







 本文介绍了熵编码的基础,包括香农熵编码、霍夫曼编码和算术编码。重点讲解了ANS熵编码,包括uABS和rANS的编码与解码过程,以及在处理非均值分布数据时的量化处理,阐述了ANS编码如何无限接近熵编码理论值。
本文介绍了熵编码的基础,包括香农熵编码、霍夫曼编码和算术编码。重点讲解了ANS熵编码,包括uABS和rANS的编码与解码过程,以及在处理非均值分布数据时的量化处理,阐述了ANS编码如何无限接近熵编码理论值。
一、概要
在项目开发中,有引入用到rANS熵编码压缩算法,在使用的背后,想看看其运行的基本原理,也算补一下个人的熵编码知识。这里提到的熵编码压缩算法都是无损压缩。很久没有写文章了,太忙了,不知道一年一篇文章算不算年更 :b
二、熵编码
目前较为成熟的熵编码是霍夫曼编码,算术编码,以及14年Duda提出的ANS(Asymmetric Numeral Systems 非对称数系)编码。先解释一下霍夫曼编码和算术编码,然后重点说一下ANS编码的原理。
2.1 香农熵编码
熵在编码中,是对信息的衡量,熵越大,表明所包含的信息越多。对于高频出现的事件,其本身包含的信息其实是不多的,所以其对应的熵更小。而低频出现的事件,其包含的信息更多,对应的熵更大。香农的熵编码理论值计算公式为:
 ...(1)
...(1)
2.2 霍夫曼编码
霍夫曼编码是速度最快的熵编码,其基本原理是基于统计的频率,构建二叉树,最后高频率的字符用最短的编码表示,最低频率的字符用最长的编码来表示。其基本的操作就是不断构建二叉树的过程,借鉴示例用图1:
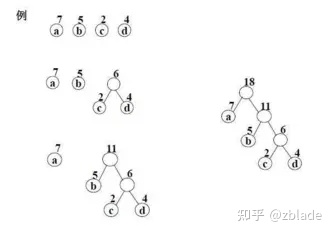
基本操作就是取频率最低的2个字符,搭建一颗二叉树,然后根节点频率为叶子节点之和,如此递归,得到最终的二叉树,示例中的编码结果:
a: 0
b: 10
c: 110
d: 111用编码替换输入的字符,即可得到最终的编码结果。 霍夫曼编码总结就是2个操作:构建霍夫曼树,执行霍夫曼编码。霍夫曼是执行速度最快的熵编码,但是其不能无限接近熵编码的理论值。
2.3 算术编码
算术编码是一种无限接近熵编码理论值的编码,其本质操作就是用一个[0, 1)的小数来表示最终的编码结果,其基本操作也是基于统计来进行的,用示例图来表示最直观[2]:
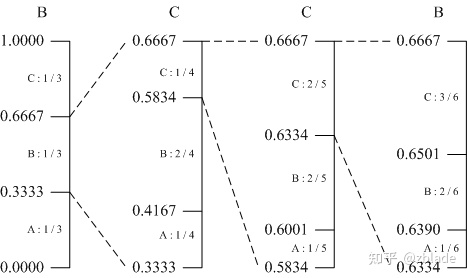
当前编码的字符为ABC三种字符,如何编码“BCCB”这个字符? 1)设定初始频率值,三种字符均值分布,则均为1/3,划分初步的概率分布; 2)输入B,其位于[0.333,0.667),则以此区间进行下一次划分,这是各个字符出现的频率进行更新,分别为1/4, 2/4, 1/4,得到最新的区间划分; 3)依次递推,最后编码所在区间为[0.639,0.6501),输出这个区间内的一个小数,例如0.64,转换为对应的二进制数即为最终的编码结果。 算术编码是一种能够接近理论值的熵编码,对应的代价就是算术的过程,速度慢。
三、ANS熵编码
项目中用到的编码是最近几年提出的一种新的熵编码,本着查看原理的心理去探究了一下这种最新的编码,很多文章都说的较为晦涩,不是我这样的小白能够理解的。在偶然拜读到一位国外大佬的文章后,通过详细的推导,总算大致了解了基本的实现原理,这里推荐有时间的可以看这篇英文原文:
Lossless Compression with Asymmetric Numeral Systems 结合这篇文章,我大致讲讲个人的理解:
3.1 将二进制字符串编码成自然数
从最简单的编码开始,假设一个字符串是以0/1字符串组成,如果用进制转换,我们都知道如何将其转换为10进制数。让我们展开来看:
假设我们已经转换了二进制字符串
 , 其对应的数值为
, 其对应的数值为
 ,如果我们得到一个新的输入字符
,如果我们得到一个新的输入字符
 ,我们希望基于一个基本的编码函数来得到输出的数值,假设为:
,我们希望基于一个基本的编码函数来得到输出的数值,假设为:
 ....(2)
....(2)
基于离散数学教程,如果还记得的话,这个公式是这样:
 ...(3) 为了区别"0"、“00”等情况,我们设定初始值:
...(3) 为了区别"0"、“00”等情况,我们设定初始值:
 , 反过来,我们可以从一个10进制数转换成对应的二进制字符串,其对应的函数可以表示为:
, 反过来,我们可以从一个10进制数转换成对应的二进制字符串,其对应的函数可以表示为:
 ...(4)
...(4)
举例来说明:
基于公式3和4,将字符
 转换成一个十进制数,
, 那么其转换操作为:
转换成一个十进制数,
, 那么其转换操作为:




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2513
2513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









