









1. 目标检测
计算机视觉关于图像识别有四大类任务:
- 分类 Classfication:解决“是什么?”的问题,即给定一张图片或一段视频,判断里面包含什么类别的目标;
- 定位 Location:解决“在哪里?”的问题,即定位出这个目标的位置;
- 检测 Detection:解决“在哪里?是什么?”的问题,不仅要定位出这个目标的位置,还要知道这个目标物体是什么?
- 分割 Segmentation:分为实例的分割(instance-level)和场景分割(scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
目标检测(object detection)的目的就是找出图像中所有感兴趣的目标,确定他们的类别和位置。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等许多因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
2. 背景
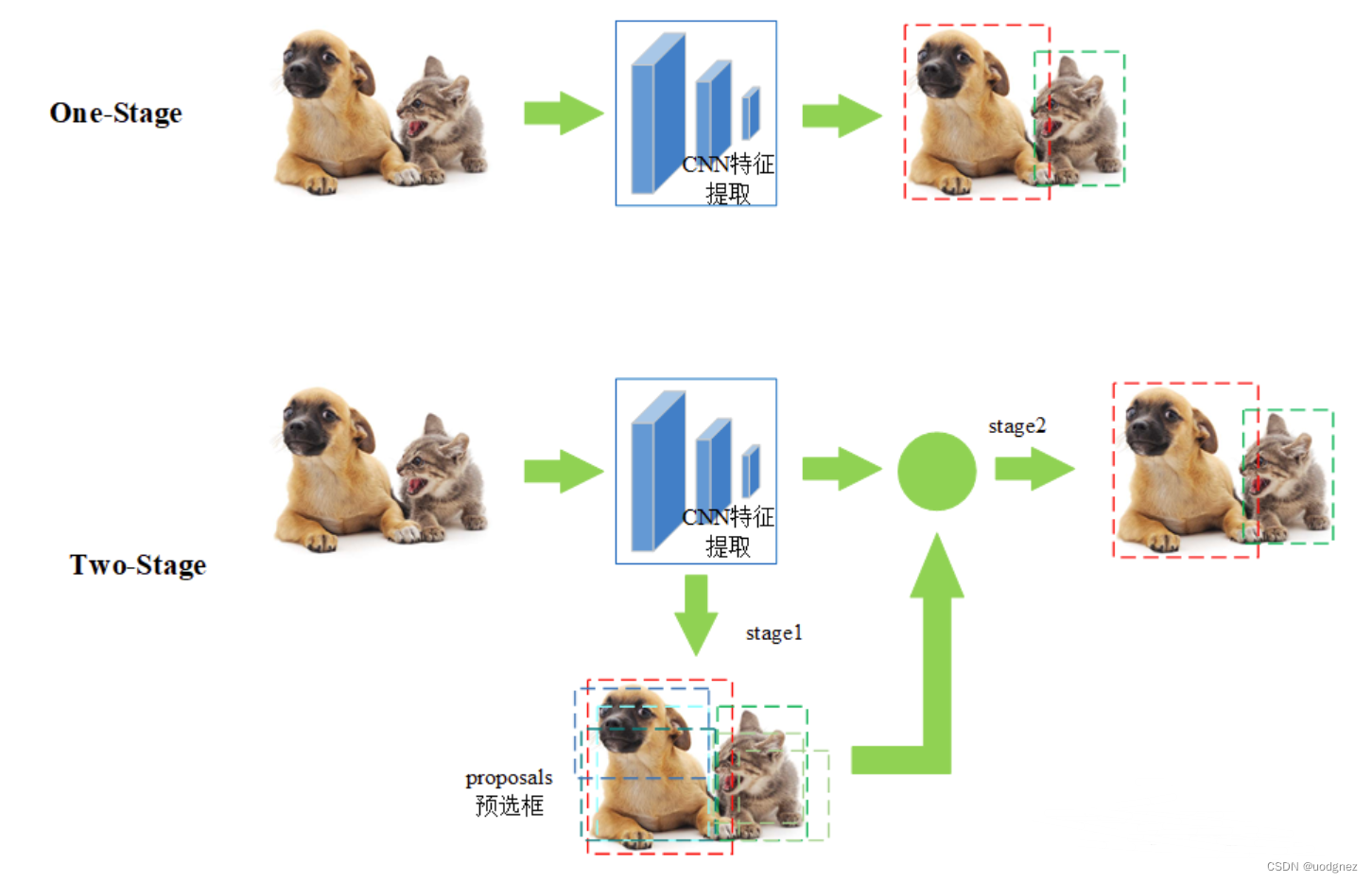
目标检测主流算法主要有两大类:
- two-stage:R-CNN系列
其方法是先进行区域生成,该区域称之为 region proposal(RP,一个有可能包含待检测物体的预选框),然后再通过网络预测目标的分类和定位。 - one-stage:SSD和YOLO系列
不利用RP,直接在网络中提取特征来预测目标的分类和位置。
3. 核心理念
特征金字塔(多尺度):在多个尺度上进行目标检测以提高精度。
原因在于:
- 多尺度信息:特征金字塔可以通过在不同层级的网络中提取特征来获取多尺度信息。在任务中,目标可能以不同的尺寸出现在图像中,因此需要在不同尺度上进行检测和定位。特征金字塔通过合并不同层次的特征图,可以检测和识别不同尺寸的目标。
- 上下文信息:特征金字塔通过在不同的层级中提取特征,可以捕获更广泛的上下文信息。较深层次的特征通常对于全局语义信息具有较好的把握,而较浅层次的特征可以提供更多局部细节信息。通过特征金字塔,算法可以在不同层级上同时利用全局和局部信息,从而更好地理解图像内容。
- 减少信息丢失: 在深度卷积神经网络中,随着网络层数的增加,特征图的尺寸逐渐减小。这可能导致信息丢失,特别是对于较小目标或细节。特征金字塔通过融合多个尺度的特征,可以减少信息丢失的影响,提高网络对小目标的检测能力。
4. SSD网络结构
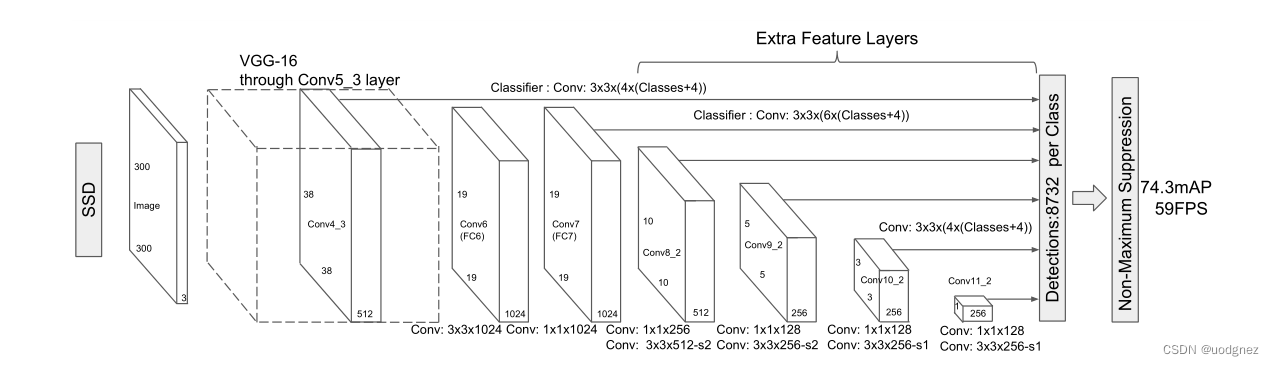
SSD的网络结构主要分为三个部分:VGG16 Base Layer, Extra Feature Layer, Detection layer
VGG16 Base Layer:
SSD网络以VGG16作为基础的特征提取层,并选取其中的Conv4_3作为第一个特征层用于目标检测。
Extra Feature Layer:
在Base Layer的基础上,作者将VGG16中的FC6,FC7改成了卷积层Conv6,Conv7,并且同时添加了Conv8,Conv9,Conv10,Conv11这几个特征层用于目标检测。
输入:reshape后 大小为 ( 300 × 300 × 3 ) (300 \times 300\times3) (300×300×3)的图像
Conv1_2:两次 3 × 3 3 \times3 3×3卷积,得到 ( 300 × 300 × 64 ) (300 \times 300\times64) (300×300×64);再经过 2 × 2 2\times2 2×2最大池化,得到 ( 150 × 150 × 64 ) (150 \times 150\times64) (150×150×64)
Conv2_2:两次 3 × 3 3 \times3 3×3卷积,得到 ( 150 × 150 × 128 ) (150 \times 150\times128) (150×150×128);再经过 2 × 2 2\times2 2×2最大池化,得到 ( 75 × 75 × 128 ) (75 \times 75\times128) (75×75×128)
Conv3_3:三次 3 × 3 3 \times3 3×3卷积,得到 ( 75 × 75 × 256 ) (75 \times 75\times256) (75×75×256);再经过 2 × 2 2\times2 2×2最大池化,得到 ( 38 × 38 × 256 ) (38 \times 38\times256) (38×38×256)
Conv4_3:三次 3 × 3 3 \times3 3×3卷积,得到 ( 38 × 38 × 512 ) (38 \times 38\times512) (38×38×512);再经过 2 × 2 2\times2 2×2最大池化,得到 ( 19 × 19 × 64 ) (19 \times 19\times64) (19×19×64)
Conv5_3:三次 3 × 3 3 \times3 3×3卷积,得到 ( 19 × 19 × 512 ) (19 \times 19\times512) (19×19×512);再经过 3 × 3 3\times3 3×3最大池化,得到 ( 19 × 19 × 512 ) (19 \times 19\times512) (19×19×512)
Conv6、Conv7:分别进行了一次 3 × 3 3\times3 3×3卷积和 1 × 1 1\times1 1×1卷积,得到 ( 19 × 19 × 1024 ) (19 \times 19\times1024) (19×19×1024)
Conv8:经过一次 1 × 1 1\times1 1×1卷积,和 3 × 3 3\times3 3×3卷积,得到 10 × 10 × 512 10 \times 10 \times512 10×10×512
Conv9:经过一次 1 × 1 1\times1 1×1卷积,和 3 × 3 3\times3 3×3卷积,得到 5 × 5 × 256 5 \times 5\times256 5×5×256
Conv10:经过一次 1 × 1 1\times1 1×1卷积,和 3 × 3 3\times3 3×3卷积,得到 3 × 3 × 256 3 \times 3 \times256 3×3×256
Conv11:经过一次 1 × 1 1\times1 1×1卷积,和 3 × 3 3\times3 3×3卷积,得到 1 × 1 × 256 1 \times 1 \times256 1×1×256
Detection layer:
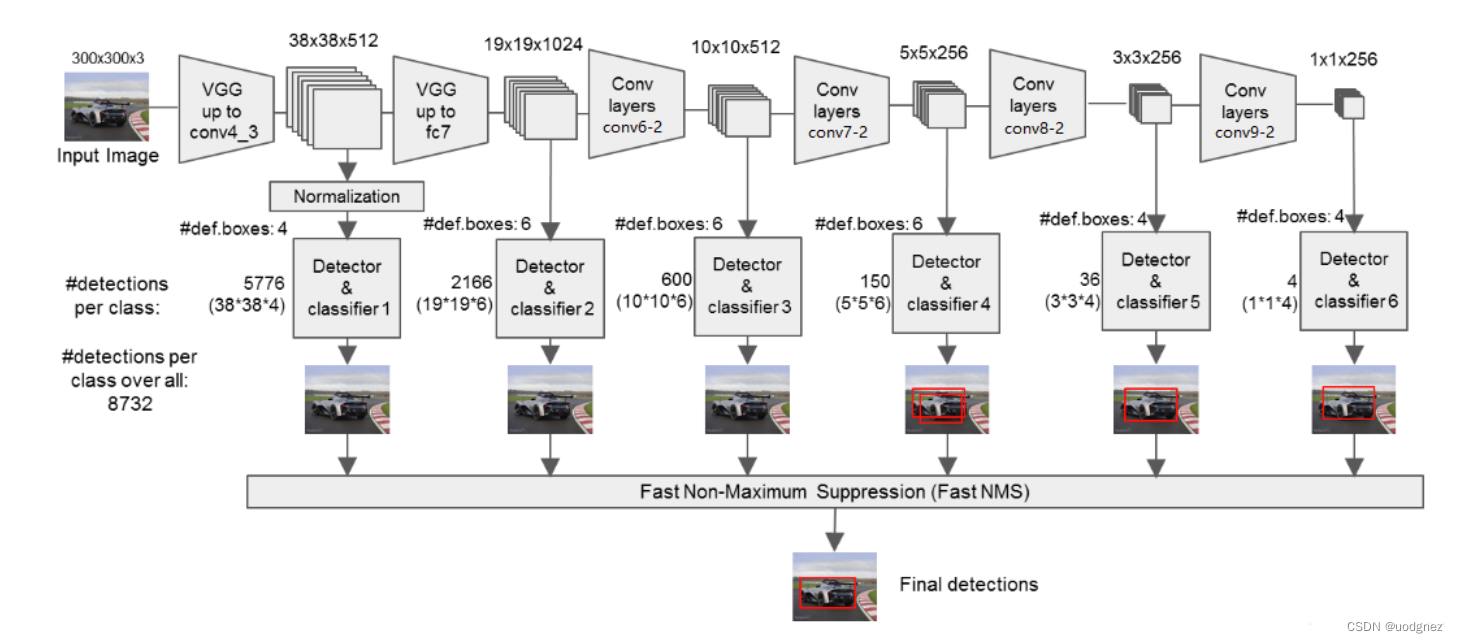
通过上图可以得知,网络共获取六个有效特征层:即Conv4_3的特征、Conv7的特征、Conv8的特征、Conv8的特征,Conv9的特征,Conv10的特征。
对获取到的每一个有效特征层,我们都需要对其做两个操作,分别是:
- num_anchors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
- num_anchors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测对应的种类。
num_anchors指的是该特征层每一个特征点所拥有的先验框数量。
每一个有效特征层将整个图片分成与其长宽对应的网格,如conv4-3的特征层就是将整个图像分成38x38个网格;然后从每个网格中心建立多个先验框,对于conv4-3的特征层来说,它的每个特征点分别建立了4个先验框;因此,对于conv4-3整个特征层来讲,整个图片被分成38x38个网格,每个网格中心对应4个先验框,一共建立了38x38x4个,5776个先验框。这些框密密麻麻的遍布在整个图片上。网络的预测结果会对这些框进行调整获得预测框。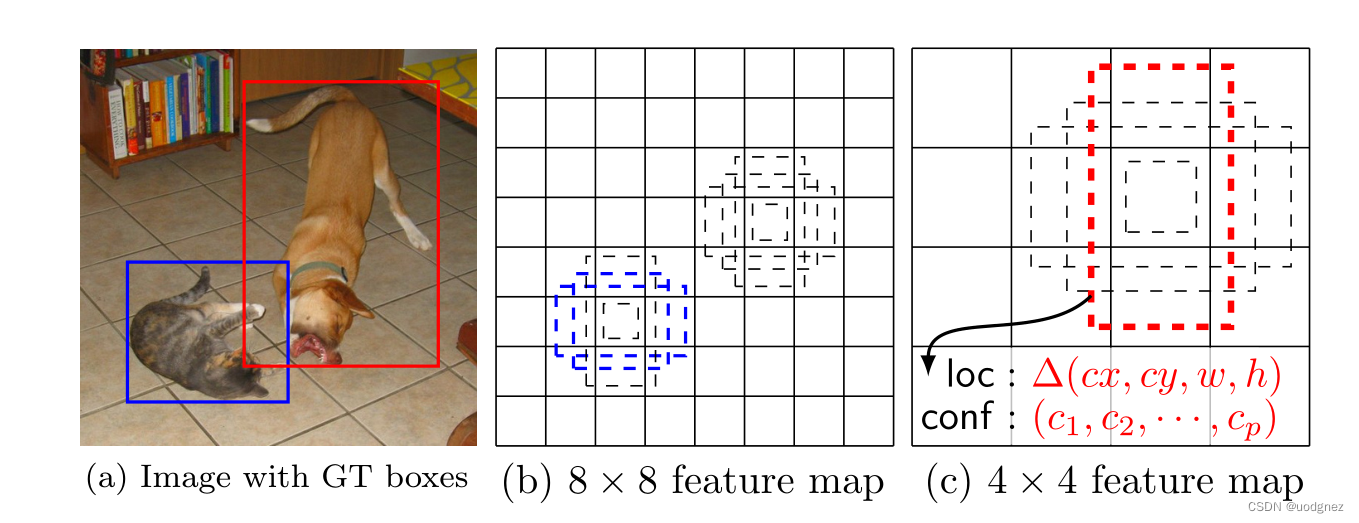















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









