






1.自己动手定义函数
def adjust_learning_rate(optimizer, epoch, lr):
"""Sets the learning rate to the initial LR decayed by 10 every 2 epochs"""
lr *= (0.1 ** (epoch // 2))
for param_group in optimizer.param_groups:
param_group['lr'] = lr例子:
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=10)
plt.figure()
x = list(range(10))
y = []
lr_init = optimizer.param_groups[0]['lr']
for epoch in range(10):
adjust_learning_rate(optimizer, epoch, lr_init)
lr = optimizer.param_groups[0]['lr']
print(epoch, lr)
y.append(lr)
plt.plot(x,y)2.LambdaLR
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)- optimizer (Optimizer) – 封装好的优化器
- lr_lambda (function or list) –当是一个函数时,需要给其一个整数参数,使其计算出一个乘数因子,用于调整学习率,通常该输入参数是epoch数目;或此类函数的列表,根据在optimator.param_groups中的每组的长度决定lr_lambda的函数个数,如下报错。
- last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
例子:
optimizer = optim.SGD(params = model.parameters(), lr=0.05)
lambda = lambda epoch:epoch // 10 #根据epoch计算出与lr相乘的乘数因子为epoch//10的值
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda)3.StepLR
CLASS torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)每个step_size时间步长后使每个参数组的学习率降低。注意,这种衰减可以与此调度程序外部对学习率的其他更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
参数:
- optimizer (Optimizer) – 封装的优化器
- step_size (int) – 学习率衰减的周期
- gamma (float) – 学习率衰减的乘数因子。Default: 0.1.
- last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
例子:
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=0.05)
#即每10次迭代,lr = lr * gamma
scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
plt.figure()
x = list(range(40))
y = []
for epoch in range(40):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.plot(x,y)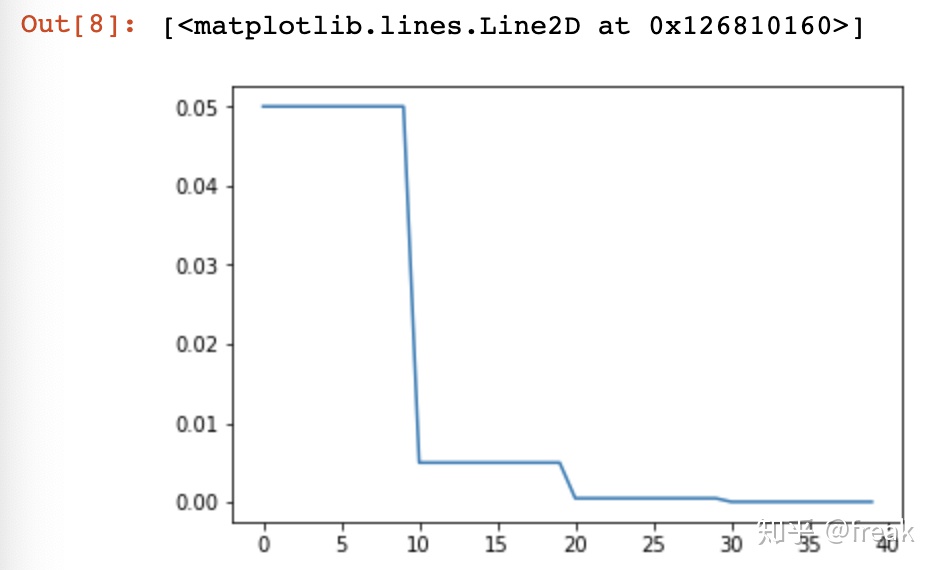
4.MultiStepLR
CLASS torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)当迭代数epoch达到某个里程碑时,每个参数组的学习率将被gamma衰减。注意,这种衰减可以与此调度程序外部对学习率的其他更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
参数:
- optimizer (Optimizer) – 封装的优化器
- milestones (list) –迭代epochs指数列表. 列表中的值必须是增长的.
- gamma (float) – 学习率衰减的乘数因子。Default: 0.1.
- last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
例子:
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=0.05)
#在指定的epoch值,如[10,15,25,30]处对学习率进行衰减,lr = lr * gamma
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[10,15,25,30], gamma=0.1)
plt.figure()
x = list(range(40))
y = []
for epoch in range(40):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.plot(x,y)5.ExponentialLR
CLASS torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)每个epoch都对每个参数组的学习率进行衰减。当last_epoch=-1时,将初始lr设置为lr。
参数:
- optimizer (Optimizer) – 封装的优化器
- gamma (float) – 学习率衰减的乘数因子
- last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
例子:
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=0.2)
#即每个epoch都衰减lr = lr * gamma,即进行指数衰减
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.2)
plt.figure()
x = list(range(10))
y = []
for epoch in range(10):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.plot(x,y)6.CosineAnnealingLR
CLASS torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)参数:
- optimizer (Optimizer) – 封装的优化器
- T_max (int) – 迭代的最大数量
- eta_min (float) – 最小学习率 Default: 0.
- last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
例子:
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params = model.parameters(), lr=10)
#根据式子进行计算
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=2)
plt.figure()
x = list(range(10))
y = []
for epoch in range(10):
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[0])
y.append(scheduler.get_lr()[0])
plt.plot(x,y)7.ReduceLROnPlateau(动态衰减lr)
CLASS torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)当评价指标停止改进时,降低学习率。一旦学习停滞不前,模型通常会从将学习率降低2-10倍中获益。这个调度器读取一个度量量,如果在“patience”时间内没有看到改进,那么学习率就会降低。
参数:
- optimizer (Optimizer) – 封装的优化器
- mode (str) – min, max两个模式中一个。在min模式下,当监测的数量停止下降时,lr会减少;在max模式下,当监视的数量停止增加时,它将减少。默认值:“分钟”。
- factor (float) – 学习率衰减的乘数因子。new_lr = lr * factor. Default: 0.1.
- patience (int) – 没有改善的迭代epoch数量,这之后学习率会降低。例如,如果patience = 2,那么我们将忽略前2个没有改善的epoch,如果loss仍然没有改善,那么我们只会在第3个epoch之后降低LR。Default:10。
- verbose (bool) – 如果为真,则为每次更新打印一条消息到stdout. Default:
False. - threshold (float) – 阈值,为衡量新的最优值,只关注显著变化. Default: 1e-4.
- threshold_mode (str) – rel, abs两个模式中一个. 在rel模式的“max”模式下的计算公式为dynamic_threshold = best * (1 + threshold),或在“min”模式下的公式为best * (1 - threshold)。在abs模式下的“max”模式下的计算公式为dynamic_threshold = best + threshold,在“min”模式下的公式为的best - threshold. Default: ‘rel’.
- cooldown (int) – 减少lr后恢复正常操作前等待的时间间隔. Default: 0.
- min_lr (float or list) – 标量或标量列表。所有参数组或每组的学习率的下界. Default: 0.
- eps (float) – 作用于lr的最小衰减。如果新旧lr之间的差异小于eps,则忽略更新. Default: 1e-8.
import torchvision.models as models
import torch.nn as nn
model = models.resnet34(pretrained=True)
fc_features = model.fc.in_features
model.fc = nn.Linear(fc_features, 2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(params = model.parameters(), lr=10)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
inputs = torch.randn(4,3,224,224)
labels = torch.LongTensor([1,1,0,1])
plt.figure()
x = list(range(60))
y = []
for epoch in range(60):
optimizer.zero_grad()
outputs = model(inputs)
#print(outputs)
loss = criterion(outputs, labels)
print(loss)
loss.backward()
scheduler.step(loss)
optimizer.step()
lr = optimizer.param_groups[0]['lr']
print(epoch, lr)
y.append(lr)
plt.plot(x,y)8.CyclicLR
CLASS torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)循环学习率策略会在每批batch数据之后改变学习率。该类的step()函数应在使用批处理进行训练后调用。
该类有三个内置策略:
- “triangular”:一个基本的三角形周期w,无振幅缩放
- “triangular2”:一种基本的三角形周期,每个周期的初始振幅乘以一半。
- “exp_range”:在每次循环迭代时,初始振幅按**(循环迭代)缩放的循环。
This implementation was adapted from the github repo:bckenstler/CLR参数:
- optimizer (Optimizer) – 封装的优化器
- base_lr (float or list) –初始学习率,即各参数组在循环中的下界。
- max_lr (float or list) – 各参数组在循环中的学习率上限。在功能上,它定义了周期振幅(max_lr - base_lr)。任意周期的lr是base_lr和振幅的某种比例的和;因此,根据缩放函数,实际上可能无法达到max_lr。
- step_size_up (int) – 在周期的上升部分中,训练迭代的次数. Default: 2000
- step_size_down (int) – 在一个周期的下降部分的训练迭代次数。如果step_size_down为None,则将其设置为step_size_up. Default: None
- mode (str) – {triangular, triangular2, exp_range}三个模式之一.值对应于上面详细说明的策略。如果scale_fn不为None,则忽略该参数. Default: ‘triangular’
- gamma (float) – 在' exp_range '缩放函数中的常量 :计算公式为gamma**(循环迭代)。Default: 1.0
- scale_fn (function) – 由一个参数lambda函数定义的自定义缩放策略,其中对于所有x >= 0, 0 <= scale_fn(x) <= 1。如果指定,则忽略“mode”. Default: None
- scale_mode (str) – {‘cycle’, ‘iterations’}.定义scale_fn是根据循环数计算还是根据循环迭代(从循环开始的训练迭代)计算. Default: ‘cycle’
- cycle_momentum (bool) –
如果为True,momentum与“base_momentum”和“max_momentum”之间的学习率成反比。 . Default: True - base_momentum (float or list) – 初始momentum是各参数组在周期中的下界. Default: 0.8
- max_momentum (float or list) – 各参数组在周期中的最大momentum边界。在功能上,它定义了周期振幅(max_momentum - base_momentum)。任意周期的momentum等于最大动量与振幅的比例之差;因此,根据缩放函数,实际上可能无法达到base_momentum. Default: 0.9
- last_epoch (int) – 最后一批batch的索引。此参数用于恢复训练工作。因为step()应该在每个批处理之后调用,而不是在每个epoch之后调用,所以这个数字表示计算的批处理总数,而不是计算的epoch总数。当last_epoch=-1时,调度将从头开始. Default: -1
9. 针对模型的不同层设置不同的学习率
当我们在使用预训练的模型时,需要对分类层进行单独修改并进行初始化,其他层的参数采用预训练的模型参数进行初始化,这个时候我们希望在进行训练过程中,除分类层以外的层只进行微调,不需要过多改变参数,因此需要设置较小的学习率。而改正后的分类层则需要以较大的步子去收敛,学习率往往要设置大一点以 resnet101 为例,分层设置学习率。
model = torchvision.models.resnet101(pretrained=True)
large_lr_layers = list(map(id,model.fc.parameters()))
small_lr_layers = filter(lambda p:id(p) not in large_lr_layers,model.parameters())
optimizer = torch.optim.SGD([
{"params":large_lr_layers},
{"params":small_lr_layers,"lr":1e-4}
],lr = 1e-2,momenum=0.9)10.手动设置lr衰减区间
def adjust_learning_rate(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
for epoch in range(60):
lr = 30e-5
if epoch > 25:
lr = 15e-5
if epoch > 30:
lr = 7.5e-5
if epoch > 35:
lr = 3e-5
if epoch > 40:
lr = 1e-5
adjust_learning_rate(optimizer, lr)参考博文:
pytorch中的学习率调整函数 - 慢行厚积 - 博客园www.cnblogs.com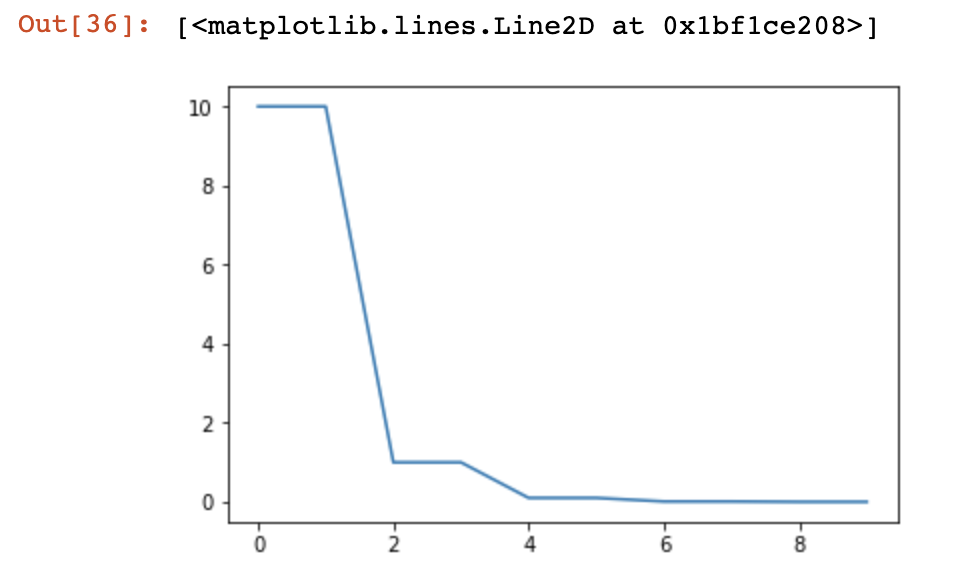















 4799
4799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









