







DeepLab V3
DeepLab V3在v1和v2的基础上做了以下几点改进:
(1)改进ASPP模块:加入了BN层,同时尝试串行和并行两种方式
(2)去除了CRF
(3)将图像级特征融合到ASPP模块
注:当应用一个速率非常大的 3 × 3 空洞卷积时,由于图像边界效应,它无法捕获远程信息,会退化为 1 × 1 卷积,因此建议合并图像级特征 进入 ASPP 模块。
多尺度预测常用方法
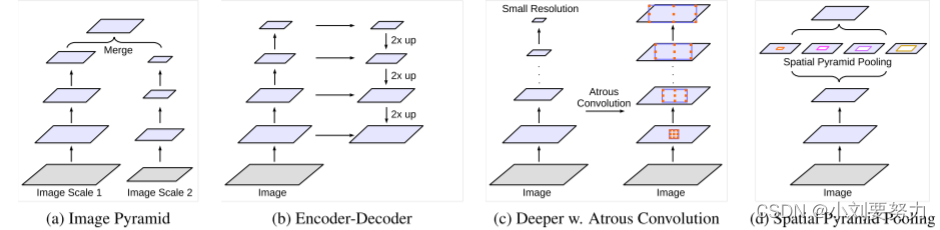
(2)图(b):编码解码器结构
(3)图(c):原始网络带有空洞卷积
(4)图(d):空间金字塔池化
调整后的ASPP模块
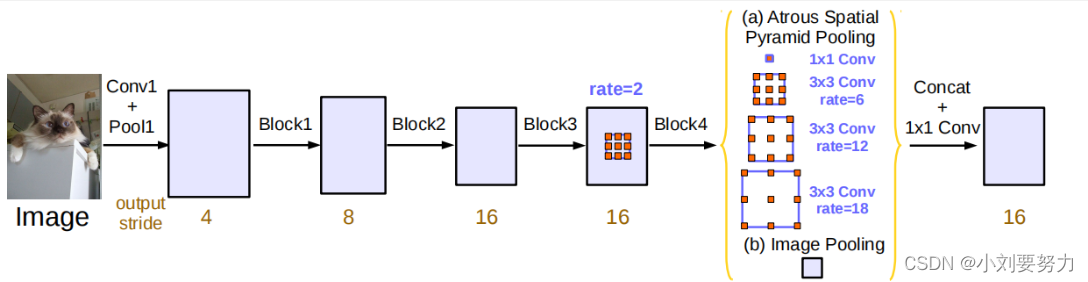
(1)由于rate过大,会退化成1 × 1 卷积,因此取消了V2中rate=24的卷积,使用了1 × 1 卷积
(2)融入了图像级特征
(3)文中提到在空洞卷积中使用了BN层
ASPP的代码实现(pytorch)
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class ASPP_module(nn.Module):
def __init__(self, inplanes, planes, os):
super(ASPP_module, self).__init__()
# 输入ASPP的特征图是原图的1/8或1/16时,dilate rate不同
if os == 16:
dilations = [1, 6, 12, 18]
elif os == 8:
dilations = [1, 12, 24, 36]
#ASPP模块
self.aspp1 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=1, stride=1, padding=0, dilation=dilations[0], bias=False),
nn.BatchNorm2d(planes),
nn.ReLU())
self.aspp2 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1, padding=dilations[1], dilation=dilations[1],
bias=False),
nn.BatchNorm2d(planes),
nn.ReLU())
self.aspp3 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1, padding=dilations[2], dilation=dilations[2],
bias=False),
nn.BatchNorm2d(planes),
nn.ReLU())
self.aspp4 = nn.Sequential(
nn.Conv2d(inplanes, planes, kernel_size=3, stride=1, padding=dilations[3], dilation=dilations[3],
bias=False),
nn.BatchNorm2d(planes),
nn.ReLU())
# 图像级特征
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(512, 256, 1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
self.conv1=nn.Conv2d(1280,256,1,bias=False)
self.bn1= nn.BatchNorm2d(256)
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.global_avg_pool(x)
# 对x5双线性插值方式进行上采样得到与x1-x5的尺寸,从而方便拼接
x5 = F.interpolate(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x=self.conv1(x)
x=self.bn1(x)
print("x.size:",x.size())
return x
DeepLab V3+
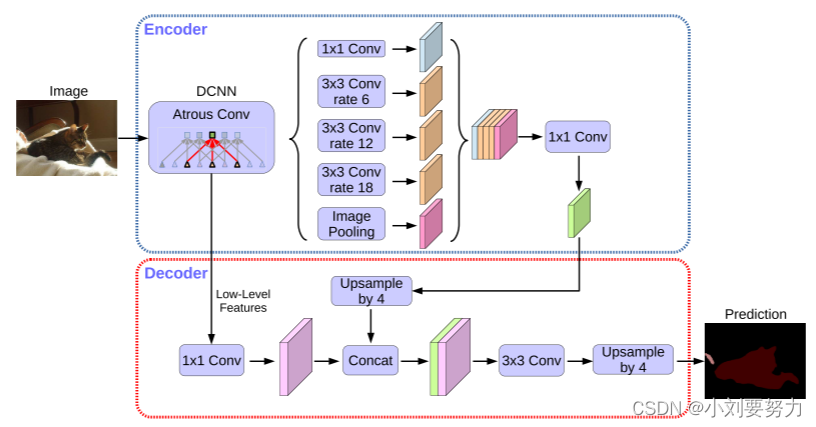
基于V3进行了改进:
(1)使用编码-解码器结构(非对称)
(2)将深度可分离卷积应用于 Atrous 空间金字塔池和解码器模块
深度可分离卷积
深度可分离卷积=深度卷积+逐点卷积

如上图所示,输入图片尺寸为12× 12× 3,每个5× 5× 1的卷积核对应输入图像的每一个通道,得到3个8× 8× 1的输出,拼接后得到8× 8×3的结果。
(2)逐点卷积:
设置256个1× 1× 3的卷积核,对深度卷积的输出再进行卷积操作,最终会得到的8× 8× 256的输出.
深度可分离卷积代码:
class SeparableConv2d_same(nn.Module):
def __init__(self, inplanes, planes, kernel_size=3, stride=1, dilation=1, bias=False):
super(SeparableConv2d_same, self).__init__()
#深度卷积
self.conv1 = nn.Conv2d(inplanes, inplanes, kernel_size, stride, 0, dilation,
groups=inplanes, bias=bias)
#逐点卷积
self.pointwise = nn.Conv2d(inplanes, planes, 1, 1, 0, 1, 1, bias=bias)
def forward(self, x):
x = fixed_padding(x, self.conv1.kernel_size[0], dilation=self.conv1.dilation[0])
x = self.conv1(x)
x = self.pointwise(x)
return x
DeepLab V3+结构
DeepLab系列论文小结
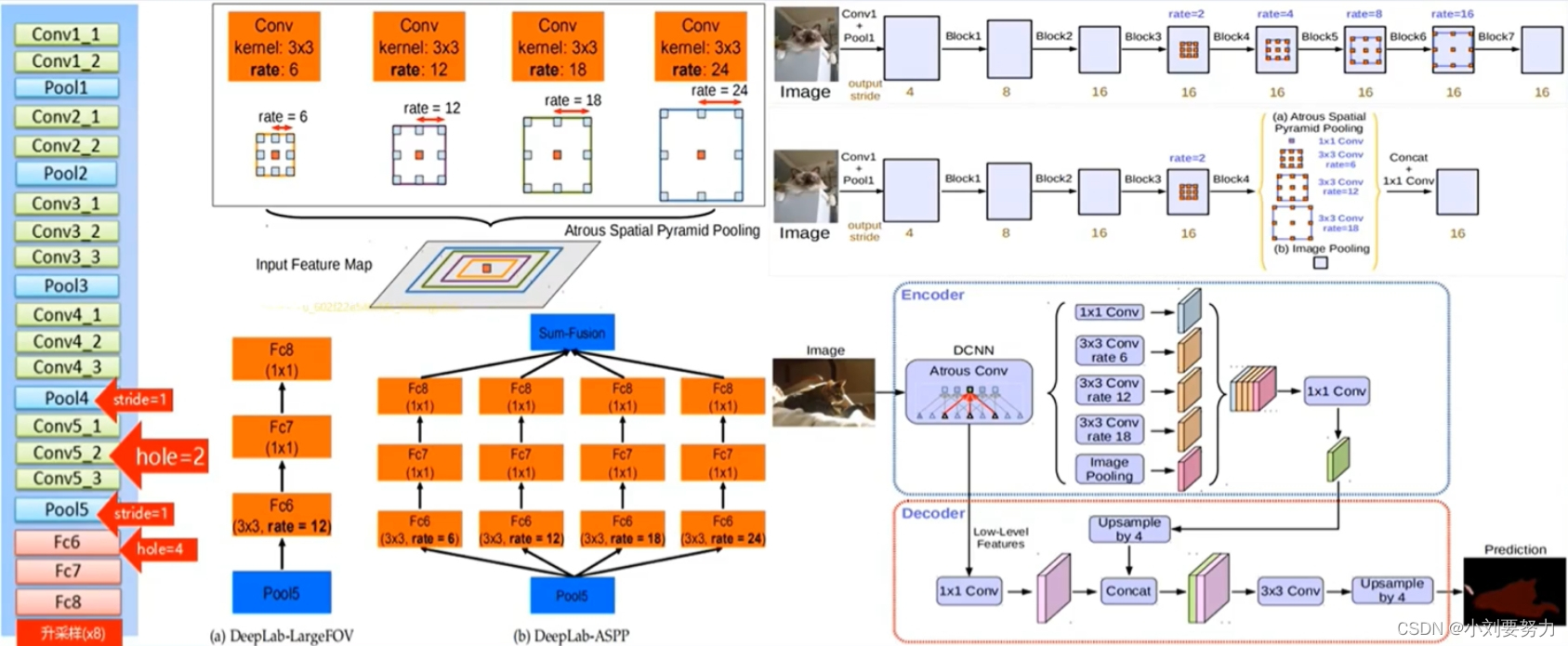
V1:修改经典分类网络(VGG16),将空洞卷积应用于模型中,试图解决分辨率过低及提取多尺度特征问题,最后做CRF处理
V2:设计ASPP模块,将空洞卷积的性能发挥到最大,沿用VGG16作为主干网络,尝试用ResNet101进行对比实验,用CRF做后处理
V3:以ResNet为主干网络,设计了一种串行和并行的DCNN网络,微调ASPP模块,取消CRF
V3+:以ResNet或Xception为主干网络,结合编码解码器结构设计了一种新的算法模型,以V3作为编码器结构,另外设计了解码器结构,取消CRF
从V1-V3+的结构图如下图所示:















 5601
5601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









