






本文是对 ACL 2020 最佳论文 「Beyond Accuracy: Behavioral Testing of NLP Models with CheckList」 的详细解读。
1 背景
训练 NLP 模型的一个主要目标是提升其「泛化性」。当前的一种标准化的评估方法是将数据集划分为「训练-验证-测试」集,在测试集上评估模型的准确率。这种评估方式存在着一定的局限性,如测试集数据并不全面,和训练集存在同样的偏差。此外,将模型的表现总结为单个指标,很难去找到模型失败的具体原因,也就无法去修复它。
近年来,大量的其他评估方法被提出,但是这些方法基本都专注于具体的任务(如问答)或者是单一的能力(如鲁棒性),并不能提供模型评估的全面指导。在软件工程领域,对于复杂的软件系统通常采用「行为测试」的方法,通过验证输入输出行为来测试一个系统的不同的能力。
本研究借鉴了这一思想,提出了 「CheckList」,一种用于全面测试 NLP 模型行为的评估方法及配套工具。CheckList 通过提供一个「语言学能力」列表告诉用户要测试的内容,其适用于大部分的任务,同时还给出了三种不同的「测试类型」,来满足不同能力的特定行为需求。最后,原文中的 CheckList 实现还包括了多种「抽象」以帮助用户生成大量的测试用例。
2 CheckList 详解
CheckList 遵循行为测试中的“「将实现与测试分离」” 的原则,将模型看作一个黑盒子,从而提升评估方法的通用性。下图给出了 CheckList 的一个使用案例,其评估的是一个情感分析模型,以矩阵的形式呈现,矩阵的行代表「模型的能力」,矩阵的列代表「测试的类型」,我们通过测试用例去填充这个矩阵。下面将围绕这个案例说明 CheckList 的这三个要素。
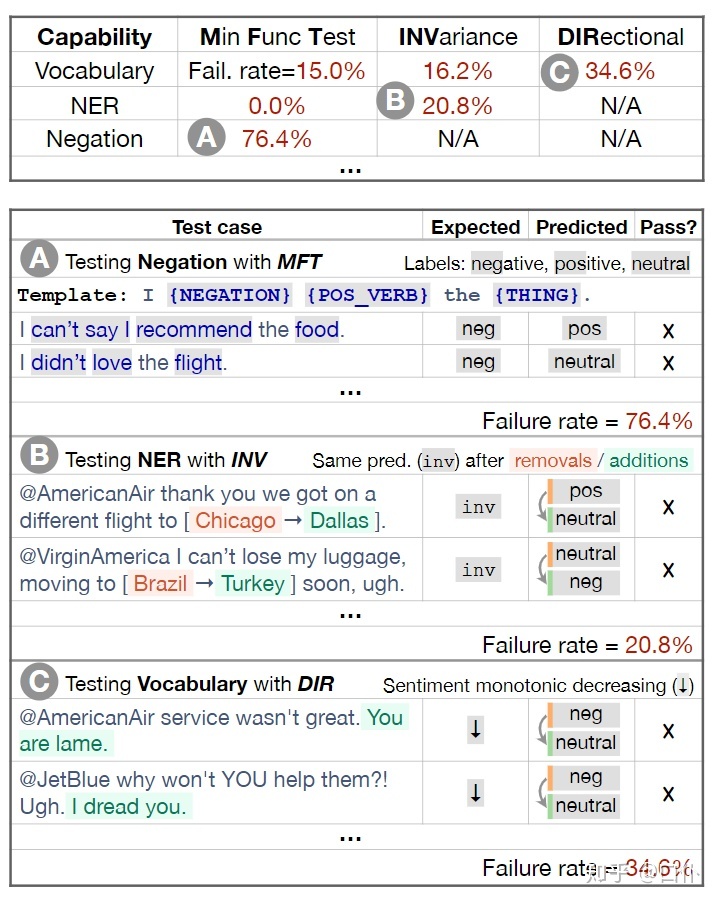
2.1 能力
不同于现代 NLP 模型常常仅关注特定的任务,CheckList 希望去评估一个模型的多方面能力,这些能力有的是模型通用的,有的则是面向特定的任务或领域。原文中列举了如下的一些通用性能力:
- 「Vocabulary+POS」:是否掌握任务相关的词汇及词性
- 「Taxonomy」:是否理解同义词、反义词
- 「Robustness」:是否能够应对拼写错误和不相关的变化
- 「NER」:是否能够识别相关的命名实体
- 「Negation」:是否理解否定词
- 「Coreference」:是否理解指代关系
- 「Semantic Role Labeling」:是否理解各种角色
- 「Logic」:是否能够处理对称性、前后一致性以及连接词
有时还需要根据具体任务去添加其他特定的能力。上面的案例中分别通过不同的测试类型评估了模型的 Negation、NER 和 Vocabulary 能力。
2.2 测试类型
对于每种能力,CheckList 给出了三种可能的测试类型:最小功能测试、不变性测试以及定向期望测试。
「最小功能测试」(MFT)受启发于软件工程领域的单元测试,通过大量简单但是具有针对性的样例对目标能力进行测试。在上面的案例 A 中,通过模板(下一节介绍)生成了具有否定词的测试用例来测试模型的否定能力。
「不变性测试」(INV)和 「定向期望测试」(DIR)都受启发于软件蜕变测试,INT 对模型输入做一些不影响结果的轻微变化,期望模型的输出保持不变;而 DIR 则是对原有数据做少许改动,期望模型的输出朝一个期望的方向变化。
在上面的案例(B & C)中,对于 NER 能力使用了 INV 进行测试,通过替换地名相关的命名实体检测模型的输出是否发生变化;对于词汇能力则使用 DIR 进行了测试,通过加入消极的短语,判断模型是否不会变得更积极。对于 INV 和 DIR,其可以基于「无标签数据」进行测试,因为我们关注的不是真实结果,而是加入扰动前后输出结果的变化关系。
2.3 生成测试用例
CheckList 通过提供一系列的抽象来帮助用户快速地生成大规模「测试用例」,这些用例可以直接创造,也可以通过改动已有数据得到。原文介绍了两种抽象方式:模板和扩展模板。
「模板」提供了一个通用的句式,其中的成分只给出其词性,每个成分下用户可以创造一系列的可选词语,系统会基于笛卡尔积(即所有可能的组合)生成测试用例。在上面的案例中,I {NEGATION} {POS_VERB} the {THING} 就是一个模板,其中 {NEGATION}={didn’t, can’t say I, ...},{POS_VERB}={love, like, ...},{THING}={food, flight, service, ...}。
「扩展模板」。基于模板生成的用例需要依赖用户为每个缺失成分添加可选词语列表,CheckList 还提供了一种生成词语的方式,用户可以将一个模板的某个部分遮挡起来,CheckList 会自动为被遮罩的部分生成一些可选词语(基于 「RoBERTa」 实现),用户可以将这些词语过滤为特定的词语列表(如积极、消极、中性词语)用于多个测试,有时候生成的词语可能不需要过滤。RoBERTa 的生成建议也可以和 WordNet 结合在一起输出一些特定的近义词或反义词列表。此外,原文表示还提供了一些现成的常用填充词语,如姓名和地点的命名实体。下图给出了一个基于 MLM 的模板的例子:
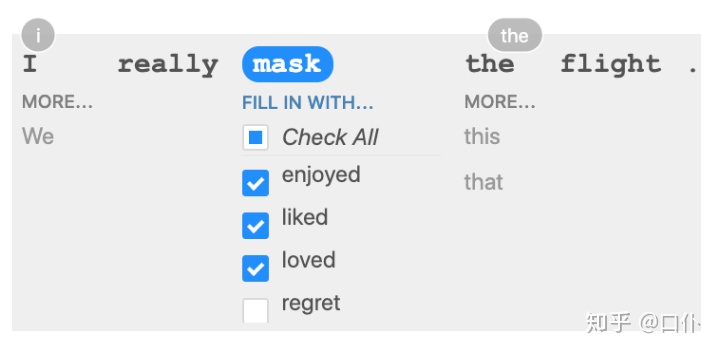
作者在 github 上提供了 CheckList 的开源实现,针对上述三要素提供了各种各样的可视化和抽象方法,感兴趣可以前往 https://github.com/marcotcr/checklist 把玩。下面给出针对三种任务类型的代码示例:
「MFT」:
import checklist
from checklist.editor import Editor
from checklist.perturb import Perturb
from checklist.test_types import MFT, INV, DIR
editor = Editor()
t = editor.template('This is {a:adj} {mask}.',
adj=['good', 'great', 'excellent', 'awesome']) # MLM和模板结合
test1 = MFT(t.data, labels=1, name='Simple positives',
capability='Vocabulary', description='') # 注意要添加标签「INV」:
dataset = ['This was a very nice movie directed by John Smith.',
'Mary Keen was brilliant.',
'I hated everything about this.',
'This movie was very bad.',
'I really liked this movie.',
'just bad.',
'amazing.',
]
t = Perturb.perturb(dataset, Perturb.add_typos)
test2 = INV(**t) # 关键字参数,将任意个参数以字典形式传入「DIR」:
from checklist.expect import Expect
def add_negative(x):
phrases = ['Anyway, I thought it was bad.', 'Having said this, I hated it', 'The director should be fired.']
return ['%s %s' % (x, p) for p in phrases]
t = Perturb.perturb(dataset, add_negative) # 为dataset添加后缀
monotonic_decreasing = Expect.monotonic(label=1, increasing=False, tolerance=0.1) # 这里还是要给原始数据设置标签,希望模型单调下降(应该是标签类对应的概率?)
test3 = DIR(**t, expect=monotonic_decreasing)3 SOTA 模型测试
原文针对三个 NLP 任务对当前的一些 SOTA 模型进行了 CheckList 测试,具体如下所示:
- 「情感分析」(Sentiment Analysis):共测试了五个模型,包括商业界的微软、谷歌和亚马逊的付费 API,以及学术界的 BERT-base 和 RoBERTa-base(在 SST-2 数据集上微调,acc 分别达到 92.7% 和 94.8%)
- 「重复问题检测」(Quora Question Pair):测试了 BERT-base 和 RoBERTa-base(在 QQP 数据集上微调,acc 分别达到 91.1% 和 91.3%)
- 「机器阅读理解」(Machine Comprehension):测试了基于 SQuAD 的 BERT-large,F1 值达到 93.2%
下面将分别对这三项任务的测试结果进行介绍。
3.1 情感分析
下表给出了部分的测试结果及测试用例。可以看到在部分任务(如 Negation)上,所有模型的表现都很糟糕。关于其他具体的表现这里不作赘述,可以查看表格。

3.2 重复问题检测
下表给出了部分的测试结果及测试用例。可以看出虽然两种模型在传统评估方法下的准确率很高,但是 CheckList 表明它们离真正地区分重复问题还有很大的距离。

3.3 机器阅读理解
下表给出了部分的测试结果及测试用例。可以看出模型在大部分能力上的表现都一言难尽。

总的来看,我们将相同的测试方法应用于了三种不同的任务,虽然部分具体的测试内容面向特定的任务,但是测试类型及大部分的测试内容是通用的。虽然这些模型在传统的评估指标下表现都不赖,但是在 CheckList 的部分测试下还是表现出了较高的失败率。通过这样的测试,我们能够更精确地评估模型的能力。
4 用户评估
本节通过用户评估进一步验证 CheckList 的有效性和灵活性,原文中面向两类用户进行了评估,一类用户已经对待测试的模型进行过基于其他方法的仔细评估,另一类用户则对待测试的任务(模型)缺乏了解。
第一类用户表示他们可以通过 CheckList 进一步测试模型,发现一些之前没有考虑到的问题;第二类用户虽然缺乏经验,但是依然可以通过 CheckList 进行一系列测试,并发现一些模型的问题。具体的评估过程请阅读原文。
5 总结
传统的基于准确率的评估并不足以完全评估 NLP 模型的真实表现,本文借鉴软件工程中行为测试的思想,提出了 「CheckList」,一种模型无关和任务无关的测试方法,其通过三种不同的「测试类型」测试模型的各种「语言学能力」。为了说明其有用性,文章在三种不同的任务上测试了多个模型,暴露了大量传统的评估方法难以发现的问题。用户评估表明,CheckList 非常易于学习和使用,对各类用户都是有帮助的。此外,CheckList 的开源实现所提供的抽象方法和工具能够更加轻松地创造测试用例,进行面向各种任务的测试。














 2018
2018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









