





微信公众号:AIKaggle
欢迎建议和拍砖,若需要资源,请公众号留言;如果你觉得AIKaggle对你有帮助,欢迎赞赏
Boosting算法的前世今生(下篇)
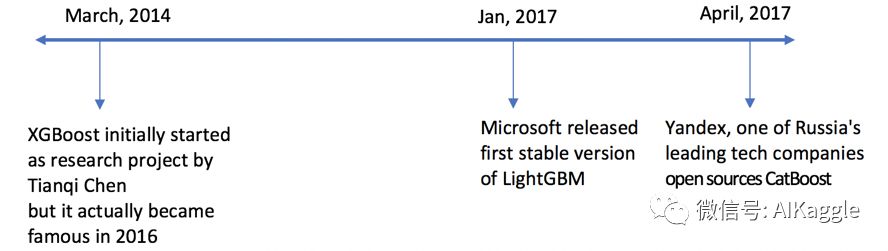
本系列文章将会梳理Boosting算法的发展,介绍Boosting算法族的原理,框架,推导等,Boosting算法的前世今生(上篇)介绍了AdaBoost算法和梯度提升树算法,中篇详细介绍了陈天奇教主提出的XGBoost算法,下篇(本文)将会介绍LightGBM算法,CATBoost算法。LightGBM算法由Microsoft Research提出,主打梯度提升算法的轻量级实现,他的两个创新点在于基于单边梯度的采样算法(GOSS)和互斥稀疏特征合并(EFB)。而CatBoost是由俄罗斯Yandex公司提出的,他嵌入了自动将类别特征处理为数值型特征的创新型算法,并且使用完全对称树作为基模型。如果对机器学习算法和实战案例感兴趣,也可关注公众号:AIKaggle获取算法动态
引言
LightGBM 的提出
单边梯度采样 GOSS
互斥特征合并 EFB
决策树生长策略
结果
CatBoost
关键创新点
处理类别特征
完全对称树
结果
Boosting算法发展流程
关注AIKaggle
赞赏Kaggle实战机器学习
引言
传统的boosting算法(如GBDT和XGBoost)已经有相当好的效率,但是在如今的大样本和高维度的环境下,传统的boosting似乎在效率和可扩展性上不能满足现在的需求了,主要的原因就是传统的boosting算法需要对每一个特征都要扫描所有的样本点来选择最好的切分点,这是非常的耗时。
LightGBM 的提出
LightGBM算法是由Microsoft Research提出的一种梯度提升算法的轻量级实现,发表论文为:"LightGBM: A Highly Efficient Gradient Boosting Decision Tree"。
梯度提升回归树(GBRT)是目前最流行的机器学习算法之一,它的几个具体实现包括 XGBoost 和 pGBRT 。虽然 XGBoost 和 pGBRT 在实现过程中已经采用了许多工程优化的技术,但是当涉及到庞大的数据量和高维的特征空间时,XGBoost 和 pGBRT 等算法依旧存在效率和可扩展性上的局限性。之前的算法实现非常耗时的重要原因是对每一个特征来说,XGBoost 和 pGBRT 都需要遍历所有的实例来计算最佳的信息增益,从而确定最优的分裂节点。
为了解决这些问题,LightGBM 算法采用了单边梯度采样方法(Gradient-based One-Side Sampling,简称为 GOSS)和互斥稀疏特征绑定(Exclusive Feature Bundling,简称为 EFB)。使用 GOSS 可以大量减少具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有大梯度的数据,大大减少了时间开销。由于具有大梯度的数据实例在计算信息增益的时候更为重要,所以在体量较小的数据集上使用 GOSS 能获得较为精准的信息增益估计。使用 EFB 可以将许多互斥的特征绑定为一个特征(互斥特征的含义为几乎不同时为零的特征),这样就达到了降维的目的。虽然将互斥特征进行绑定是一个 NP 难问题,但是运用贪心算法可以取得较好的近似结果,即在很少影响分割点的前提下有效地减少特征数目。使用 GOSS 和 EFB 的 LightGBM 算法对比传统的 GBRT 算法,能在实现近似准确率的前提下大大提高训练进程的速度。
单边梯度采样 GOSS



// Algorithm:Gradient-based One-Side Sampling
// 算法描述: 基于梯度的单边采样
输入:I:训练数据,d:迭代次数
输入:a:大梯度数据的采样比例
输入:b:小梯度数据的采样比例
输入:loss:损失函数,L: 弱学习器
模型models初始化:models = {}
常数fact初始化:fact = (1-a)/b
大梯度样本个数 topN = a * len(I)
小梯度样本采样个数 randN = b * len(I)
for(i = 1:d){
用现有模型对样本进行预测:
preds = models.predict(I)
计算梯度:
g = loss(I, preds)
分配样本权重:
w = {1,1,...}
将样本按梯度大小进行排序:
sorted = GetSortedIndices(abs(g))
选取大梯度样本:
topSet = sorted[1:topN]
随机选取小梯度样本:
randSet = RandomPick(sorted[topN:len(I)], randN)
合并大梯度样本和随机选取的样本:
usedSet = topSet + randSet
将随机采样得到的样本权重乘上常数:fact:
w[randSet] *= fact
在合并样本上最小化损失函数得到第i个模型:
newModel = L(I[usedSet], -g[usedSet], w[usedSet])
将第i个模型添加到现有模型中:models.append(newModel)
}


互斥特征合并 EFB
EFB 中文名叫互斥特征合并,顾名思义它就是将若干个互斥特征合并在一起。使用这个算法的原因是我们要解决高维数据稀疏的问题。在很多时候,数据通常都是几千几万维的稀疏数据,因此我们将不同维度的数据合并,使得一个稀疏矩阵变成一个稠密矩阵。这里就有两个问题,其一是如何确定应该合并的特征;其二是如何将这些特征合并到一起。
对于第一个问题,这是一个 NP 难问题。我们把特征看作是图中的点,特征之间的总冲突看作是图中的边。而寻找需要合并的特征且使得合并后的束数目最小,这可以看成是一个图着色问题,可以采用贪心算法。所以找出需要合并的特征且使得束个数最小的问题可以采用近似的贪心算法来完成,算法流程见下:
// 算法描述:贪心法合并特征
输入:特征 F, 最大冲突数 K
输出:束 bundles
构造图G
按照图中的度数排序 searchOrder = G.sortByDegree()
初始化束 bundles = {}
初始化束冲突 bundlesConflict = {}
for ( i in searchOrder){
初始化指针 needNew = True
for (j : len(bundles)){
计算当前冲突数
cnt = ConflictCnt(bundles[j], F[i])
if (cnt+bundlesConflict[i] <= K){
将当前特征添加到第j个束中 bundles[j].append(F[i])
更改指针的值 needNew = True
break
}
}
if (needNew){
把F[i]作为新成员添加到束bundles中
}
}
问题二是将这些束中的特征合并起来。由于在每一个束当中,特征的取值范围都不一样,所以我们需要重新构建合并后束中特征的取值范围。在第一个
for循环当中,我们记录每个特征与之前特征累积的总取值范围totalRange。在第二个for循环当中,根据之前的binRanges重新计算出新的箱值F[j].bin[i] + binRanges[j]保证特征之间的值不会冲突。这是针对于稀疏矩阵进行优化。由于之前贪心法合并特征算法对特征进行冲突检查,确保束内特征冲突尽可能少,所以特征之间的非零元素不会有太多的冲突,互斥特征合并算法流程见下。
// 算法描述:合并互斥特征
// algorithm: Exclusive Feature Bundling
输入: 样本数量 numData
输入: 一束互斥特征 F
输出:newBin, binRanges
初始化 binRange: binRanges = {0}
初始化 totalBin: totalBin = 0
for (f in F){
增加当前特征的取值范围 totalBin += f.numBin
添加totalBin进入binRange: binRanges.append(totalBin)
}
初始化新的箱
newBin = new Bin(numData)
for (i=1:numData){
初始化第i个新的箱 newBin[i] = 0
for (j=1:len(F)){
if (F[j].bin[i] != 0){
计算第i个新的箱值
newBin[i] = F[j].bin[i] + binRanges[j]
}
}
}
采用了 EFB 算法之后,数据特征从原来的特征数骤减为束数,从而有效减小了数据的特征规模,提高了模型的训练速度。
决策树生长策略
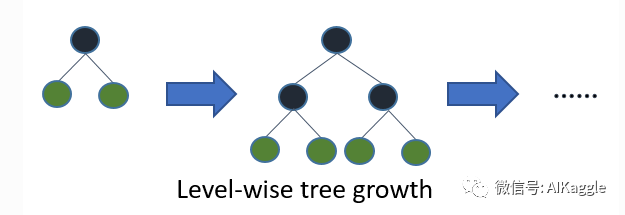
Level-wise
大部分决策树的学习算法通过 level-wise 策略生长树,记一次分裂同一层的叶子,不加区分的对待同一层的叶子,而实际上很多叶子的分裂增益较低没必要进行分裂,带来了没必要的开销。如下图:
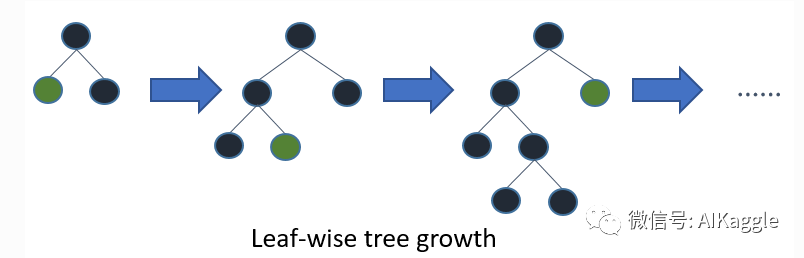
Leaf-wise
LightGBM 通过 leaf-wise 策略来生长树。每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。但是,当样本量较小的时候,leaf-wise 可能会造成过拟合。所以,LightGBM 可以利用额外的参数 max_depth 来限制树的深度并避免过拟合。
结果
数据集

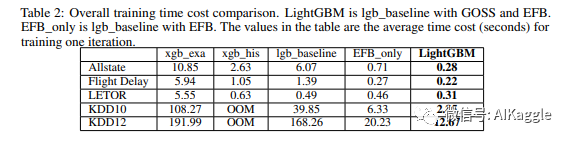
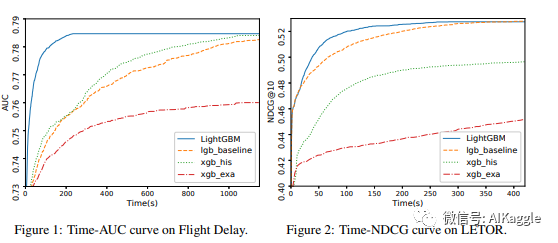
总体训练时间比较。(表格内是训练一轮的平均时间消耗,单位:秒)LightGBM代表运用了GOSS和EFB算法的lgb_baseline。EFB_only代表只运用了EFB算法的lgb_baseline。
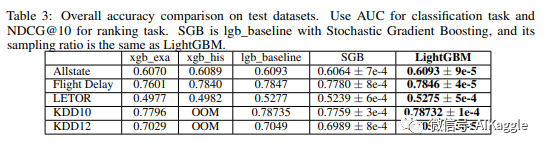
测试集上的Accuracy。分类评价指标:AUC,排序评价指标:NDGG@10。SGB代表运用了随机梯度提升的lgb_baseline,SGB和LightGBM采用了相同的采样比。
CatBoost
CatBoost是由俄罗斯Yandex公司在2017年4月提出的,当年发表了一篇论文
"CatBoost: gradient boosting with categorical features support",不过里面并没有对各种创新点进行详细的描述,在2019年初,Yandex公司又发表了一篇论文“CatBoost - unbiased boosting with categorical features”,在这篇论文里较为详细的描述了CatBoost算法的关键创新点。
关键创新点
CatBoost 有三个关键创新点,一是嵌入了自动将类别特征处理为数值型特征的创新算法,二是采用排序提升的方法对抗训练集中的噪声点,从而避免梯度估计的偏差,三是采用了完全对称树作为基模型。
处理类别特征


完全对称树
CatBoost 使用完全对称树作为基模型。XGBoost 一层一层地建立节点,LightGBM 一个一个地建立节点,而 CatBoost 建立的节点是镜像的。CatBoost 称完全对称树有利于避免过拟合,增加可靠性,并且能大大加速预测进程。
结果
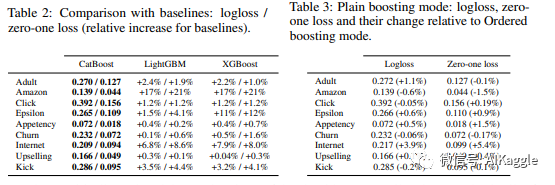
CatBoost的logloss结果对比,可以显示出比之前的算法有一定程度的减小(可是没有Accuracy结果的对比,所以不能进行更进一步的比较,根据我的几次实验结果,往往是LightGBM和XGBoos的提升效果更好)。
Boosting算法发展流程
之后NUS的同学们还提出了梯度提升算法在GPU上的高性能实现——ThunderGBM: Fast GBDTs and Random Forests on GPUs,由于篇幅原因,不在Boosting算法的前世今生(下篇)中介绍,可能会单独写一篇小的随笔介绍这篇论文包含的技术创新点。
关注AIKaggle

赞赏Kaggle实战机器学习
















 3325
3325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









