






 本文详细介绍了如何在R语言中执行PCA(主成分分析),包括判断主成分数量、提取主成分、主成分旋转以及获取主成分得分的过程,并通过实例演示了如何在实际数据中应用PCA进行降维。
本文详细介绍了如何在R语言中执行PCA(主成分分析),包括判断主成分数量、提取主成分、主成分旋转以及获取主成分得分的过程,并通过实例演示了如何在实际数据中应用PCA进行降维。
看见文献里有使用 PCA=∑(PC1 + PC2),也有值描述PCA得分的。究竟应该怎么取计算PCA得分。。。。。。。
关于PCA的步骤回顾:
目录
PC1 案例
1,判断主成分的个数
数据格式
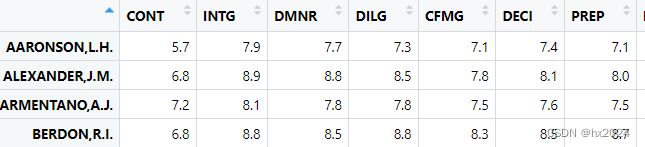
rm(list = ls())
library(psych)
data <- USJudgeRatings
fa.parallel(USJudgeRatings[,-1], fa="pc",
n.iter=100,
show.legend=FALSE,
main="Scree plot with parallel analysis")
判断注释:Kaiser-Harris准则建 议保留特征值大于1的主成分,特征值小于1的成分所解释的方差比包含在单个变量中的方差更少。Cattell碎石检验则绘制了特征值与主成分数的图形。
2,提取主成分
principal(r, nfactors=, rotate=, scores=)
r是相关系数矩阵或原始数据矩阵;
nfactors设定主成分数(默认为1);
rotate指定旋转的方法(默认最大方差旋转(varimax));
scores设定是否需要计算主成分得分(默认不需要)。提取主成分
pc <- principal(USJudgeRatings[,-1], nfactors = 1)
pcPrincipal Components Analysis
Call: principal(r = USJudgeRatings[, -1], nfactors = 1)
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 h2 u2 com
INTG 0.92 0.84 0.1565 1
DMNR 0.91 0.83 0.1663 1
DILG 0.97 0.94 0.0613 1
CFMG 0.96 0.93 0.0720 1
DECI 0.96 0.92 0.0763 1
PREP 0.98 0.97 0.0299 1
FAMI 0.98 0.95 0.0469 1
ORAL 1.00 0.99 0.0091 1
WRIT 0.99 0.98 0.0196 1
PHYS 0.89 0.80 0.2013 1
RTEN 0.99 0.97 0.0275 1
PC1
SS loadings 10.13
Proportion Var 0.92
Mean item complexity = 1
Test of the hypothesis that 1 component is sufficient.
The root mean square of the residuals (RMSR) is 0.04
with the empirical chi square 6.21 with prob < 1
结果解读:PC1栏包含了成分载荷,指观测变量与主成分的相关系数。如果提取不止一个主成分,那么 还将会有PC2、PC3等栏。成分载荷(component loadings)可用来解释主成分的含义。此处可以看到,第一主成分(PC1)与每个变量都高度相关,也就是说,它是一个可用来进行一般性评价的维度。
3 ,主成分旋转
4 ,获取主成分得分
美国法官评分例子中,我们根据原始数据中的11个评分变量提取了一个主成分。
pc <-principal(USJudgeRatings[,-1], nfactors=1, score=TRUE)
head(pc$scores)PC1 AARONSON,L.H. -0.1857981 ALEXANDER,J.M. 0.7469865 ARMENTANO,A.J. 0.0704772 BERDON,R.I. 1.1358765 BRACKEN,J.J. -2.1586211 BURNS,E.B. 0.7669406
当scores = TRUE时,主成分得分存储在principal()函数返回对象的scores元素中。
PC2 案例 PC1 + PC2
1,判断主成分的个数
数据格式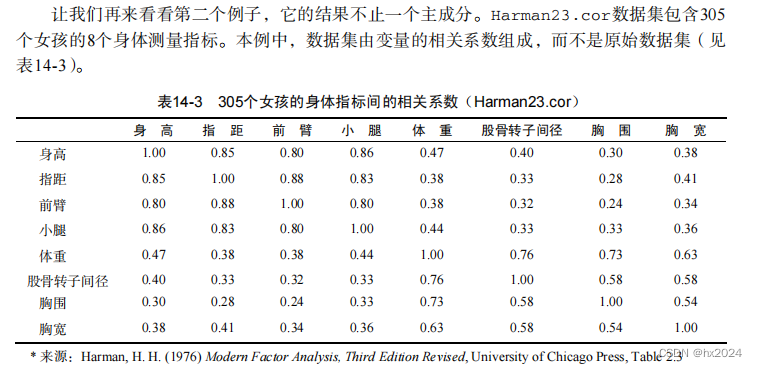
rm(list = ls())
library(psych)
#Harman23.cor数据集的例子,本数据集本身已经是相关系数矩阵
##确定主成分个数
fa.parallel(Harman23.cor$cov, n.obs=302,
fa="pc",
n.iter=100,
show.legend=FALSE,
main="Scree plot with parallel analysis")
#结果提示
Parallel analysis suggests that the number of factors = NA
and the number of components = 2 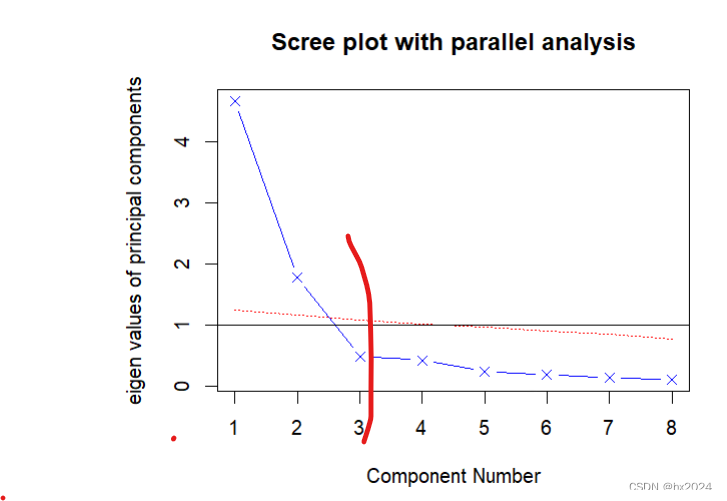
2,提取主成分
pc <- principal(Harman23.cor$cov,
nfactors=2,##依据判断需要2个主成分
rotate="none")
pcPrincipal Components Analysis
Call: principal(r = Harman23.cor$cov, nfactors = 2, rotate = "none")
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 PC2 h2 u2 com
height 0.86 -0.37 0.88 0.123 1.4
arm.span 0.84 -0.44 0.90 0.097 1.5
forearm 0.81 -0.46 0.87 0.128 1.6
lower.leg 0.84 -0.40 0.86 0.139 1.4
weight 0.76 0.52 0.85 0.150 1.8
bitro.diameter 0.67 0.53 0.74 0.261 1.9
chest.girth 0.62 0.58 0.72 0.283 2.0
chest.width 0.67 0.42 0.62 0.375 1.7
PC1 PC2
SS loadings 4.67 1.77
Proportion Var 0.58 0.22
Cumulative Var 0.58 0.81
Proportion Explained 0.73 0.27
Cumulative Proportion 0.73 1.00
Mean item complexity = 1.7
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
Fit based upon off diagonal values = 0.99
3 ,主成分旋转
rc <- principal(Harman23.cor$cov,
nfactors=2,
rotate="varimax")
rc
Principal Components Analysis
Call: principal(r = Harman23.cor$cov, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
RC1 RC2 h2 u2 com
height 0.90 0.25 0.88 0.123 1.2
arm.span 0.93 0.19 0.90 0.097 1.1
forearm 0.92 0.16 0.87 0.128 1.1
lower.leg 0.90 0.22 0.86 0.139 1.1
weight 0.26 0.88 0.85 0.150 1.2
bitro.diameter 0.19 0.84 0.74 0.261 1.1
chest.girth 0.11 0.84 0.72 0.283 1.0
chest.width 0.26 0.75 0.62 0.375 1.2
RC1 RC2
SS loadings 3.52 2.92
Proportion Var 0.44 0.37
Cumulative Var 0.44 0.81
Proportion Explained 0.55 0.45
Cumulative Proportion 0.55 1.00
Mean item complexity = 1.1
Test of the hypothesis that 2 components are sufficient.
The root mean square of the residuals (RMSR) is 0.05
Fit based upon off diagonal values = 0.99
4 ,获取主成分得分
rc <- principal(Harman23.cor$cov,
nfactors = 2,
rotate = "varimax")
round(unclass(rc$weights),2)RC1 RC2 height 0.28 -0.05 arm.span 0.30 -0.08 forearm 0.30 -0.09 lower.leg 0.28 -0.06 weight -0.06 0.33 bitro.diameter -0.08 0.32 chest.girth -0.10 0.34 chest.width -0.04 0.27
则相应的PC1和PC2主成分的计算公司如下:


principal函数和prcomp函数都是用于计算主成分分析(PCA)的函数,但它们之间有一些差异。
- principal函数是psych包中的函数,它可以计算PCA以及其他因子分析和结构方程模型等多种分析方法。它的输出包括每个主成分的方差贡献率、成分载荷和得分等信息。
- prcomp函数是stats包中的函数,它只能计算PCA。它的输出包括每个主成分的方差贡献率、成分载荷和得分等信息,与principal函数的输出类似。
除了输出结果的差异外,这两个函数在计算PCA时的算法也有所不同。prcomp函数使用的是标准的奇异值分解(SVD)算法,而principal函数使用的是最大似然估计法或最小残差法等不同的算法。
《R语言实战》
R语言如何实现主成分分析(PCA),最全详细教材_r studio主成分分析-CSDN博客
机器学习实验:主成分分析法PCA实现手写数字数据集的降维_pca主成分分析和交叉验证-CSDN博客
【使用 PCA 实现对鸢尾花四维数据(Iris)进行降维处理】_鸢尾花数据集上的实现pca降维_风也温柔_Esther的博客-CSDN博客

















 6124
6124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









