






作者:Jessica Yung
日期:06.2018
标签:Machine Learning, Programming
原文:http://www.jessicayung.com/numpy-arrays-memory-and-strides/
Numpy怎么这么快? 在这篇文章中,我们将了解Numpy的ndarray是如何存储的,以及它是如何通过Numpy函数使用strides来运算的。
理解ndarray
NumPy ndarray是一个N维数组。 您可以如此创建:
X = np.array([[0,1,2],[3,4,5]], dtype='int16')这些数组存储着相同大小的元素的同质数组。 也就是说,数组中的所有项都具有相同的数据类型且大小相同。 例如,您不能在同一个ndarray中放入字符串'hello'和整数16。
Ndarrays有两个关键特征:shape和dtype。
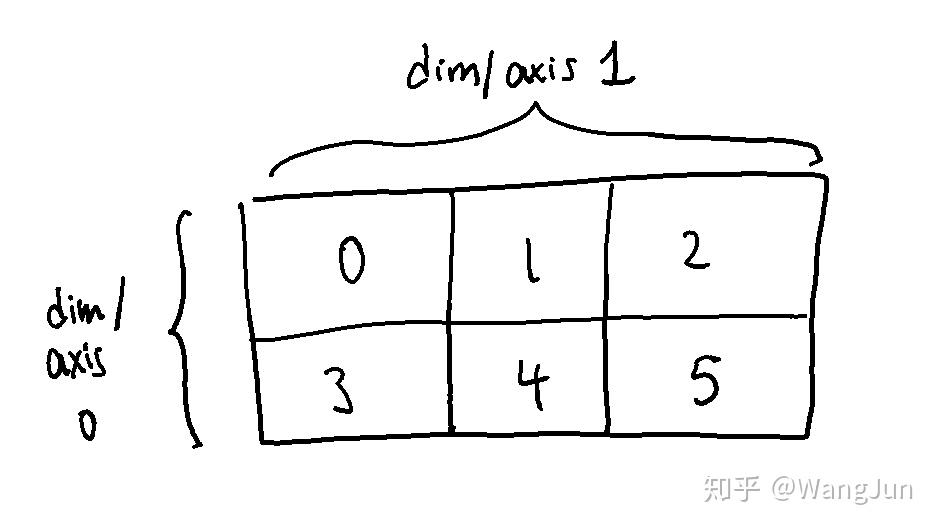
shape描述了数组的每个维度的长度,即将数组计为一个元素的情况下,在该维度中的元素计数。 例如,上面的阵列X具有形状(2,3)。 我们可以像这样想象它:
dtype(数据类型)定义元素大小。 例如,每个int16项的大小为16位,即16/8 = 2个字节。 (一个字节等于8位。)因此X.itemsize为2。具体的dtype是可选的。
NumPy数组在内存中如何存储
Numpy数组存储在单个连续(连续)的内存块中。 关于内存有两个关键概念:维度(dimensions)和步幅(strides)。
Strides是遍历数组时每个维度中需要步进的字节数。
让我们看看前面描述的数组X的内存是什么样的:

计算步幅:如果要在维度0方向上移动到下一个数组的相同位置,则需要移动三个元素。 每个元素的大小为2个字节。 因此,维度0中的步幅是2个字节x3个元素= 6个字节。
同样,如果要在维度1中移动一个单位,则需要移动1个元素。 因此,维度1中的步幅是2个字节x 1个元素= 2个字节。 最后一个维度的步幅始终等于元素大小。
我们可以使用.strides检查数组的步幅:
>>> X.strides
>>> (6,2)我们为何关心步幅?
首先,许多Numpy函数步幅进行加速。 有许多例子包括包括整数切片(例如X [1,0:2])和形状传播。 了解这些有助于我们更好地了解Numpy的工作方式。
其次,我们可以直接使用步幅来加快自己的代码。 这对于机器学习中的数据预处理特别有用。
示例:机器学习中更快的数据预处理
例如,我们可能希望使用前十天的收盘价预测股票的收盘价。 因此,我们想要创建一个如下所示的X特征数组:
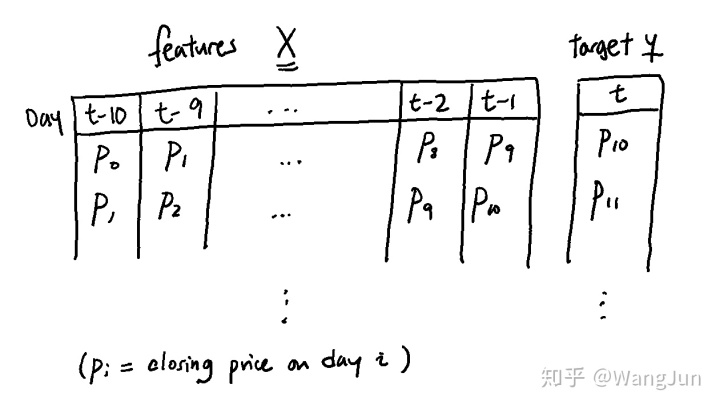
一种方法是按照天数循环依次复制价格。 更快的方法是使用as_strided,但这可能有风险,因为它不会检查您是否正在访问数组中的内存。 我建议你在使用as_strided时使用writeable = False选项,这可以至少确保你不会写入原始数组。
第二种方法明显快于第一种方法:
import numpy as np
from timeit import timeit
from numpy.lib.stride_tricks import as_strided
# Adapted from Alex Rogozhnikov (linked below)
# Generate array of (fake) closing prices
prices = np.random.randn(100)
# We want closing prices from the ten days prior
window = 10
# Create array of closing prices to predict
y = prices[window:]
def make_X1():
# Create array of zeros the same size as our final desired array
X1 = np.zeros([len(prices) - window, window])
# For each day in the appropriate range
for day in range(len(X1)):
# take prices for ten days from that day onwards
X1[day,:] = prices[day:day+window]
return X1
def make_X2():
# Save stride (num bytes) between each item
stride, = prices.strides
desired_shape = [len(prices) - window, window]
# Get a view of the prices with shape desired_shape, strides as defined, don't write to original array
X2 = as_strided(prices, desired_shape, strides=[stride, stride], writeable=False)
return X2
timeit(make_X1) # 56.7 seconds
timeit(make_X2) # 7.7 seconds, over 7x faster!如果想了解如何让你的代码跑得更快,我建议阅读Nicolas Rougier的指南 ‘From Python to Numpy’ 。其中描述了如何向量化你的代码和问题,以充分利用Numpy,获得速度提升。
引用
- Nicolas Rougier’s ‘From Python to Numpy’: a practical guide on migrating your code from raw Python to Numpy. Focuses on how to vectorise your code and your problems.
- Numpy ndarray documentation
- Alex Rogozhnikov’s Numpy Tips and Tricks tutorial
- Scipy Cookbook (Numpy section)















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









