







目录
1. Title
2. Summary
本文通过将人工交互和mask传播两个子任务解耦,一方面扩展了用户交互形式的多样性,另一方面也降低了模型训练的难度,提升了性能和速度。
本文的一个重要观点是:应该直到用户获得了一个满意的mask后,再将该mask送入费时的传播模块中,这个交互过程可以进行多个轮次;不同轮次间输出的mask的差异,即为用户的指示信息,利用这个信息可以提升网络性能。
在Interaction模块中,通过多次交互,可以获得一个用户满意的mask,同时在训练过程中,通过设定existing mask的有无,来模拟Initial Interaction和Correction Interaction两种情况,提升了网络的泛化性能。
在Propagation模块中,通过双向独立传播,完成了整个视频序列的mask生成。
在Fusion模块,通过对比用户修正前后的修正帧预测mask的差异,捕获用户的指示信息,并通过Memory Bank,将其对齐至其他待处理帧中,提升了其他帧的分割性能。
3. Problem Statement
VOS分割的目标是较为广义的目标,并不是针对某个类别进行分割,即和一般的语义分割存在差异。一般根据是否需要额外的mask信息可以分为三类:
- 半监督VOS:在训练和推理过程中,除了提供要分割的视频帧序列外,还会额外提供部分视频帧的真实mask标注,一般是第一帧的mask。
- 无监督VOS:在训练和推理过程中,除了提供要分割的视频帧序列外,不会额外提供任何额外的mask标注信息。
- 半监督VOS:在训练和推理过程中,会交互式地提供一些类似于涂鸦的信息用于指示模型生成mask。
本文要解决的问题的领域即为Interactive VOS,也就是半监督VOS,目标是提升其泛化性和性能。
IVOS任务可以看做是两个子任务的结合:
- Interaction Understanding,即从交互中生成Mask。
- Temporal Propagation,即半监督VOS。
目前的方法使用Interconnected Encoders或者是Memory-Augmented Interaction Features联合完成两个任务,这种耦合性限制了用户的交互形式,并且模型需要同时理解用户的输入并将其逐帧进行传播,这使得训练较为困难。
而直接解耦两个任务,传播过程中由于缺乏考虑用户的指示信息,导致性能的下降。
4. Method(s)
为了解决以上问题,本文提出了一种解耦的模块化的Framework用于解决IVOS问题。
考虑到简单的解耦两个任务会导致在传播阶段缺失用户的指示,本文提出了一个Difference-Aware Fusion Module用于建模在经过用户指示前后生成的mask的差异。
通过解耦的方法,模型可以接受更多种类的用户的交互信息,并且取得了更好的性能。
首先,用户选择一帧图片并且交互式地进行标注,网络会基于用户标注生成一个mask。
然后,网络会基于该mask去为视频序列的所有帧生成其对应的mask。
在此之后,用户会检查生成的结果是否符合要求,如果有需要则会开始新的一个“轮次”,通过新的标注信息来修正错误帧。
定义r为当前交互的轮次,用户在r轮次交互的帧记为t^r,第r轮次的生成的mask results为M^r,则第j帧的mask记为M^r_j。
(1)MiNet Overview

Modular interactive Network(MiNet)包含三个核心模块:Interaction-to-Mask, Mask Propagation 和 Difference-Aware Fusion。
- Interaction Module以一种实时反馈的循环形式进行,使得用户可以获得实时的反馈,在更耗时的传播过程前获得一个满意的分割结果。
- 在Mask Propagation模块中,修正后的mask将双向传播至其他帧。
- 最终,Fusion Module会将传播得到的mask与当前帧进行融合,以引入用户的指示信息,用户指示信息则是通过Difference Aware Module来捕获。
Interaction-to-Mask
Scribble-to-Mask(S2M)
S2M的作用是基于用户输入的scribble,去实时地产生一个单帧分割结果。
S2M使用的是标准DeepLabV3p语义分割网络,其输入包含六个channel:RGB image, existing mask, and positive/negative scribble maps,而根据是否存在existing mask可分为两种情况:
- Initial Interaction:existing mask为空
- Corrective Interaction:existing mask包含错误
训练主要基于static image完成,对于每张图片,随机选择两种情况中的一种:input mask设置为zeros或者是通过随机膨胀腐蚀操作后的GT。
Local Control
用户可以通过限制交互式修正算法应用的范围来实现对局部区域的修正,而专注于部分细小的错误。
Temporal Propagation
采用和STM类似的方法,将过去的帧视为memory frames,而将当前帧作为query,然后基于一个Attention-based memory read operation去预测object mask,通过一个top-k filter operation来提升网络的性能和速度,整体流程如下图所示:

Memory Read with Top-k Filtering
使用两个Encoder:Memory Encoder和Query Encoder提取其特征,其中Memory Encoder除了RGB image以外,还有其对应的mask作为额外输入。
通过Top-k筛选,可以减少噪声的影响,提升性能和速度。
Propagation strategy
基于用户修正的mask,本文采用了一种双向独立传播的策略,用于完成整个视频序列的预测。
由于用户修正的mask一般已经得到了较为准确的标注,因此,当传播遇到用户修正的mask时,则会停止。
与STM类似,每5帧图片将会作为Memory Bank。

Difference-Aware Fusion
当传播过程由于遇到之前一个用户修正的mask而停止时,此时不同轮次的预测结果之间可能存在冲突,此时,需要对两个预测结果进行融合,之前的方法则是简单使用线性加权的方式进行融合,这种方法没有充分考虑到用户的指示信息。

用户的修正可以通过用户交互前后预测的mask来进行获取:
![]()
![]()
为了将用户交互前后预测的mask信息对齐到当前帧中,此时可以使用之前的STM模块的部分,将交互帧作为memory,而当前帧作为query,此时便可得到对齐后的当前帧的mask差异信息:
![]()
传统的线性系数也会使用,以缓解传播过程中可能的衰退现象:
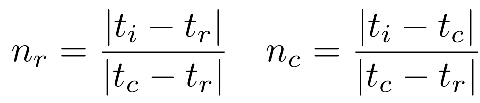
最终多个特征将会送入一个五层残差网络中进行mask的生成:
![]()
(2)Dataset:BL30k
提出了一个新的合成VOS数据集,规模大并且具有较高的标注质量,每个视频包含160帧图片,分辨率为768*512。


5. Evaluation
(1)结果对比

(2)消融实验



6. Conclusion
本文通过将人工交互和mask传播两个子任务解耦,并通过Difference Fusion模块在传播过程中引入用户的指示信息提升了模型的性能和速度,也降低了网络的训练难度。















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









