





这是薰风读论文的第 7 篇投稿,本文的计算有点多,但要耐心看完
薰风说
虽然MobileNets[1]在结构上与VGGNet[2]类似,属于简单的流线型架构。但其使用深度可分离卷积层替换之前的全卷积层,以达到压缩参数数量并轻量化网络这一目标。因此,我将其作为网络压缩方法的一部分。
MobileNet除了第一层为全卷积层,其余层均为深度可分离卷积。不同于Deep Compression[3],因为网络在定义时结构简单,因此我们可以简单地搜索网络的拓扑结构,从头直接训练出一个效果很好的轻量化网络。
关于Deep Compression,可以阅读下文。
薰风初入弦:薰风读论文:Deep Compression 神经网络压缩经典之作zhuanlan.zhihu.com
本文的目的旨在详尽的推算深度可分离卷积的“效率”,包括它就近节省了多少内存,为何节省。以及其运行速度到底是快还是慢(有趣的是,答案是又快又慢)。
一、引言 Why MobileNet?
随着人工智能产品化压力逐渐变大,训练更加高效的神经网络也逐渐成为了人们关注的焦点。抛开现在基于搜索的架构(NAS)不谈,设计轻量级模型的要求主要通过:
- 减少参数数量
- 量化参数,减少每个参数占用内存
而MobileNet就是用来解决第1个问题的,采用的方法叫做深度可分离卷积。
上述内容都是些老生常谈的内容,人人都知道这些MobileNet占内存少,都知道压缩模型。但是,不知道有多少人注意到一个问题?
实际程序运行中,MobileNet往往起不到论文所述“加速”的作用,相反,使用了MobileNet后,模型的计算速度反而变慢了。
这里我将结合论文,程序运行结果进行分析,还原一个真实的MobileNet。
二、算法概述
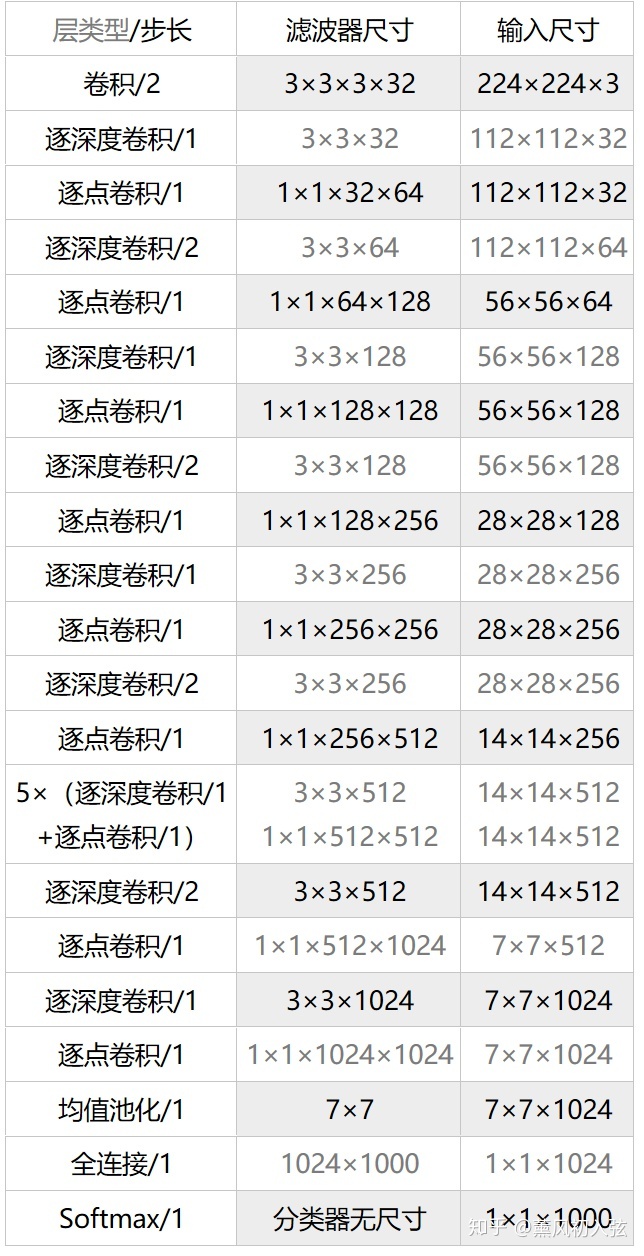
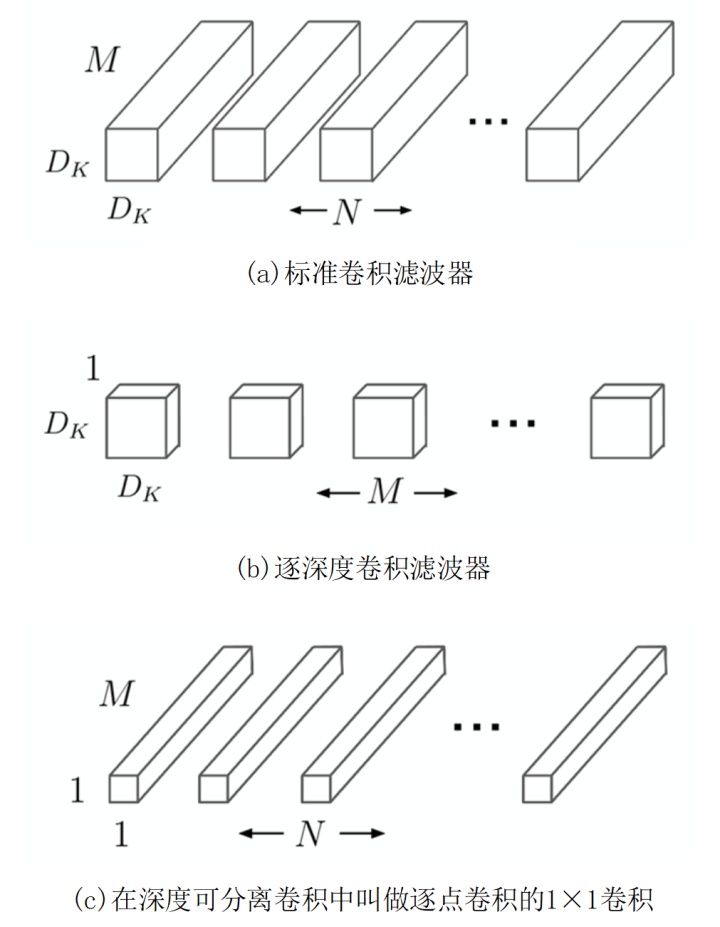
MobileNet结构的定义如图 1 所示,除了最后的全连接层直接进行softmax分类,其余所有层之后都是批量正则化(BN层)和作为非线性激活函数的线性整流函数(ReLU层)。
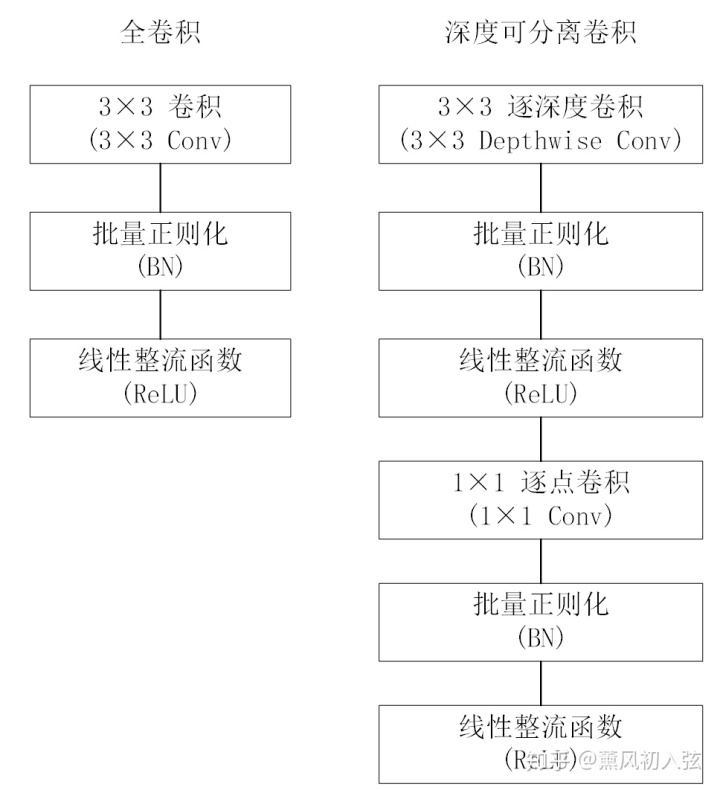
图 2 比较了全卷积和深度可分离卷积(都跟着BN层和ReLU层)。通过有步长的逐深度卷积和第一层卷积,都能对图片进行空间上的下采样。最后一个平均池化层在全连接层之前,将特征图的空间分辨率降为1x1。将逐深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)算为不同的层地话,MobileNet有28层。
其实,只要你搞懂了什么叫深度可分离卷积,MobileNet(V1)的精髓就已经被你掌握了。
三、深度可分离卷积
MobileNet模型的核心就是深度可分离卷积,它是因式分解卷积的一种。
具体地,深度可分离卷积将标准化卷积分解为逐深度卷积(depthwise convolution)和逐点1x1卷积(pointwise convolution)。对于MobileNets,逐个深度卷积将单个滤波器应用到每一个输入通道。然后,逐点卷积用1x1卷积来组合不同深度卷积的输出。在一个步骤,一个标准的卷积过程将输入滤波和组合成一组新的输出。深度可分离卷积将其分成两层,一层用于滤波,一层用于组合。这种分解过程能极大减少计算量和模型大小。图 3 展示了如何将一个标准卷积分解为深度卷积和1×1逐点卷积。
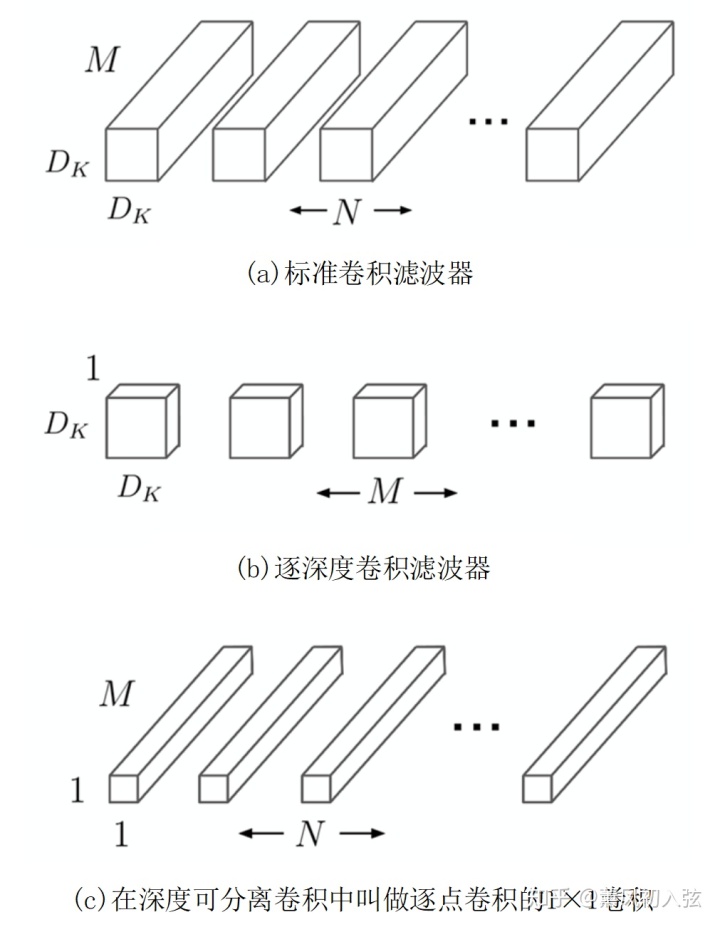
3.1 标准卷积的参数量与计算量
传统的全卷积滤波器使用一个和输入数据具有相同通道数目的卷积核在整个特征图通道上进行乘法累加运算后,得出一个数值作为结果,单次的计算量为
一个卷积核处理输入数据时的计算量为(有零填充):
其中,
假设在某个全卷积层使用
如果使用逐个深度卷积层的卷积核,则首先处理数据的是一组二维的卷积核(即卷积核通道数为1),每个二维卷积核只处理输入特征图的一个通道,这一组二维卷积核的数量是和输入通道数相同的。在逐个使用通道卷积处理之后,再使用全卷积中三维的1×1卷积核来处理之前输出的特征图,使得最终输出的特征图变成1×1卷积指定的通道数量。
对于一个传统的全卷积层,输入数据是维度为
假设输入、输出的特征图,以及卷积核在空间上都是正方形,则传统卷积层由卷积核
假设卷积步长为1,且由于零填充输入、输出特征图在空间大小上保持不变,那么传统卷积操作的输出特征图谱为:
由之前得到的卷积计算定义,该运算的计算复杂度为
MobileNet模型进行压缩的出发点,就是设法破除这些项之间的相互关系。
3.2 深度可分离卷积的参数量与计算量
更进一步来说,其使用深度可分离卷积来破坏输出通道的数量和卷积核大小的相互作用。
标准的卷积运算,每次运算在滤波的同时,都涉及了所有输入通道特征的组合,从而产生新的特征。但是,滤波和组合步骤可以通过使用因式分解卷积(包括深度可分离卷积)分为两个步骤,以显著降低计算成本。
深度可分离卷积由两层构成:
- 逐层卷积
- 逐点卷积
我们使用逐层卷积对每个输入通道(输入特征图的深度)执行单个滤波器卷积。逐点卷积(1x1卷积)用来创建逐深度卷积层的线性组合。MobileNet对两层卷积层都使用了批量正则化(Batch Normalization , BN)和线性整流函数(ReLU)作为非线性激活函数。
逐层卷积可以被写作以下形式(每个输入通道一个滤波器):
逐层卷积相对于标准的卷积效率极高,但他只是给输入通道做了个滤波,而不能结合各个通道的特征图生成新的特征。
所以为了生成这些新的特征,一个额外的,由1x1卷积构成的逐点卷积被运用在了MobileNet中。
深度可分离卷积,就是上述两种卷积层操作的组合。
MobileNets使用3x3的深度可分离卷积比标准的卷积减少了8-9倍的计算复杂度,而与此同时准确率只减少了一点点。
空间维度的因式分解不会节省大量的计算复杂度,因为相比于其他直接做因式分解的模型[3][4]深度可分离卷积计算复杂度很小。
四、算法效果分析
由之前的分析,若只考虑浮点数运算,则一组二维卷积核完成逐深度卷积的运算量为:
而随后的逐点1×1卷积的浮点运算量为:
综上,一次深度可分离卷积的总计算量为:
所以,深度可分离卷积与传统全卷积的总计算量之比为:
举一个具体的例子,给定输入图像为3通道的224×224图像,VGG16网络的第三个卷积层conv2_1输入的是尺寸为112的特征图,通道数为64,卷积核尺寸为3,卷积核个数为128,传统卷积运算量就是:
如果将传统的全卷积替换为逐深度卷积加上1*1的逐点卷积,计算量为:
可见,在这一层里,MobileNet所采用的卷积方式的计算量与传统卷积计算量的比例为:
同理,我们也可以计算一个深度可分离卷积层相对于全卷积层的压缩比。传统的全卷积层由
而对于深度可分离卷积,逐深度卷积由个的二维卷积核组成,因此参数总量为
之后紧跟的1×1逐点卷积的参数量则为
所以,再输入输出通道数相同的情况下,使用深度可分离卷积替换全卷积的压缩比为:
可以发现,这个压缩比与计算量的压缩比是相同的,在深度网络中,
五、速度的迷思
而在速度方面,经过大量实验,我发现在算力足够的GPU平台上,MobileNet不会带来任何速度上的提升(有时甚至是下降的),然而在计算能力有限的平台上,MobileNet能让速度提升三倍以上。
注:这个速度的计算方法是随机生成一个224x224x3的tensor,送入网络进行前向计算,多次计算计时并取平均值。
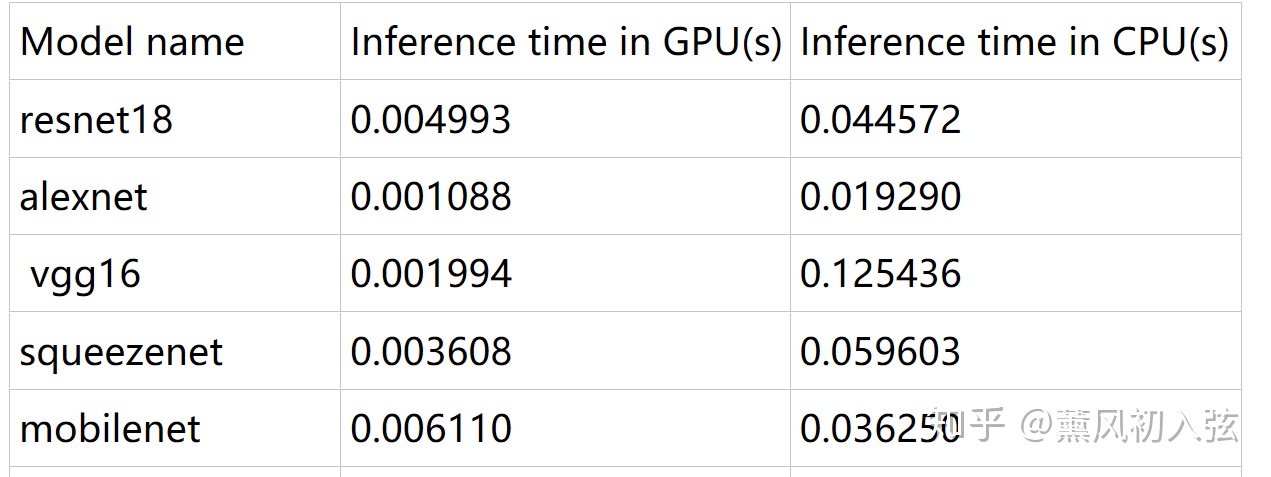
那么,为什么GPU上表现乏力的GPU,到CPU上反而一骑绝尘了呢?
我们回想一下,什么叫深度可分离卷积。
深度可分离卷积将一个标准卷积分割成了两个卷积(逐深度,逐点),因此减小了参数量,对应也减小了总计算量。
好的,在上面的话中,我们可以发现一个有趣的事实:深度可分离卷积的总计算量变小了,但深度可分离卷积的层数变多了。
而结合我们对GPU和CPU的认识:GPU是并行处理大规模数据(矩阵内积)的运算平台,而CPU则倾向于对数据串行计算(一个一个算)。
因此,若GPU的显存足够大(干脆假设无限大好了),因为每层的计算都可以并行一次处理,则此时总运算时间的主导因素是网络的层数。
而对于缺乏并行能力的CPU,总的运算时间的主导因素则是总计算量有关。
正因如此,才会出现这个乍一看神奇的现象。实际上,乍一看神奇的东西,背后的道理往往并不会太难。















 1753
1753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









