







(作者:陈玓玏)
主要是看《推荐系统实践》这本书做的笔记,写得不好请见谅,一些我自己的拙见有需要讨论的可以留言,谢谢!
1. 分类及度量
1、 评分预测:预测用户对物品的评分,用RMSE和MAE做度量
2、 Top N推荐:给出个性化推荐列表,预测准确率通过准确率(推荐列表中被用户点击的商品/推荐列表中所有商品)/召回率度量(推荐列表中被用户点击的商品/用户点击的所有商品)。一般会给出不同的N,计算出一系列的准确率/召回率值,得出一个曲线。
3、 覆盖率:因为好的推荐系统是要让用户、平台及产品提供商三方满意,因此覆盖率也有必要关心,因为覆盖率会是产品提供商关心的指标。覆盖率的计算公式为:推荐给所有用户的商品的并集长度/所有商品数目。覆盖率100%的推荐系统能够保证品牌商的每一个商品至少被推荐给一个用户。也可以用熵或基尼系数来评估覆盖率,看是否每个物品的覆盖率比较平均。其中熵计算公式中的概率值是物品流行度/所有物品流行度。
4、 多样性:推荐系统必须满足用户广泛的兴趣,其公式如下:
s
(
i
,
j
)
s(i,j)
s(i,j)表示商品
i
i
i和商品
j
j
j之间的相似度,
R
(
u
)
R(u)
R(u)表示用户
u
u
u看到的推荐列表的长度。
5、 其他还有新颖性(覆盖率和新颖性应该总是成反比吧,因为覆盖率高的时候,流行度低的冷门商品也会被推荐,那么平均流行度(可以用来表征新颖度的一种指标),也就是新颖度应该就会低了)、惊喜度等指标,但是抽象,也不好界定,不详述。
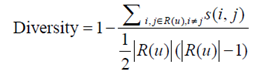
2. 基于用户行为的推荐
仅仅基于用户行为数据来设计的推荐算法称为协同过滤算法,大意是用户与网站进行交互,一起把用户不感兴趣的内容过滤掉,留下用户感兴趣的内容。
2.1 用户行为定义
关于用户行为的数据通常记录在后台日志中,并行程序会周期性地访问日志,并且把用户的浏览、点击、评论、购买等行为信息记录在Hive、Hbase等分布式数据仓库中,方便后期进行提取和分析。
用户的行为分为显性反馈行为和隐性反馈行为两种,显性反馈即用户明确表示喜欢或不喜欢,如评分。隐性反馈即有可能代表用户喜好的行为,如页面浏览时长等,可能只是因为页面内容较多,也可能是感兴趣。隐性反馈比显性反馈更隐蔽,但数据量会更大,且数据提取会更麻烦。鉴于用户行为复杂,标准化记录会比较麻烦,下图给出了用户行为的一种可行的记录方式:
就我自己的看法而言,我觉得这样统一地表示出来不是很有必要,因为权重这些的,很难人为去先行定义,如果只是离线做模型,直接把对应变量一个个取出来就好了,一般也不会是特别直观的变量,都是要经过统计的。

2.2 用户行为分析
在设计算法之前,必须要进行一些探索性数据分析的,分析结果可以对推荐算法的设计起到一些指导作用。可以分析用户的活跃度分布、商品的流行度分布、用户活跃度与物品流行度的关系(关系到给新用户推荐什么样的商品)。
2.3 基于领域的算法
基于领域的协同过滤算法是推荐系统中最基本的算法,分为两类:基于用户的协同过滤及基于商品的协同过滤。
2.3.1 基于用户的协同过滤算法
当用户需要个性化推荐时,可以先找到和他兴趣相似的用户,把这些用户感兴趣且对该用户来说足够新颖的物品推荐给他。和我们找同专业的人推荐专业书籍一个道理。
-
算法第一步:找出与用户 u u u有共同爱好的用户 v v v,然后通过Jaccard公式或余弦相似度来计算。Jaccard公式:
余弦相似度:
N ( u ) N(u) N(u)表示用户 u u u有过正反馈的物品集合,正反馈表示感兴趣。 ∣ N ( u ) ∣ |N(u)| ∣N(u)∣表示集合的长度。这种算法在用户量大的时候计算量非常大,且因为用户-物品矩阵的稀疏性(有很多用户兴趣根本没有交集),很多用户间的余弦相似度为0,导致大量不必要的计算,因此书中提出一个方案,是建立商品-用户的倒排表,把对同一个商品感兴趣的用户放入一个集合中,逐个扫描商品,如果集合中同时出现了用户 u 和 v u和v u和v,那么余弦相似度的分子加1。这样就能做到只对出现在同一集合中的用户计算余弦相似度,可以避免不必要的计算。 -
算法第二步:计算出与用户间的相似度之后,选择与用户相似度最高的 K K K个用户,把他们感兴趣的商品推荐给用户。那么接着就要计算用户对商品的兴趣度:
S ( u , K ) S(u,K) S(u,K)表示与用户 u u u相似度最高的 K K K个用户, N ( i ) N(i) N(i)是对物品i有过行为的用户集合, w u v w_{uv} wuv
是用户 u u u和用户 v v v的兴趣相似度, r v i r_{vi} rvi代表用户v对物品i的兴趣。也就是说,用户对商品的兴趣度是与用户相似的用户对商品的兴趣度的加权和,与他越相似的用户对该商品的兴趣度越大,则他对该商品的兴趣度也会越大。
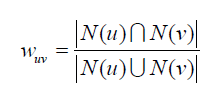
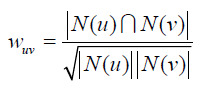
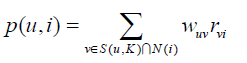
在基于用户的协同过滤算法中,参数 K K K是一个非常重要的参数,虽然和准确率及召回率没有线性关系,但也有一个比较好的区间,这个可以自己去尝试一下。但 K K K与覆盖率和新颖度关系很大, K K K越大,参考的人越多,越可能选到热门商品,覆盖率和新颖度都会降低,流行度会提高。
一种改进余弦相似度的算法:由John S. Breese提出,认为用户对热门商品的兴趣不能真正代表他们之间的相似度,对冷门产品的兴趣才能代表,因此在余弦相似度计算时加入了惩罚项,公式如下:
N
(
i
)
N(i)
N(i)是用户
u
和
v
u和v
u和v都有过正反馈的商品中,第
i
i
i个商品的热度,也就是对该商品有过正反馈的用户数,这个数字越大,对兴趣度的影响就越小。敲敲说一句,感觉公式错了log后面应该加个括号,虽然不加也能达到这个效果,但是这样log项就没任何意义了。
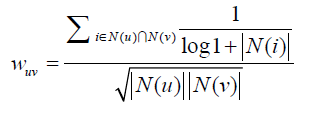
2.3.2 基于物品的协同过滤算法
该算法由亚马逊提出,弥补了基于用户的协同过滤算法在用户量增长后计算难度急剧增大的缺点,目前在业界应用最为广泛。它的核心思想是给用户推荐他和之前喜欢过的商品相似的商品。但它的做法并非计算物品属性间的相似度,而是计算喜欢该商品的用户和喜欢其他商品的用户重合度有多高,这种算法有些像上一节提到的倒排表。
算法第一步:计算物品间的相似度,公式:
N
(
i
)
N(i)
N(i)表示喜欢物品
i
i
i的用户集合,理解起来就是喜欢物品
i
i
i的用户中有多少同时喜欢物品
j
j
j。很显然,这样有一个大问题,就是热门商品大家都喜欢,那么热门商品之间的相似度会很高,就会导致买过热门商品的用户会一直收到热门商品的推荐,因此需要对这个计算方法做一点修正:
这不就是余弦相似度?不过增大分母后,至少可以让热门商品的权重远离1了。
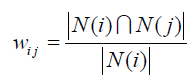
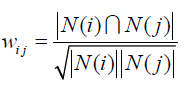
算法第二步:计算用户对物品的兴趣度:
这里
N
(
u
)
N(u)
N(u)是用户喜欢的物品的集合,
S
(
j
,
K
)
S(j,K)
S(j,K)是和物品j最相似的
K
K
K个物品的集合,
w
j
i
w_{ji}
wji是物品
j
j
j和
i
i
i
的相似度,
r
u
i
r_{ui}
rui是用户u对物品i的兴趣。也就是说,和用户感兴趣的物品越相似的物品,用户可能的兴趣度越大。

和UserCF一样,ItemCF的
K
K
K值对准确率和召回率没有明显的影响,但随着
K
K
K增大,覆盖率会降低,新颖度会降低。同样地,也要对过于活跃的用户一些惩罚,和惩罚过于热门的商品一个道理,否则一个用户买了80%的商品,这些商品之间的相似度在一定程度上都比应该有的相似度高,加入惩罚后的相似度计算公式如下:
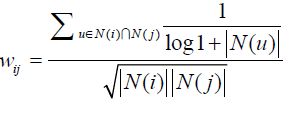
物品的相似度最后做一个归一化,但是是同类物品内部除以最大的相似度值,这样有利于提高准确率及覆盖率,原因一是不这样做的话,最大相似度较低的品类的物品会比较吃亏,即使有用户喜欢也会一直得不到推荐,因为它与它同类物品的相似度整体不如别的品类高。也就是说,归一化能够避免差异化比较大的品类得不到正确的推荐。原因二是不进行归一化时,热门商品将总是得到推荐(因为大家都会喜欢热门商品,商品间的相似度就高了)。
2.3.3 基于用户的协同过滤与基于物品的协同过滤比较
第一个性能很好理解,计算User相似度User就不能太多,计算Item相似度Item就不能太懂,第三个我是这么理解的,并不是所有用户的购买行为都会每天发生,所以用户相似度表不需要每天计算,那么用户发生新行为时,不会实时更新推荐结果,但是商品的购买用户列表是时刻在更新的,那么商品相似度的计算也应该实时更新,所以用户有新行为时,立刻就能计算出相似的商品。

3. 一个问题
UserCF和ItemCF都有用到用户 u u u对物品 i i i的兴趣 r u i r_{ui} rui这个变量,但是并没有给出计算方法?应该当通过行为先确定出来了?
参考资料:
1. 《推荐系统实践》,项亮著















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









