





上一篇文章,我们正式切入到对量化研究的探讨,并在机器学习的理念框架下展开。主题开得不小,但实现起来还是必须一步一步来。那么这一篇,我们就从数据和特征说起,围绕“标准化&自动化”展开我们的主题——自动特征工程(AFE, Auto Feature Engineering)

特征的重要性
在量化研究中,我们喜欢称呼特征为“因子”,称特征工程为因子挖掘。广义上来说,因子就是特定时间内与股票收益率存在相关性的数据指标,是量化建模的基础。业界经常将这句话奉为圣经——“数据和特征决定了机器学习的上限,而模型和算法只是逼近了这个上限而已”。对于量化模型来说,因子也同样如此重要。
一般来说
- 因子越好,灵活性越强:好的因子,即使只是使用简单加权排序,也能得到很好的效果
- 因子越好,模型越简单:好的因子,即使模型的参数不是最优参数,模型性能也能表现很好
- 因子越好,性能越出色;模型的性能包括模型的效果,执行的效率及模型的可解释性,这些都可以因为因子质量的提升而得到大大改善。

特征工程的痛点
然而好的因子,并非那么好挖掘。特征工程/因子挖掘通常有如下特点:
- 操作繁多,要求扎实的机器学习功底。特征工程的操作包括数据梳理、预处理、特征衍生、特征筛选,每个步骤基本都是必须的,每个步骤下面都有N多个可选的子操作,花样繁多,各有各的场景。
- 组合多样,且强依赖于领域知识。引用石川博士的一句话“任何策略都应该有一个理论先验”。由于操作繁多,理论上可以有无数种组合,但如果在没有理论先验的基础下,做纯粹的数据挖掘,那得到的因子的可解释性及可信赖度将大大受限。极有可能是,花了超大算力,最后却只得到一个过拟合的结果。
在刀耕火种的年代里,通常团队会采用堆人、手工的方式去积累因子。这样做好处很明显,能快速建立团队进行因子生产,但劣势也同样明显:
- 质量:手工特征工程质量欠佳
- 特征设计受到人类创造力和耐心的限制:我们只能建立能想到的特征,而且用来建立特征的时间也是有限的
- 特征质量不确定性大:容易
- 漏选特征,造成信息的缺失
- 选中无效特征,徒增计算量
- 忽略高级特征,不能最大程度地提高模型性能
2. 时间:缺少系统性的生命周期管理工具,团队之间无协作,开发效率低
-
- 开发:各自为战,缺少开发规范,可读性差、不易扩展、难以移植
- 留痕:特征改动频繁,却缺少配套版本控制工具,只能手工留痕开发过程和成果
- 生产:上线与监控使用原生的crontab,管理困难
- 共享:无协作共享机制,团队内难以形成协同效应

这是发展初期的必由之痛。痛可忍,长痛可不好忍。
解决方案
明确了痛点,我们就能梳理出我们的核心需求:
- 标准化:需要标准化各个流程,提供一个特征工程平台,承载特征的全生命周期管理,让研究员可以更加专注于因子研发之上
- 自动化:目标是让特征生成的过程更加智能化,包括各种算子的组合、参数的调优都可以由系统来处理,做到Auto Feature Engineering,而人需要做的,仅是用领域知识来限定数据输入、并对特征工程的结果进行验收评估。
对于不同的团队,可以采取的方案也不尽相同
有资金,有IT能力是最理想的情况。
这种情况下,可以允许我们购买成熟的AI中台解决方案来支持。现在的大多数机器学习相关的供应厂家,他们的系统都为算法开发提供的成熟的全生命周期管理,细节也做的相对妥当(需求1)。
而大部分厂家的系统,都会标配一个AutoML功能,而这个功能,正好可以作为自动化特征工程功能的基础。我们需要做的,仅是让IT团队在给定框架上,扩展量化所需的部分算子,即可复用平台的能力,做到特征工程自动化(需求2)。
- 优势:成熟的解决方案;
- 劣势:门槛高;定制化量化算子的过程有一定的开发量

资金充足,开发能力欠缺
这时,可以考虑直接购买现有的量化平台,如quantopian、以及国内三大矿。其底层都是基于quantopian的zipline、alphalens、pyfolio来支撑量化因子、策略的开发。量化开发的规范基本都定下来了,提供了标准的回测、留痕、上线、监控等标准功能(需求1)。
但也因为其功能已经是为量化研究而深度定制化过的,已经不好再在其上做大的改动。AFE的功能基本上很难实现(需求2)
- 优势:高度定制化的量化平台
- 劣势:难以定制化开发与扩展
资金与IT能力都匮乏
这是业余量化玩家遇到的困境,这种情况下,各个量化平台提供标准系统,不妨直接在上面建立研究环境,这比自己单独建一套轮子出来,要快捷的多。

资金少,有IT开发能力
这是本篇文章主要讨论的情景。这种情况下,我们可以充分组合利用现有的机器学习开源框架,在我们已有的量化中台的基础上,快速建立一套自研解决方案。
- 优势:门槛较低,可以快速完成系统的各个功能需求
- 劣势:需要团队有一定的IT能力,且初期功能较为粗糙有限,后期需要持续投入IT资源
特征平台架构
一、功能标准化
基于第四种情况,我们进一步来探讨。
首先是要解决标准化的问题,标准化后,才有自动化的可能。重点要标准化的功能包括:数据接入->特征衍生->留痕追踪->上线生产。而这4个功能,可以直接复用我们建立的量化中台来快速实现。
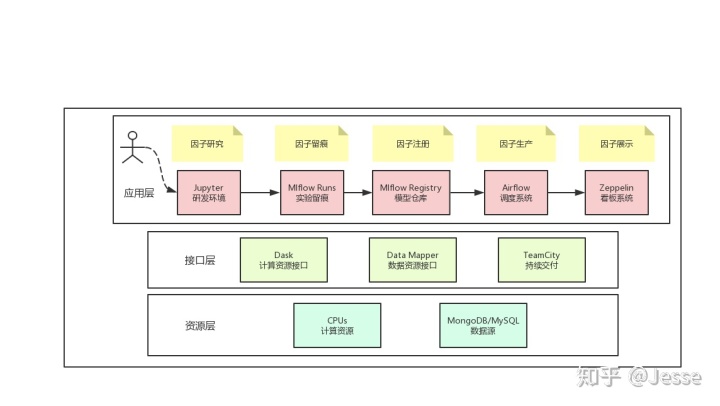
1. 数据接入接口化
数据管理一直是it团队的大头,水很深,这部分我们只讲量化数据读取和写入。设计时,我们采用Mapper模式。Mapper可以是一个简单的类包,也可以是一个Rest API,其核心的作用是提供这样两个接口:
- query_ts_data(table, start, end)
- insert_ts_data(table, data)
这样,我们就能将特征平台的所有功能与具体的数据库细节解耦开来,简化因子开发的取数/读数的功能
2. 特征工程算子化
在我们向量化回测文章中,我们曾提及过,我们会将信号的生成函数写成Transformer类的形式,这个Transformer,本质上就是一个算子。算子是实现特征工程额基本操作原子,是无状态的、且能够任意搭配组合形成管道的。算子化如今基本已经成为业界的标配了,如阿里的pai、第四范式的先知平台都采用标准化算子、拖拉拽的形式。

算子化的优势是明显的:一来算子是高度标准化的,开发后就自动具备极高的可复用性,有利于知识的沉淀和团队协作;二来,标准化的算子,是我们后期实现自动化特征工程的基础。
针对量化研究中的特征工程,一般要设计两种算子,分别对应二维数据和三维数据。
二维数据算子
2维数据是我们在机器学习中最常见到的数据集了。对应到量化中,有个股研究、大盘研究等基于单标的资产的场景。这块的处理方式和通常的机器学习数据处理并无太大差异。大部分功能直接使用sklearn即可实现。
值得一提的是pandas_sklearn这个包。pandas原本就是AQR开发出来,专门用来处理时间序列的。而pandas_sklearn这个包就起到了一个很好的桥接的作用,是能帮助我们在时序数据上充分使用机器学习功能的工具。
三维数据算子
目前大部分的单因子分析都是这种情况。此时特征的处理方式与2维稍有不同,在管道中流转的就不再是pandas.DataFrame了,而是xarray.DataArray。数据由3个维度构成:时间、属性、标的。因而,有部分特征工程操作需要根据xarray.DataArray重新定制。
量化的算子操作和传统的机器学习一样,包括预处理、特征衍生、特征筛选、特征评估。最具有量化特色的应该是特征评估算子,一般来说,二维的笔者喜欢用auc、iv值(woe)等方式对特征值分箱来评估特征的指标性能,三维的喜欢使用alphalens做全面的评估。当然,因为alphalens的计算方式是非向量化的,可以调试好参数以后,再采用alphalens进行可视化分析。
于是因子可以单独写成一个算子:
from sklearn.base import BaseEstimator, TransformerMixin
class OvernightJumpFactor(BaseEstimator, TransformerMixin):
# 隔夜价差因子
def __init__(self, n_period=1):
self.n_period = n_period
def transform(self, cubic_data) -> pd.DataFrame:
c = cubic_data.select_field('close')
o = cubic_data.select_field('open')
c_previous = c.shift()
jump = o / c_previous - 1
result = jump.rolling(self.n_period).mean()
return result也可以写成一个管道的形式
from sklearn.pipeline import Pipeline
# 沪深300股票的历史N个交易日的ohlc平均价格
mean_price_factor = Pipeline([
('data_loader', data_loader),
('roller', ma_roller),
('mean', averager),
])3. 开发全留痕
特征是针对特定数据而生成的,不同的特征工程操作,都有很可能产生极其不同的结果。而且通常情况下,要反复调整,才能生成令人满意的特征。每次调整,我们都需要记录下参数、特征操作的变动,以及对应的验收指标值的变动,以便与下次的实验进行对比。
这个流程相对简单,但是由于要反复进行,手工处理起来也会费时费力。
我们的对策也很明了,直接对接量化中台的mlflow服务。因为我们的因子是sklearn.BaseEstimator的子类,且其设计是符合sklearn对接口的要求,故而mlflow可为我们的因子提供留痕服务。
具体操作上,我们可以设计一个Tracker类,专门实现模型的mlflow留痕功能。
import mlflow
class MlflowModelTracker(object):
@staticmethod
def fetch_metrics(net_value):
pass
def experiment(self, model, X, y=None):
net_value = calc_net_value(model, X, y)
param_dict = model.get_params()
metric_dict = self.fetch_metrics(net_value)
with mlflow.start_run():
for key, value in param_dict.items():
mlflow.log_param(key, value)
for key, value in metric_dict.items():
mlflow.log_metric(key, value)
mlflow.sklearn.log_model(model, "model")4. 持续交付
这里的思路和我们提及的量化交易中台化一致。实现的方式很简单,我们将设计一个ci.sh脚本,脚本将完成所有的持续集成的工作。
脚本中的内容也很简单。考虑到因子一般是离线定期生产的,我们选择充分利用中台中的airflow功能。脚本做的第一件事,就是把因子代码复制一遍,打进一个python脚本模板之中。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# tag: airflow, DAG
factor = OvernightJumpFactor(25)
frequency = '1d'
server = FactorServer(factor, frequency)
dag = server.schedule()FactorServer的主要功能,就是调用airflow的python接口,动态产生一个包含DAG的工作流。之后我们将这个python脚本上传到airflow的dags文件夹,就能做到特征的实时生产。
相同的我们还可以定制一套定时效果监控脚本,定时调度,监控因子的绩效指标并能及时触发邮件告警。
当然,对于一般的因子,隔一段时间做调度是合适的,但如果对实时性有要求,那么单独起一个线程(Flask Rest API)也是一个可选方案。

5. 知识共享
以上4个步骤,能帮助我们快速的上线一个标准化的因子。因子上线后,当能被业务快速的观察及使用到,并且团队成员也需要能第一时间了解彼此的因子开发工作,互相辅助、避免重复开发,故而我们需要对因子库做一个可视化的看板系统。
追求极致精简的话,可以不需要开发复杂的oa系统,直接使用zeppelin的可视化组件,调用我们之前设计好的数据接入接口,即能实现看板功能。

至此,我们已经快速搭建好了一套简易的、标准化的特征全生命管理系统。
二、特征工程自动化
标准化做完了,是时候进入自动化时代了。
自动化特征工程,目前主要的思路有两种
- 深度特征合成算法DFS,十分适用于关系型数据集(featuretools)
- 基于AutoML算法,构建最小价值模型,通过 贝叶斯/遗传算法/模特卡洛模拟 等算法组合最优特征工程处理流程
笔者甚为喜欢第二种方式。这里推荐一个值得关注的开源项目TPOT。只要你提供了符合sklearn接口的算子,TPOT就能使用遗传算法,自动组合出最优的算子组合模式,并且将其参数调至最优。你需要做的仅是调包而已。

但调包这句话说的很简单,在实际落地当中,工程能力依然是必不可少的。
- 你还是需要深入了解sklearn的各个接口设计,需要设计的不仅有
Estimator,还需要有配套的Spliter、Scorer、Transformer等。 - AutoML 需要极大的算力支持,TPOT支持dask集群式的计算,那么搭建一套稳定的dask集群也是一份工作量。
但总而言之,我们通过几套开源框架,不需要深入automl的底层原理,就获得了一份AFE能力,还是物超所值的。这部分笔者也在逐步踩坑,以后有机会,还会做更多分享。

小结
以上,我们就完成了整个特征平台的架构。再一次,我们总结强调一下这套解决方案的优劣势。优势是”免费“,可以快速完成系统的各个功能需求,具备基础的全生命管理及自动化特征工程功能。但免费的代价是需要团队有一定的IT能力,且能持续投入IT资源进行优化。
最繁重的特征工程工作做完了,下一步,就该进入炼金术师们最沉迷的”模型炼金“了,量化中的圣杯究竟是怎么找的,我们就留待后续来讨论吧。
















 595
595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









