score model)的结构
模块二 后处理神经网络(Post-processing network)
深度评分模型的输出U中每个值代表了两个节点之间关联大小。然而,这个值往往并不是0或1而是介于两者之间的一个实数。另一方面,这个值的计算也并没有考虑到上文中的三条约束规则。为了输出一个符合上面所述约束规则,其中的值又是非0即1的矩阵,文中采用了优化方法来解决这一问题。
为了得到符合规则的结果,除了深度评分模型的输出U外,文中引入了另外一个同样大小为L*L的矩阵A进行优化。优化目标为:
max 1/2 s.t . A∈[0, 1]和上文的三条规则
其中< , >是矩阵内积运算,s是一个偏移量。很明显,在这种情况下,想要达到最优化,需要在所有uij 大于s的情况下,令对应的 aij = 1。这样的话,当模型达到最优化时,矩阵A就是我们想要得到的最终结果。
下一步,进一步将三条规则约束都嵌入到矩阵A的优化条件中。我们假定A = T(Â) = 1/2 (Â ◦ Â + (Â ◦ Â)T) ◦ M。其中,矩阵M也是一个L*L的矩阵,其定义为:如果矩阵中某一位置对应的两个碱基可以配对(属于集合B)且距离小于4,那么该位置的值为1,否则为0。可以看出,矩阵M是常数。而且,A是M通过位乘计算得到的,这使得矩阵A也可以满足规则一和规则二。
进一步地,通过对Â施加 l1 惩罚项,使得矩阵A的值变得稀疏。此时,优化目标为:
max 1/2 ij - s, T(Â) > - ρ || Â ||1 s.t . 规则三
此时,引入Â的目的达到了,Â中的每个值都变成了无约束的任意实值,而整个问题变成了拥有L个不等式约束的规划问题。由于规则三令RNA序列中的每个节点(总共L个)的度数不大于1,故而约束的数量为L。很自然地,我们可以引入L个拉格朗日乘子 λ, 将一系列不等式约束转化为等式约束:
min λ maxA 1/2 ij - s, T(Â) > - < λ, ReLU(∑i Aj -1) > - ρ || Â ||1
其中,λ 是L个拉格朗日乘子构成的向量,其值不小于0。∑i Aj (在后文也写作A1,即矩阵A与一个长度为L的全1向量的乘积)是对矩阵A每一行求和的结果,是一个长度为L的向量。对这个向量中的每一个元素减一,并让其通过ReLU函数,其结果仍是长度为L的向量。
利用主对偶方法,可以对上面的优化目标进行迭代优化。下图给出了在第t次迭代时,计算第t+1次迭代值的方法。总的迭代次数T是超参,随着迭代次数的增长,结果也会越来越接近最优。
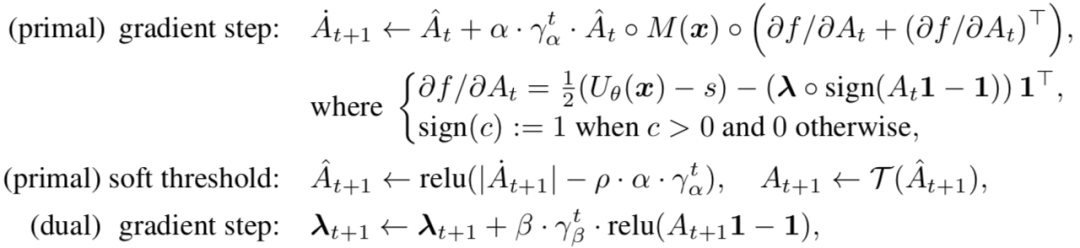
图五 各个参数的迭代更新公式
其中,α, β 是步长而γα, γβ 是 decaying coefficients。注意它们仅仅是这个优化问题中的参数而并非整个深度模型的参数!在下图中,每一次迭代,都会根据这些参数重新计算相应的Â,A和拉格朗日乘子 λ的值。
技术介绍 展开算法(Unrolled algorithm)
仅仅有上面的优化算法是不够的,我们需要把前面的深度学习模型和迭代优化算法结合起来,才能在模型计算出矩阵U之后,立刻计算出相应的A。Unrolled algorithm 就是深度模型中的一个重要技术,可以在端到端神经网络之中嵌入迭代算法,并同时训练神经网络和迭代算法中的参数。
2010年,Karol Gregor 和 Yann LeCun最早提出了Unrolled algorithm技术,用Iterative Shrinkage and Thresholding Algorithm(ISTA)来快速估计稀疏编码。其核心思想十分简单:将输入X反复通过迭代模块S来求得最终结果Z。

图六 展开算法(Unrolled algorithm)流程
在本文中,根据上文的迭代公式,作者设计了PPcell模块和相应的PP网络。将上文深度神经网络的输出直接输入到PP网络中后,PP网络会计算各个变量(Â,A和λ)的初始值,然后将其放入PPcell中反复迭代,最终输出的A即是我们想要的结果,符合各个约束的邻接矩阵。


图七 PPcell模块和PP网络
注意到上面的算法虽然是优化过程中的迭代公式,在字面上存在计算偏导数的过程,然而在事实上,上述算法仅仅是参数正向传播的过程。在实现时,上述算法直接与深度评分网络相连且一起训练,而算法中的参数集合φ(其中包含迭代算法的步长,decaying coefficients等)也是可训练的参数。而只有PPcell的迭代次数T是这个端到端模型真正的超参数。softsign(c) 是一个可微的符号函数近似,等于 1/(1 + exp(−kc)),其中 k是温度值.
技术介绍 可微F1损失函数
由于这个神经网络面对的任务既不是分类也不是回归,因而对于这个特殊的任务,我们需要一个特殊的损失函数。这篇文章中定义了可微F1损失函数,利用对每张图预测结果的F1值的近似计算进行训练。
假设模型得出的预测值是邻接矩阵A而真实结果是A*,该文中近似计算真正例,假正例,真反例,假反例的值分别为(⟨ . , . ⟩是两矩阵的內积):
TP=⟨A, A*⟩, FP=⟨A,1−A*⟩, FN=⟨1−A, A*⟩, TN=⟨1−A,1−A*⟩.
由于 F1度量 = 2TP/(2TP + FP + FN),因此这篇文章提出了模仿F1度量的损失函数:
L−F1(A, A*) := −2⟨A, A*⟩/ (2⟨A, A*⟩ + ⟨A, 1 − A*⟩ + ⟨1 − A, A*⟩)
用来对每一条RNA计算预测结果的梯度。将一个batch中所有RNA计算出来的损失函数平均,就得到了模型优化的总体损失函数。
实验
本文在ArchiveII及RNAStralign两个数据集,共10类30451种RNA结构上进行了实验。在实验中,E2Efold取得了比主流极限模型更好的效果,其提升大约在20%左右。
为什么会取得这样的效果提升呢?文中以在RNA中经常出现的“假结”现象为例对模型结果进行了可视化。所谓“假结”(Pseudo-knot),就是在下图(ii)中出现的情况。
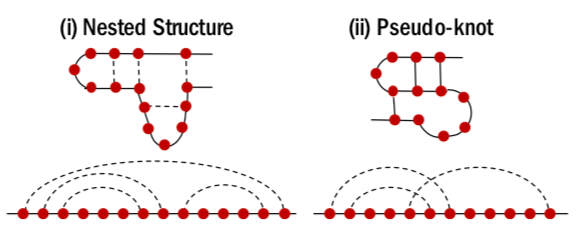
图八 各种RNA二级结构
下面我们选取文中的一个RNA实例,看看E2Efold和其他极限模型都给出了什么样的结果。
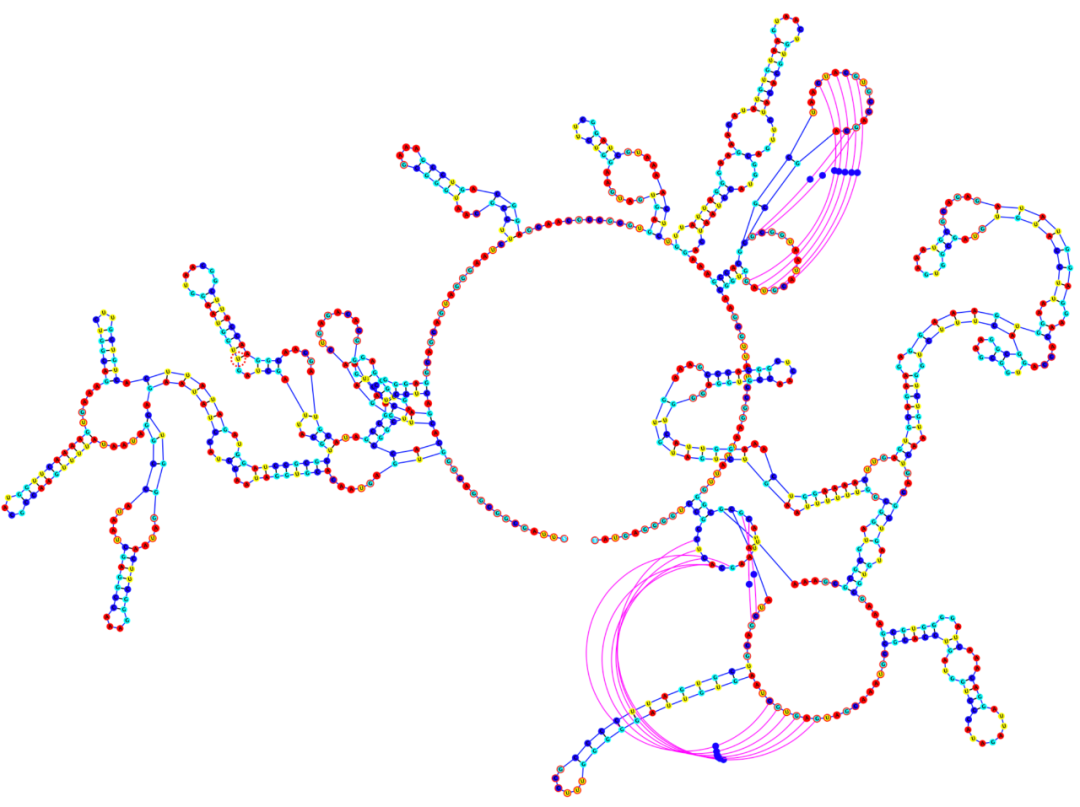
这是该RNA的真实二级结构

这是E2Efold模型给出的预测结果
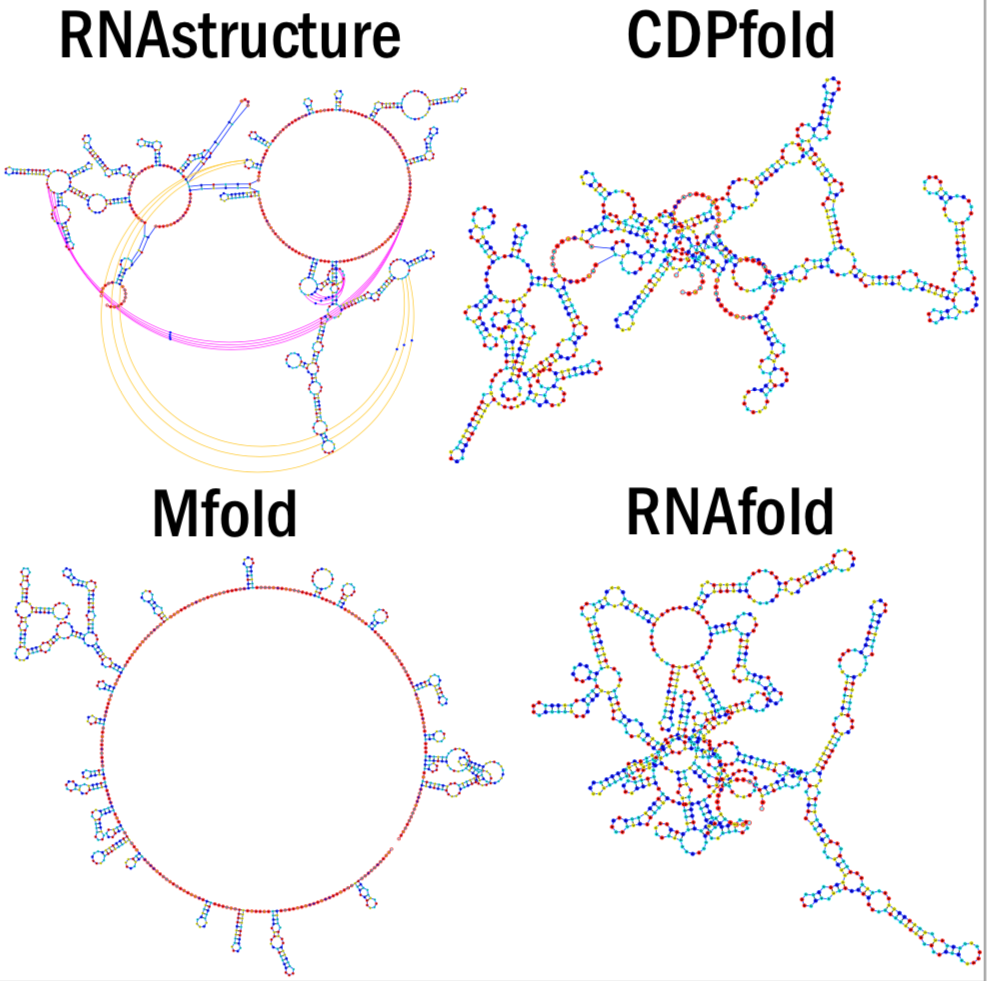
这是其他基线模型给出的预测结果
结论
深度学习的革命性意义,在于它的表现远超过去的非深度方法。因此,这类将深度学习方法应用到过去从未使用过机器学习方法来解决的领域,并与非深度方法相比较的文章,是有着很大意义的。
然而,在低处的果实已经被采摘完的今天,这样的“处女地”问题往往充满了挑战。例如,数据规模不够大,需要遵循某些规则约束,并非传统的分类问题,或是对模型可解释性有要求。在这种情况下,单纯地应用过去的深度模型是远远不够的,我们往往还需要进行某些数学上的推导,才能使模型更好地适应这些要求。
参考文章
Gregor, Karol, and Yann LeCun. "Learning fast approximations of sparse coding." Proceedings of the 27th International Conference on International Conference on Machine Learning. 2010.
往期文章:
从零上手变分自编码器(VAE)
GraphSAGE | 图神经网络到底有多强大
KDD’19 | 预测用户和商品的动态嵌入趋势
ICML&KDD 2019: 图表示学习方法的鲁棒性














 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









