







目录
一、小而美的算法技巧:前缀和数组
前缀和主要适用的场景是原始数组不会被修改的情况下,频繁查询某个区间的累加和。
1.303. 区域和检索 - 数组不可变
方法一:普通遍历
方法二:前缀和
2.304. 二维区域和检索 - 矩阵不可变
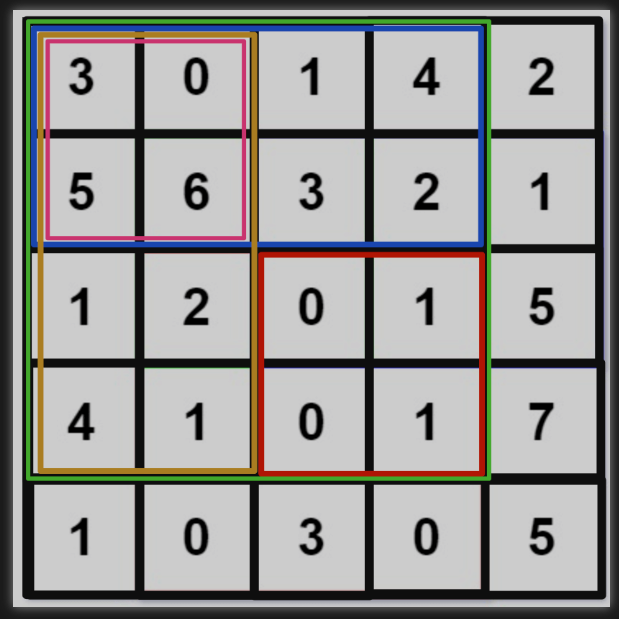
想计算红色的这个子矩阵的元素之和,可以用绿色矩阵减去蓝色矩阵减去橙色矩阵最后加上粉色矩阵,而绿蓝橙粉这四个矩阵有一个共同的特点,就是左上角就是(0, 0)原点。
3.560. 和为 K 的子数组
方法一:遍历得前缀和,相减。
方法二:基于方法一进行优化,使用map保存前缀和和出现得次数。注意:
- map.insert方法需要用std::pair<int,int>()。
- map.insert方法修改不了已存在的数据。
二、小而美的算法技巧:差分数组
差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减。对nums数组构造一个diff差分数组:diff[i]就是nums[i]和nums[i-1]之差:
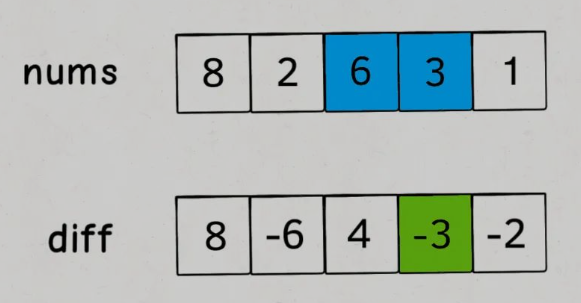
对区间nums[i..j]的元素全部加 3,那么只需要让diff[i] += 3,然后再让diff[j+1] -= 3即可 。
1.区间加法
- sizeof(指针)与sizeof(数组)的区别。
- 如果ArrayAdd要多次调用,那么将diff数组的生成、加一个数的操作、返回结果分别封装成对应的方法,diff数组的生成及返回结果不必多次调用。
//数组某区间内元素加一个数
int* ArrayAdd(std::vector<int> nums, int left, int right, int val)
{
//差分数组
const int length = nums.size();
int* diff = new int[length] {0};
diff[0] = nums[0];
for (size_t i = 1; i < length; i++)
{
diff[i] = nums[i] - nums[i - 1];
}
//修改diff
diff[left] += val;
if (right+1 < length)
{
diff[right + 1] -= val;
}
//计算结果
int* result=new int[length]{ 0 };
result[0] = diff[0];
for (size_t i = 1; i < length; i++)
{
result[i] = result[i-1] + diff[i];
}
return result;
}
int main()
{
std::vector<int> arr{ 8,4,9,5,6 };
int *p= ArrayAdd(arr, 1, 3, 1);
for (int i = 0; i < 5; i++)
{
std::cout << p[i] << std::endl;//8 5 10 6 6
}
}
2.1109. 航班预订统计
vector.insert()函数需要输入位置。
vector在定义时指定了大小,再通过insert/push_back存入元素的话,元素个数=之前定义的大小+insert/push_back次数。直接赋值vector[i]=***可以解决这个问题,或者定义的时候不指定空间大小,也就是所谓的动态vector。
3.1094. 拼车
三、二维数组的花式遍历技巧盘点
1.48. 旋转图像
矩阵变换
按左对角线反转 按竖直对称轴反转
00 01 02 00 10 20 20 10 00
10 11 12 -> 01 11 21 -> 21 11 01
20 21 22 02 12 22 22 12 02
初始 结果
2.54. 螺旋矩阵
将正方形矩阵按顺时针螺旋排列。
思路:上、右、下、左依次遍历,注意index边界问题。
3.59. 螺旋矩阵 II
元素按顺时针顺序螺旋排列生成正方形矩阵。
std::vector<std::vector<int>>的定义:
方法一:
std::vector<std::vector<int>> matrix(5,std::vector<int> (5, 0));方法二:
std::vector<int> row(5, 0); std::vector<std::vector<int>> matrix(5,row);
四、双指针技巧汇总-左右指针
1.我作了首诗,保你闭着眼睛也能写对二分查找
(1)查找一个数: 704. 二分查找
///寻找一个数num,如果存在返回索引,如果不存在返回-1
///nums:为升序数组
int GetNum(std::vector<int> nums, int num)
{
int leftIndex = 0;
int rightIndex = nums.size() - 1;
while (leftIndex <= rightIndex)
{
int mid = (rightIndex + leftIndex) / 2;
if (nums[mid] == num)
{
return mid;
}
else if (nums[mid] < num)
{
leftIndex = mid + 1;
}
else if (nums[mid] > num)
{
rightIndex = mid - 1;
}
}
return -1;
}
这个算法存在局限性。比如说给你有序数组nums = [1,2,2,2,3],target为 2,此算法返回的索引是 2,没错。但是如果我想得到target的左侧边界,即索引 1,或者我想得到target的右侧边界,即索引 3,这样的话此算法是无法处理的。
(2)寻找左侧边界的二分搜索
不必强记要不要判断=的情况。
(3)寻找右侧边界的二分搜索
注意判断索引越界。
不必强记要不要判断=的情况。
2.167. 两数之和 II - 输入有序数组
普通的双层for循环会超时。
左右指针。++,--
3.344. 反转字符串
左右指针。++ -- 互换
4.经典面试题:最长回文子串
回⽂⼦串问题是让左右指针从中⼼向两端扩展。
(1)125. 验证回文串
- 左右指针从两边向中间扩展,判断相不相等。
- 字符串转大小写:
- 方法1.遍历,大写的字符+32为小写;
- 方法2:
#include <algorithm>
std::transform(s.begin(), s.end(), s.begin(), toupper);(2)5. 最长回文子串
一个一个遍历,求出以该元素为中点时的回文子串(注意while判断时,两个元素相等才i--,j++),判断回文串大小。
5.我写了套框架,把滑动窗口算法变成了默写题
(1)76. 最小覆盖子串 (难呐)
A:给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
Q:这个有点难,主要用到:
- 两个无序表:进行对比,存字符和出现的次数。
- 一个int值valid:当要判断的字符第一次出现时+1。当t中的字符在[left,right)区间内都至少存在一个时,valid等于need.size(),此时开始缩小区间。
- 注意字符串s一定要全部遍历完。注意这种例子:s:“ASDFGBNCAB”,t:“ABC”,结果:“CAB”
std::string minWindow(std::string s, std::string t) {
int left = 0;
int right = 0;
std::unordered_map<char, int> need;
std::unordered_map<char, int> window;
int valid = 0; //重要
int start = 0;
int len = 1000000;
//遍历t,存入need
for (auto c : t)
{
need[c]++;
}
while (right < s.length())
{
//遍历s
char c = s[right];
if (need.count(c))
{
window[c]++;
if (window[c] == need[c]) //注意这个条件,当t中的字符在[left,right)区间内都至少存在一个时,valid等于need.size(),此时开始缩小区间。
{
valid++;
}
}
right++;
//缩小[left,right)区间
while (valid == need.size())
{
if (right - left < len) //用来比较区间大小
{
start = left;
len = right - left;
}
char d = s[left];
if (need.count(d))
{
if (window[d] == need[d]) //注意这个条件
{
valid--;
}
window[d]--;
}
left++;
}
}
return len == 1000000 ? "" : s.substr(start, len);
}
(2)567. 字符串的排列
注意窗口是否要收缩的条件:移动left缩小窗口的时机是窗口大小=t.size()时,因为排列嘛,显然长度应该是一样的
(3)438. 找到字符串中所有字母异位词
注意条件
(4)3. 无重复字符的最长子串
举个栗子:
| 0 | 1 | 2 | 3 | 4 | 5 |
| a | b | cc | b | d | e |
fast指向4时,处理索引为3的这个元素,window[*]>1,表明【fast-1】这个索引(3)下的元素(b)是重复的,即[0,4)之间有重复的,此时需要缩小窗口,找到那个与该元素相等的元素(b),即slow指向b的下一个元素的索引(2),此时len=fast-slow-1=4-0-1=3。
还需要注意fast遍历完,最后一段的处理,此时fast=6,slow=2。len=fast-slow=4。
五、双指针技巧汇总-快慢指针
1.26. 删除有序数组中的重复项
注意是有序数组:让慢指针 slow ⾛在后⾯,快指针 fast ⾛在前⾯探路,找到⼀个不重复的元素就赋值给 slow 并让 slow 前进⼀步。 这样,就保证了 nums[0..slow] 都是⽆重复的元素,当 fast 指针遍历完整个数组 nums 后, nums[0..slow] 就是整个数组去重之后的结果。
注意:两个数不必交换,直接赋值即可。nums[slowIndex]=nums[fastIndex]。
2.27. 移除元素
方法一:左右指针:
- 判断左边的元素,与target一样时,与右边的交换顺序。
- 会改变数组的相对位置。
方法二:快慢指针:
- 判断快的那个元素,与target不一样时,赋值给慢的那个元素。
- 不会改变数组的相对位置。
3.283. 移动零
不能改变非0元素得相对位置。快慢指针
六、带权重的随机选择算法
1.528. 按权重随机选择
两种方法:都基于前缀和。
- 游戏开发时的方法:扩大100倍,耗时多
- 不用扩大倍数,二分搜索。
七、二分搜索运用技巧 (难闹)
1.875. 爱吃香蕉的珂珂
Q:什么问题可以运⽤⼆分搜索算法技巧?
A:⾸先,你要从题⽬中抽象出⼀个⾃变量 x,⼀个关于 x 的函数 f(x),以及⼀个⽬标值 target。同时,x, f(x), target 还要满⾜以下条件:
- f(x) 必须是在 x 上的单调函数(单调增单调减都可以)。
- 题⽬是让你计算满⾜约束条件 f(x) == target 时的 x 的值。
(1)先找关系
确定 x, f(x), target 分别是什么,并写出函数 f 的代码。
- x就是速度k。
- f(x)就是吃完所有⾹蕉所需的时间。
- target就是h小时。
(2)画出f(x)与x的关系图,递增还是递减
(3)二分搜索
//函数是关于⾃变量 k 的单调函数
int GetHours(std::vector<int>& piles,int k)
{
int hours = 0;
for (size_t i = 0; i < piles.size(); i++)
{
hours += piles[i] / k;
if (piles[i] % k > 0) {
hours++;
}
}
return hours;
}
int minEatingSpeed(std::vector<int>& piles, int h) {
int left = k的最小值;(k的最小值是1)
int right = k的最大值 + 1;(k的最大值应该是最大堆香蕉的数量)
while (left < right)
{
int mid = (left + right) / 2;
if (GetHours(piles, mid) > h)
{
left = mid + 1;//判断区间方向,一定要画图
}
else {
right = mid;
}
}
return left;
}
注意:left和right一般赋值为自变量k的最小值和最大值+1,但如果代码运行超出时间限制,left和right可以根据实际情况分析。
2.1011. 在 D 天内送达包裹的能力
(1)找关系(关系好找,但我竟然实现不了)
int GetDays(std::vector<int> & weights, int carryWeight)
{
int days = 0;
for (int i = 0; i < weights.size(); ) {
int cap = carryWeight;
while (i < weights.size()) {
if (cap < weights[i]) {
break;
}
else {
cap -= weights[i];
}
i++;
}
days++;
}
return days;
}
(2)注意包裹不能拆开
- 每个包裹不能分割,所以运载重量的最小值必须大于等于最重的包裹.
- 运载重量的最大值大于所有包裹的重量
int left = 0;
int right =0;
for (auto weight : weights)
{
left = left > weight ? left : weight;
right += weight;
}
八、算法大师——孙膑
1.870. 优势洗牌
要注意优先队列的用法
auto MyCompare = [](std::vector<int> _nums1, std::vector<int> _nums2){return _nums2[1] > _nums1[1]; };
std::priority_queue<std::vector<int>, std::vector<std::vector<int>>, decltype(MyCompare)> bigHeap(MyCompare);
for (int i = 0; i < nums2.size(); i++)
{
std::vector<int> temp{ i, nums2[i] };
bigHeap.push(temp);
}
九、给我 O(1) 时间,我能查找/删除数组中的任意元素
1.380. O(1) 时间插入、删除和获取随机元素
如果想「等概率」且「在 O(1) 的时间」取出元素,一定要满足:底层用数组实现,且数组必须是紧凑的。
对数组尾部进行插入和删除操作不会涉及数据搬移,时间复杂度是 O(1)。(交换两个元素必须通过索引进行交换对吧,那么我们需要一个哈希表valToIndex来记录每个元素值对应的索引 )
注意对value_index_map的处理:
//处理 _value_index_map
_value_index_map[ _array.back()] = index; //注意这一步 要在数组处理之前
_value_index_map.erase(val);
//处理数组
int temp = _array[index];
_array[index] = _array.back();
_array.back() = temp;
_array.pop_back();
2.710. 黑名单中的随机数
- 等概率
- rand()少用
如果随机数为黑名单中的某个,要映射成白名单中的数。
std::unordered_map<int, int> blackvalue_whitevalue_map;注意:
- 没必要遍历所有的数,形成一个映射表,这样会超时。
- 只需要遍历黑名单即可,然后逆序遍历n。
十、无序数组去并保持相对位置
对于数组来说,在尾部插入、删除元素是比较高效的,时间复杂度是 O(1),但是如果在中间或者开头插入、删除元素,就会涉及数据的搬移,时间复杂度为 O(N),效率较低。
所以对于一般处理数组的算法问题,我们要尽可能只对数组尾部的元素进行操作,以避免额外的时间复杂度。
当然,不考虑数组的原始序列顺序的前提下,我们删除某个中间元素,可以通过map来记录value到index的映射,达到交换元素的目的(该元素与末尾元素交换)
对于有序数组,要去重还要保证有序性:我们可以使用快慢指针。但是对于无序的数组,去重后仍然保持相对位置,该怎么办呢?
1.316. 去除重复字母
同1081力扣。
为什么要用「stack」这种数据结构,因为先进后出的结构允许我们立即操作刚插入的字符,如果用「queue」的话肯定是做不到的,不过deque可以。
思路:插入元素时,要判断队列中的元素是否小于当前元素。如果当前元素最小,要判断队列中的元素是否要pop。
注意:while嵌套while,break数量
















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











