






1. 背景及需求说明
由于项目调试的需要,笔者需要临时在docker镜像中,对部分高耗时算子进行OpenCL加速。悲催的是,从docker hub官网拉下来的ubuntu22.04镜像中尚未包含相关模块,上述愿望直接落空。为了解决上述问题,笔者特地翻阅了多篇博文,并将主要流程及相关测试代码整理如下。
需补充说明的是,该文主要针对的是NVIDIA GPU及Intel核显设备进行的测试及代码验证,其余计算设备(如AMD系列显卡)在该文中并未涉及。
2. 步骤说明
* step-1: ubuntu2204宿主机上,安装nvidia-container-runtime库
* step-2: 创建docker file文件,并构建镜像
* step-3: 运行镜像
* step-4: demo代码验证
3. 具体实现细节
* step-1: nvidia-container-runtime
sudo apt install curl
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | \
sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
sudo apt update
sudo apt install nvidia-container-runtime* step-2: dockerfile
FROM ubuntu:22.04
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get -y upgrade \
&& apt-get install -y \
g++ \
apt-utils \
unzip \
tar \
curl \
xz-utils \
ocl-icd-libopencl1 \
ocl-icd-opencl-dev \
opencl-headers \
clinfo \
;
RUN mkdir -p /etc/OpenCL/vendors && \
echo "libnvidia-opencl.so.1" > /etc/OpenCL/vendors/nvidia.icd
ENV NVIDIA_VISIBLE_DEVICES all
ENV NVIDIA_DRIVER_CAPABILITIES compute,utility* step-3: 镜像的构建指令如下:
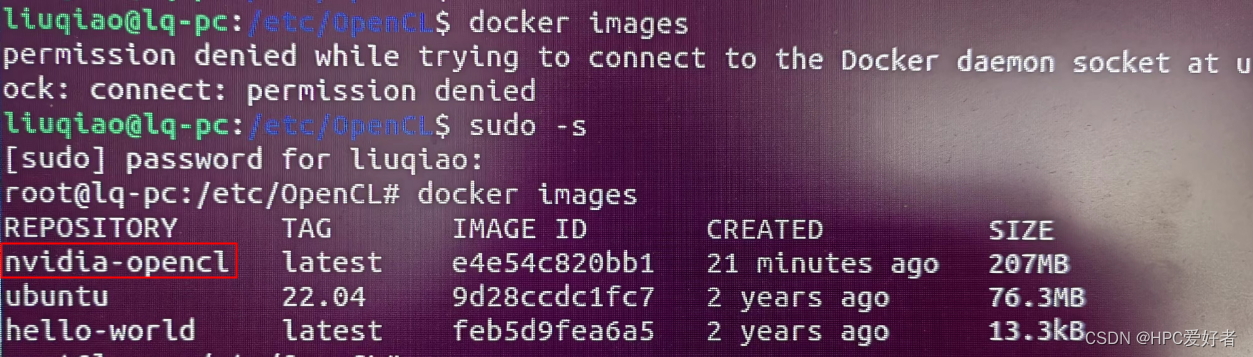
$ docker build -t nvidia-opencl .构建完成后的镜像信息,可通过"docker images"指令查看,结果如下:
* step-4: demo验证
#include <CL/cl.h>
#include <iostream>
#include <vector>
const std::string kernel_str = "__kernel void vector_add(global const float *a, global const float *b, global float *result) { "
" int gid = get_global_id(0); "
" result[gid] = a[gid] + b[gid]; "
"}; ";
int main(){
int err = 0;
size_t size = 0;
uint32_t platform_num = 0;
cl_platform_id platform{};
cl_context ctx{};
cl_command_queue cmd_queue{};
cl_device_id device{};
std::string param_val;
cl_program program;
cl_kernel add_kernel;
// step-1: platforms
err = clGetPlatformIDs(0, nullptr, &platform_num);
std::cout << "The num of platform is: " << platform_num << std::endl;
std::vector<cl_platform_id> all_platforms;
all_platforms.reserve(platform_num);
err = clGetPlatformIDs(platform_num, all_platforms.data(), nullptr);
for (int idx = 0; idx < platform_num; ++idx) {
// get the size of current platform name
err = clGetPlatformInfo(
all_platforms[idx], CL_PLATFORM_NAME, 0, nullptr, &size);
param_val.resize(size);
// get the string of current platform name
err = clGetPlatformInfo(all_platforms[idx],
CL_PLATFORM_NAME,
size,
const_cast<char *>(param_val.data()),
nullptr);
std::cout << "The platform name is: " << param_val << std::endl;
// NOTE: for 'CL_PLATFORM_NAME', you may get the following three items:
// (1) NVIDIA CUDA / (2) Intel(R) OpenCL Graphics / (3) ARM Platform.
// We chose intel graphics or arm firstly.
if (param_val.find("Intel(R)") != std::string::npos ||
param_val.find("ARM Platform") != std::string::npos) {
// NOTE: for Intel and arm device, they are unable to exist meanwhile.
platform = all_platforms[idx];
break;
}
if (param_val.find("NVIDIA CUDA") != std::string::npos) {
platform = all_platforms[idx];
}
// if the expected platform cannot still be found, print the error!
if (platform == nullptr) {
std::cout <<
"The expected OpenCL platform (Intel, Arm or Nvidia) cannot be found "
"in your device. The cl stream cannot be created now, please "
"reconfirm it again!" << std::endl;
}
}
// step-2: devices
uint32_t device_num = 0;
std::vector<cl_device_id> all_devices;
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, nullptr, &device_num);
if (0 == device_num) {
std::cout << "The expected OpenCL devices cannot be found in your device, "
"please reconfirm it again!" << std::endl;
}
std::cout << "The device num is: " << device_num << std::endl;
// get the all the devices id
all_devices.reserve(device_num);
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, device_num, all_devices.data(), nullptr);
for (auto idx = 0; idx < device_num; ++idx) {
err = clGetDeviceInfo(all_devices[idx], CL_DEVICE_NAME, 0, nullptr, &size);
param_val.resize(size);
// choose the first compute device by default
char buffer[100];
err = clGetDeviceInfo(
all_devices[idx], CL_DEVICE_NAME, size, param_val.data(), nullptr);
std::cout << "The OpenCL compute device is: "<< param_val << std::endl;
}
device = all_devices[0];
// step-3: context
ctx = clCreateContext(nullptr, 1, &device, nullptr, nullptr, &err);
if(err != CL_SUCCESS)
{
std::cout << "Unable to create the context!" << std::endl;
}
// step-4: cmd queue
cmd_queue = clCreateCommandQueue(ctx, device, CL_QUEUE_PROFILING_ENABLE, &err);
if(err != CL_SUCCESS){
std::cout << "Unable to create the cmd queue!" << std::endl;
}
// step-5: create program
const char *kernels_char = kernel_str.c_str();
program = clCreateProgramWithSource(ctx,1,&kernels_char, nullptr, &err);
if(CL_SUCCESS != err){
std::cout << "Unable to create the program with source!" << std::endl;
}else{
std::cout << "Create the program successfully!" << std::endl;
}
// step-6: build program
err = clBuildProgram(program, 1, &device, nullptr, nullptr, nullptr);
if(CL_SUCCESS != err){
std::cout << "The program isn't built successfully!" << std::endl;
size_t len = 0;
cl_int ret = clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0,
nullptr, &len);
std::cout << "The len of build info is: " << len << ", the return value is: " << ret << std::endl;;
std::vector<char> buffer(len);
ret = clGetProgramBuildInfo(
program, device, CL_PROGRAM_BUILD_LOG, len, buffer.data(), nullptr);
std::string build_log(buffer.begin(), buffer.end());
if (ret != CL_SUCCESS) {
std::cerr << "Failed to get build log" << std::endl;
}
std::cout << "Build log:\n" << build_log << std::endl;
}else{
std::cout << "Build the program successfully!" << std::endl;
}
// step-7: create kernel
const std::string kernel_name = "vector_add";
add_kernel = clCreateKernel(program, kernel_name.c_str(), &err);
if(CL_SUCCESS != err){
std::cout << "Unable to create the kernel!" << std::endl;
}else{
std::cout << "create the kernel successfully!" << std::endl;
}
// step-8: cl_mem
size_t length = 10;
std::vector<float> a(length, 1.f);
std::vector<float> b(length, 2.f);
std::vector<float> c(length, 0.f);
// step-9: create buffer
cl_mem a_mem = clCreateBuffer(ctx,
CL_MEM_READ_ONLY | CL_MEM_ALLOC_HOST_PTR,
sizeof(float) * length,
nullptr,
nullptr
);
cl_mem b_mem = clCreateBuffer(ctx,
CL_MEM_READ_ONLY | CL_MEM_ALLOC_HOST_PTR,
sizeof(float) * length,
nullptr,
nullptr
);
cl_mem c_mem = clCreateBuffer(ctx,
CL_MEM_WRITE_ONLY | CL_MEM_ALLOC_HOST_PTR,
sizeof(float) * length,
nullptr,
nullptr
);
// step-10: write buffer
err = clEnqueueWriteBuffer(cmd_queue,
a_mem,
CL_TRUE,
0,
sizeof(float) * length,
a.data(),
0,
nullptr,
nullptr
);
err |= clEnqueueWriteBuffer(cmd_queue,
b_mem,
CL_TRUE,
0,
sizeof(float) * length,
b.data(),
0,
nullptr,
nullptr
);
clFinish(cmd_queue);
if(CL_SUCCESS != err){
std::cout << "Unable to write data into cl_mem!" << std::endl;
}else{
std::cout << "Write data into cl_mem successfully!" << std::endl;
}
// step-11: set kernel args
err = clSetKernelArg(add_kernel, 0, sizeof(cl_mem), &a_mem);
err |= clSetKernelArg(add_kernel, 1, sizeof(cl_mem), &b_mem);
err |= clSetKernelArg(add_kernel, 2, sizeof(cl_mem), &c_mem);
if(CL_SUCCESS != err){
std::cout << "Unable to set kernel args!" << std::endl;
}else{
std::cout << "Set the args successfully!" << std::endl;
}
// step-12: run the kernel
size_t global_work_size[1] = {length};
int work_dim = 1;
err = clEnqueueNDRangeKernel( cmd_queue,
add_kernel,
work_dim,
nullptr,
global_work_size,
nullptr,
0,
nullptr,
nullptr
);
clFinish(cmd_queue);
if(CL_SUCCESS != err){
std::cout << "Unable to Enqueue NDRange kernel!" << std::endl;
}else{
std::cout << "Enqueue NDRange successfully!" << std::endl;
}
// step-13: read the data from cl_mem
err = clEnqueueReadBuffer( cmd_queue,
c_mem,
CL_TRUE,
0,
sizeof(float) * length,
c.data(),
0,
nullptr,
nullptr);
clFinish(cmd_queue);
std::cout << "1 + 2 = ";
for(const auto &ele : c){
std::cout << ele << ", ";
}
std::cout << std::endl;
}
上述测试代码最终可按照如下指令进行编译及运行:
$ g++ -o cl_env_test env_test.cpp -lOpenCL // 构建
$ ./cl_env_test // 测试运行4. 最终效果
上述构建完成的镜像最终可按照如下指令运行:
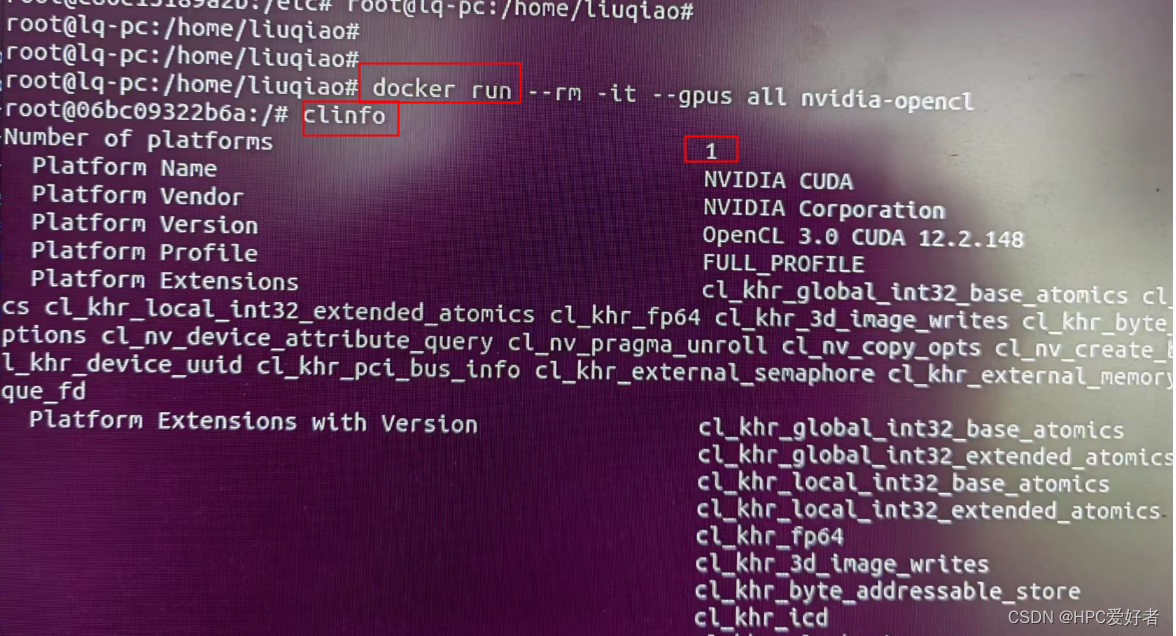
$ docker run -it --rm --gpus all nvidia-opencl而后输入指令"clinfo",以检索opencl设备,检索结果如下:
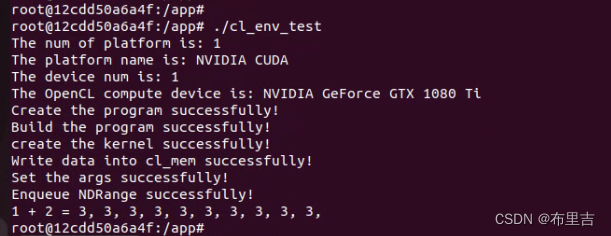
demo程序的输出结果如下:















 1487
1487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









