









1.获取数据
由于没有限制所以随机抓取20只股票
import tushare as ts
import os
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data1=ts.get_hist_data('000001')
data2=ts.get_hist_data('300152')
data3=ts.get_hist_data('600776')
data4=ts.get_hist_data('300313')
data5=ts.get_hist_data('600130')
data6=ts.get_hist_data('000733')
data7=ts.get_hist_data('000831')
data8=ts.get_hist_data('000333')
data9=ts.get_hist_data('601328')
data10=ts.get_hist_data('601668')
data11=ts.get_hist_data('601398')
data12=ts.get_hist_data('600519')
data13=ts.get_hist_data('600028')
data14=ts.get_hist_data('601088')
data15=ts.get_hist_data('600104')
data16=ts.get_hist_data('000066')
data17=ts.get_hist_data('000063')
data18=ts.get_hist_data('600897')
data19=ts.get_hist_data('600988')
data20=ts.get_hist_data('002865')
2.数据预处理
为了使所有指标的数据量保持一致,统一截取2017年5月21日至2019年5月21年之间的数据
data1=data1.loc['2019-05-21':'2017-05-21']
data2=data2.loc['2019-05-21':'2017-05-21']
data3=data3.loc['2019-05-21':'2017-05-21']
data4=data4.loc['2019-05-21':'2017-05-21']
data5=data5.loc['2019-05-21':'2017-05-21']
data6=data6.loc['2019-05-21':'2017-05-21']
data7=data7.loc['2019-05-21':'2017-05-21']
data8=data8.loc['2019-05-21':'2017-05-21']
data9=data9.loc['2019-05-21':'2017-05-21']
data10=data10.loc['2019-05-21':'2017-05-21']
data11=data11.loc['2019-05-21':'2017-05-21']
data12=data12.loc['2019-05-21':'2017-05-21']
data13=data13.loc['2019-05-21':'2017-05-21']
data14=data14.loc['2019-05-21':'2017-05-21']
data15=data15.loc['2019-05-21':'2017-05-21']
data16=data16.loc['2019-05-21':'2017-05-21']
data17=data17.loc['2019-05-21':'2017-05-21']
data18=data18.loc['2019-05-21':'2017-05-21']
data19=data19.loc['2019-05-21':'2017-05-21']
data20=data20.loc['2019-05-21':'2017-05-21']
后面的分析主要基于股票收盘价,为此分析前,先汇总一下
import pandas as pd
data_close=pd.DataFrame([data1['close'],data2['close'],data3['close'],data4['close'],data5['close'],data6['close'],data7['close'],data8['close'],data9['close'],data10['close'],data11['close'],data12['close'],data13['close'],data14['close'],data15['close'],data16['close'],data17['close'],data18['close'],data19['close'],data20['close']]).T
data_close.columns=['上证指数','仁和药业','东方通信','宏达电子','波导股份','览海投资','五矿稀土','美的集团','交通银行','中国建筑',
'工商银行','贵州茅台','中国石化','中国神华','上汽集团','中国长城','中兴通信','厦门空港','赤峰黄金','万丰奥威']
data_close.head()
由于各种因素影响。数据中还是存在缺失值,所以分析前还是得处理一下
首先查看数据缺失的分布情况

import missingno as msno
col_missing =data_close.isnull().any()[data_close.isnull().any()].index
msno.matrix(df=data_close[col_missing])
博主很懒,直接删掉了带有缺失值的股票!!
为了以防万一以后哪天抽风了突然想要原数据,所以不直接删除数据,而只是选中待分析的数据

cul=['上证指数','东方通信', '波导股份', '览海投资', '五矿稀土', '交通银行','中国建筑', '工商银行', '贵州茅台', '中国石化', '上汽集团', '中国长城', '厦门空港','赤峰黄金', '万丰奥威' ]
3.投资组合
投资组合的目的是为了分散风险,所以选取的股票应尽可能的多元化,因此先绘制皮尔逊相关系数图
import numpy as np
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300
cul=['上证指数','东方通信', '波导股份', '览海投资', '五矿稀土', '交通银行','中国建筑', '工商银行', '贵州茅台', '中国石化', '上汽集团', '中国长城', '厦门空港','赤峰黄金', '万丰奥威' ]
ar=np.array(data_close[cul].corr())
ind=data_close[cul].corr().index
col=data_close[cul].corr().columns
plt.figure(figsize=(16,12))
sns.heatmap(data_close[cul].corr(),linewidths=0.1, square=True, cmap="RdBu_r", linecolor='white', annot=True)
plt.savefig('corr.png',dpi=500)
plt.show()

选择性的剔除掉相关度较高的股票,并查看结果
close_df=pd.concat([data1['close'],data3['close'],data13['close'],data15['close'],data16['close'],data18['close']],axis=1)
close_df.columns=['上证指数','东方通信', '中国石化', '上汽集团', '中国长城', '厦门空港' ]
close_df=close_df.loc['2017-05-22':'2019-05-22']
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300
cul=['上证指数','东方通信', '中国石化', '上汽集团', '中国长城', '厦门空港']
ar=np.array(data_close[cul].corr())
ind=data_close[cul].corr().index
col=data_close[cul].corr().columns
plt.figure(figsize=(16,12))
sns.heatmap(data_close[cul].corr(),linewidths=0.1,vmax=1.0, square=True, cmap="Greens", linecolor='white', annot=True,vmin=0)
plt.savefig('corr.png',dpi=500)
plt.show()

4.收盘价波动图
fig, [ax1, ax2, ax3, ax4, ax5, ax6] = plt.subplots(6, 1, figsize=(22,24))
ax1.plot(close_df.index, close_df['上证指数'])
ax1.set(ylabel='上证指数')
ax2.plot(close_df.index, close_df['东方通信'])
ax2.set(ylabel='东方通信')
ax3.plot(close_df.index, close_df['中国石化'])
ax3.set(ylabel='中国石化')
ax4.plot(close_df.index, close_df['上汽集团'])
ax4.set(ylabel='上汽集团')
ax5.plot(close_df.index, close_df['中国长城'])
ax5.set(ylabel='中国长城')
ax6.plot(close_df.index, close_df['厦门空港'])
ax6.set(ylabel='厦门空港')
for label in ax6.get_xticklabels():
label.set_visible(False)
for label in ax6.get_xticklabels()[::30]:
label.set_visible(True)
plt.savefig('stock.png',dpi=500)
plt.show()

5.计算收益率
from math import log
ln1=[log(i) for i in close_df['上证指数']]
ln2=[log(i) for i in close_df['东方通信']]
ln3=[log(i) for i in close_df['中国石化']]
ln4=[log(i) for i in close_df['上汽集团']]
ln5=[log(i) for i in close_df['中国长城']]
ln6=[log(i) for i in close_df['厦门空港']]
ret_df=pd.DataFrame([ln1,ln2,ln3,ln4,ln5,ln6]).T
ret_df.columns=['上证指数','东方通信', '中国石化', '上汽集团', '中国长城', '厦门空港' ]
ret_df.index=close_df.index
ret_df['上证指数']=ret_df['上证指数'].diff()
ret_df['东方通信']=ret_df['东方通信'].diff()
ret_df['中国石化']=ret_df['中国石化'].diff()
ret_df['上汽集团']=ret_df['上汽集团'].diff()
ret_df['中国长城']=ret_df['中国长城'].diff()
ret_df['厦门空港']=ret_df['厦门空港'].diff()
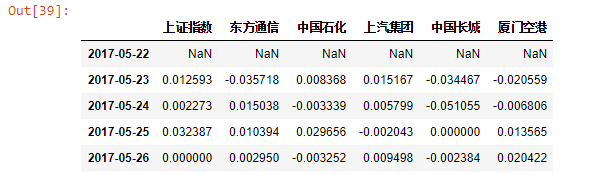
ret_df=ret_df.loc['2017-05-22':'2019-05-22']
ret_df.head()
绘制收益率分布图(同理可得其他股票收益率分布图)
plt.figure(figsize=(12,8))
plt.subplot(2, 1, 1)
plt.hist(ret_df['上证指数'],bins=100)
plt.ylabel('上证指数')
plt.title(u"收益率分布图" , weight='bold');
plt.savefig('distribution.png',dpi=500)
plt.show()

6.收益率与风险之间的关系
import numpy as np
area = np.pi*20
plt.scatter(ret_df.mean(), ret_df.std(),alpha = 0.5,s =area)
plt.xlabel('收益率')
plt.ylabel('风险')
# Label the scatter plots
for label, x, y in zip(ret_df.columns, ret_df.mean(), ret_df.std()):
plt.annotate(
label,
xy = (x, y), xytext = (20,0),
textcoords = 'offset points', ha = 'right', va = 'bottom',
arrowprops = dict(arrowstyle = '-', connectionstyle = 'arc3,rad=-0.3'))
plt.savefig('risk.png',dpi=500)
plt.show()

7.蒙特卡洛模拟
def stock_monte_carlo(start_price,days,mu,sigma):
''' This function takes in starting stock price, days of simulation,mu,sigma, and returns simulated price array'''
# Define a price array
price = np.zeros(days)
price[0] = start_price
# Schok and Drift
shock = np.zeros(days)
drift = np.zeros(days)
# Run price array for number of days
for x in range(1,days):
# Calculate Schock
shock[x] = np.random.normal(loc=mu * dt, scale=sigma * np.sqrt(dt))
# Calculate Drift
drift[x] = mu * dt
# Calculate Price
price[x] = price[x-1] + (price[x-1] * (drift[x] + shock[x]))
return price
x=ret_df.loc['2018-05-22':'2019-05-22'].index
days = len(ret_df.loc['2018-05-22':'2019-05-22'])
# Now our delta
dt = 1/days
mu = ret_df.loc['2018-05-22':'2019-05-22'].mean()['上证指数']
# Now let's grab the volatility of the stock from the std() of the average return
sigma = ret_df.std()['上证指数']
start_price =data1['close']['2018-05-22']
print(mu,sigma)
fig, ax = plt.subplots(figsize=(22,6))
for run in range(100):
plt.plot(x,stock_monte_carlo(start_price,days,mu,sigma))
plt.xlabel("Days")
plt.ylabel("Price")
for label in ax.get_xticklabels():
label.set_visible(False)
for label in ax.get_xticklabels()[::30]:
label.set_visible(True)
plt.title('上证指数')

未完待续…
想起来时候再续吧…















 3398
3398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









