






一、对网络的理解
1、SSD网络结构
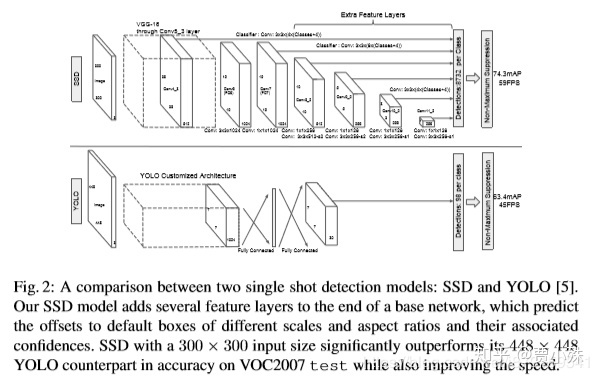
这个网络主要是利用了不同层的feature map,不同层的feature map尺寸大小不一样,尺寸随feature map层数增加线性增加,可以用于产生不同尺寸的先验框,再加上同一种尺寸下不同长宽比的先验框,6个feature map的情况下用可以产生8732个先验框,覆盖范围非常广。
其中,先验框的产生是利用小的卷积核去卷积feature map,所以产生先验框的同时可以预测框的坐标 大小 以及对应类别的置信度,一次齐活,没有faster rcnn的roi pooling那个阶段,不用二次利用feature map。
还有一点是 利用了data augmentation,使得map提升将近10%,论文中有数据说明。data augmentation就主要是利用目标的部分作为整张图像进入网络,使得网络对目标的细节捕捉能力变强。
2、SSD的基础网络是VGG16,其中fc6 fc7被改成卷积层,dropout和fc8被去掉,conv6用到了膨胀卷积增加感受野。
VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是 38*38 ,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层(参见ParseNet),以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma。
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图。
3、网络的输出检测值 包含两个部分:类别置信度和边界框位置,各对6个feature map采用一次 33 卷积来进行完成。令 k为该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为k<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









