







Principal Component Analysis (PCA )被归类为机器学习十大算法之一。用于从一组较大的数据中识别少数的具有代表性的特征,即主成分。主成分分析是由卡尔·皮尔森(Karl Pearson)于1901年发明的一种用于预测模型和探索性数据分析的工具。主成分分析是一种有用的统计方法,现在广泛应用于图像压缩、人脸识别、神经科学和计算机图形学等领域。是不是没想到119年前的算法,到现在如此火爆吧!:)
PCA让我们使数据更容易探索和可视化。它是一种简单的非参数技术,用于从复杂和混乱的数据集中提取信息。现在是数据爆炸的年代,这种算法不火,还待何时!PCA的重点是在主成分最少的情况下得到最大的方差量。一旦在相关数据中发现了模式,还支持数据压缩。人们利用PCA来消除变量的数量,或者当与观测的数量相比有太多的预测因子时,或者为了避免多重共线性。它与典型相关分析密切相关,利用正交变换将包含相关变量的观测集转换为称为主成分的一组值。主成分分析中使用的主成分的数量小于或等于较小数量的观测值。主成分分析对原始变量的相对尺度很敏感。
主成分分析广泛应用于许多领域,如市场研究、社会科学和使用大数据集的行业。该技术还可以帮助提供原始数据的低维图像。在主成分分析的情况下,只需极小的努力,以减少复杂和混乱的数据集为简化有用的信息集。
让我们步入正题吧
从分析小白鼠的分类开始
仍然是从简单到复杂的思路。
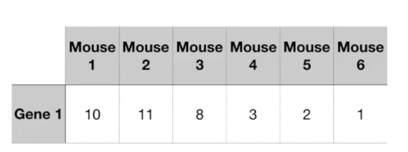
给出小白鼠的一种基因,一共6只小白鼠。
如何知道这些小白鼠应该属于几类小白鼠呢?
把给出的基因数据,画到图上。
很显然,4,5,6是一组,1,2,3是一组。因此分在一组的小白鼠,在给出的基因特征上,比较接近。
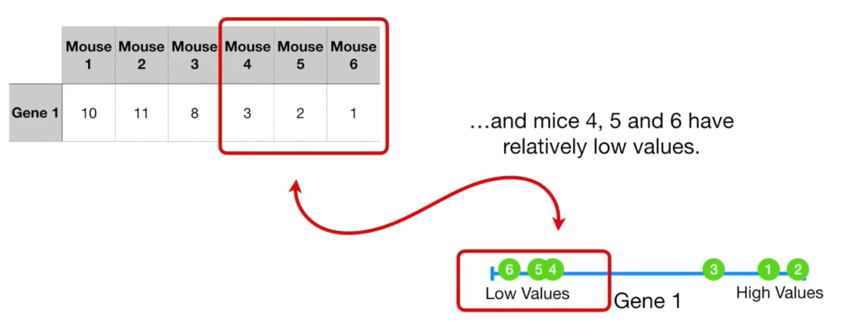
如果给出两种基因呢?继续把它们画到图上。分类也清晰可见!
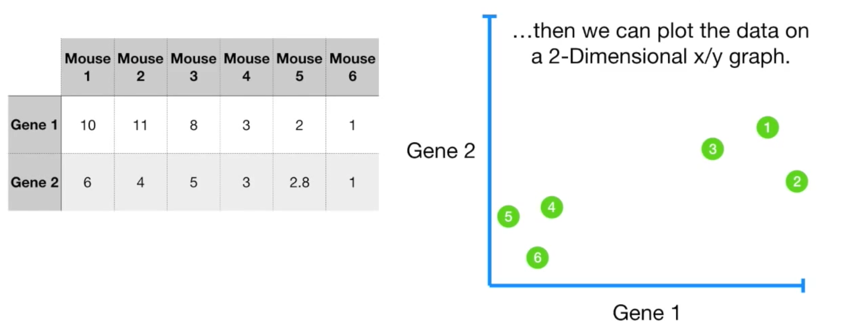
如果给出三种基因呢?继续把它们画到图上。分类也清晰可见!
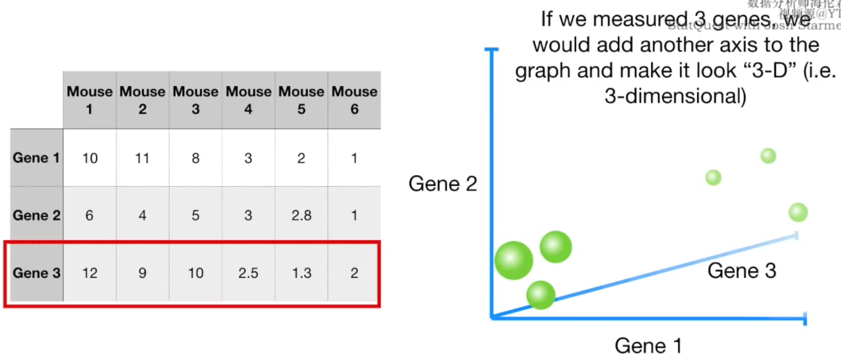
如果给出四种基因呢?画不出来吧?怎么办???

四维甚至更高维度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









