






更新:2020-2-27
之前,笔者在文中对FCOS学习center-ness使用BCE提出了质疑,认为BCE是用来学习01分布的,今天好心的网友在评论中指出笔者的这个质疑是不对的。后来,笔者思考了一下的确是不对的,BCE虽然总是用来学习01分布,即二分类问题,但不是01分布,只要在01之间的数也都能学习。原因很简单,我们回顾下BCE的公式:
其中
令上式等于0,显然,求得的结果是
因此,BCE的学习目标就是让输出
之所以笔者会犯这个错误,主要是“先入为主”了,最早对BCE的认识就是从伯努利分布中推导出来的,这个认识就惯性下去了,没有矫正,希望大家不要犯我这样的错误。
话说回来,那用MSE效果怎么样?反正解都是
然后,对于每一个label,笔者都画了一条loss曲线,
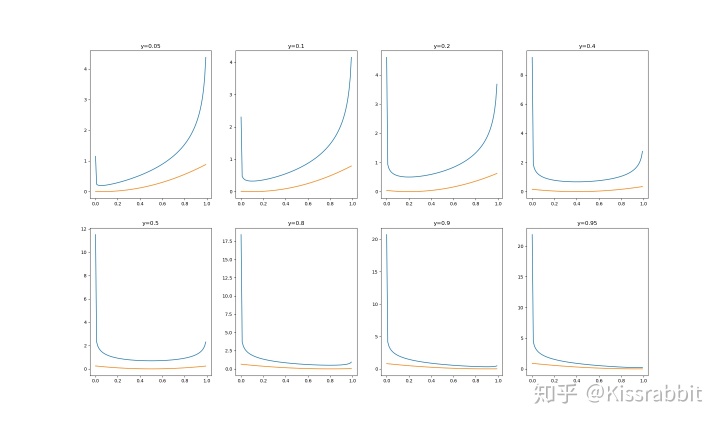
蓝线是BCE的,黄线是MSE的。大概能看出来,BCE在loss数值上是大于MSE,尤其是在0和1这两个极端值,由于log(1-x)和log(x)这这两项,容易导致loss巨大。而在梯度上,BCE提供的梯度要比MSE大一些,这或许有助于梯度的回传。总体来看,MSE在笔者设定的8个label值下,在输出为
但上述分析并不严谨,笔者还是更想通过实验来确定,,,,
总之,此次更新主要还是为了纠正对BCE的质疑。
自从实验室网坏了,我没法远程做实验了后,一下子没了正经事,有点空虚,所以决定讲一下FCOS这个工作。
为什么选FCOS来讲呢?
其实,FCOS出来的那一年,也有很多其他anchor-free的工作,不过,我很喜欢FCOS提出的那一套多尺度分配的方案,在yolo-v1的时候,它只用了最后输出的那个feature map,也就是单一尺度,配合上“网格”的这种,自然而然就有一个问题:当两个物体落在同一个网格中,怎么办?所以,早期单尺度的anchor-free碰到这个问题就完蛋了,后来靠着anchor box来解决。有了FPN后,我们就可以用多个feature map来解决。不过,这同时也有一个问题,哪些物体分配到哪个fmap上去呢?对此,FCOS则是从pixel-wise的角度来决定的。后面我们会仔细说一下的,这篇文章我不打算放到我的专栏《目标检测——基础与实践》中了,另外,我也会去复现这个工作,当然不是百分百复现,FCOS本身结构很大,输入的图像也是800x1000左右的,手里的资源不够,所以,我尝试复现一个轻量化版本的,努努力,不行就放弃,啊哈哈哈哈!
顺便安利下自己的专栏《目标检测——基础与实践》,面向目标检测这一块的新手,有讲解,有代码,模仿yolo-v1,yolo-v2实现了一些简单的detector,其中还贴上了我自己准复现的yolo全系列,性能也都还不错(仅在VOC上,尚未在COCO上测试,COCO难,目前还没有训练好)~~
好,那么开始进入正文!
我认为FCOS这篇工作的最大亮点就是在于多尺度分配的方法,解决了anchor-free情况下物体遮挡的问题。因此,在说它之前,让我们先来简单地回顾下YOLO-v1和anchor box的发展史。
1、早期的anchor-free的代表作——YOLO-v1
YOLO-v1是CVPR2015年的工作,在它问世之前,基于RCNN的各种改进版本是那个时候的主流,大家都想着如何给RCNN加速,不过在一些目标检测子领域,比如人脸检测,出现了one-stage的萌芽,其中之一就是UnitBox[1],这篇工作的创新点就在于用IoU Loss替换了以前MSE Loss来做bbox regression,如图一所示:
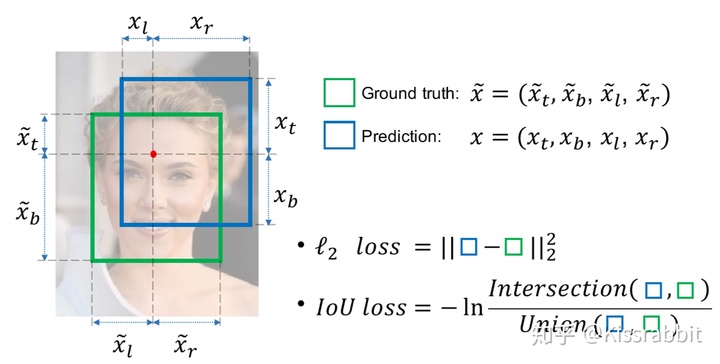
不过,似乎这个工作在那时候并没有得到太多的关注,two-stage的鼻祖RCNN仍是主流(准确来说,RCNN其实是three stage,不过后两个stage捏成一个stage也是可以的),后来Fast RCNN也出来了,精度更高,可是速度上,并没有体现出Fast,离real-time detection还差得远,这里我需要额外补充一段:
在Fast RCNN那个时代,并没有现在这么好用的深度学习框架,GPU也比不上现在,CUDA和cuDNN这种对加速深度学习的技术也不完善。如今2020年,我们手里有pytorch,有tensorflow,各种高性能GPU,还有更好的CUDA和cuDNN,这些技术的发展都为real-time detection带来了很大的技术支持,使得很多原本较慢的model,放到现在的技术条件,都可以跑得更快。所以,有的时候在和以前的工作做对比的时候,一定不要忽视那个年代的技术和当下 的差距。
直到2015年的CVPR,YOLO-v1[2]横空出世,初生牛犊不怕虎,在速度上各种吊打RCNN、Fast RCNN,不光速度快,在精度上,YOLO-v1虽然比不上它们,但也没差到哪去:
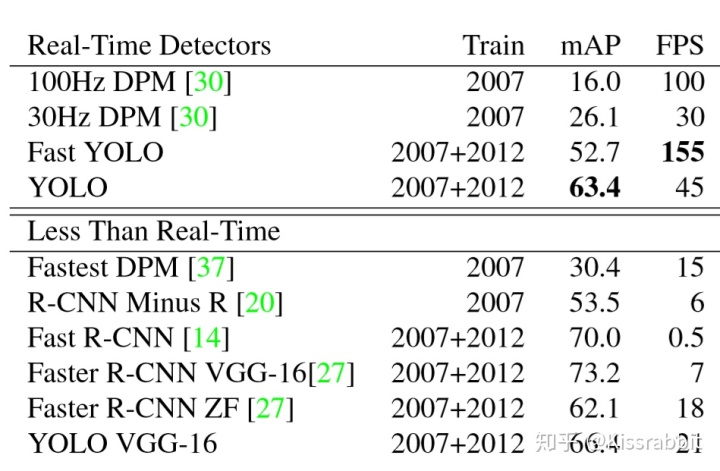
并且,作者还给出了Fast YOLO,YOLO-v1的轻量化版本,无论是原版的45FPS还是轻量化版的155FPS,YOLO-v1所带来的影响是深远的。虽然不能说YOLO-v1是one-stage real-time detection的开山之作,但不得不承认,YOLO-v1的地位是很高的。
那么,YOLO-v1为什么这么快呢?
既然是要找图片中的物体,RCNN的路子是先搜索,把一堆RoI提出来,然后逐个RoI去看,分别是啥是啥。YOLO-v1寻思你这太麻烦了,反正都是要“查找”嘛,那我就画个

从技术细节上来看,YOLO-v1是通过这个网格来找物体的中心点,找到了中心点,也就是找到了object instance,完成了detection。至于画框,通过从数据中来学习,YOLO-v1直接输出bounding box的四个参数:中心点两个坐标和框的长宽:
综上,YOLO-v1就是通过这种“网格”的方式来找物体的,而这种“网格”的思想,几乎成了今后所有one-stage的范式,无论是SSD还是RetinaNet,都有这种“网格”的思想在其中。
然而,问题就来了:
如果两个物体的中心都落在了同一个网格,而一个网格只检测一个物体,那YOLO-v1该检测谁?
相信看过吴恩达老师的deeplearning.ai的深度学习课程,都应该对这个问题有印象。没错,这个问题就是YOLO-v1的死穴。一个很直接的解决办法就是:让一个网格同时预测多个物体就好了啊!是啊,这个想法很直接简单,但这也会带来另一个问题,同于预测多少个物体?5个?10个?这没法定,而且那时候还没有盛行FPN的多尺度思想。
就在这个问题一筹莫展之时,隔壁老大哥RCNN刚进化成Fast RCNN没多久后,就又开始超进化了!
Fast RCNN:劳资要巩固在OD的地位!
于是Faster RCNN[3]出来了。我们暂且不提这个工作的技术细节,只谈贡献。Faster RCNN的最大贡献在于两点:Region proposal Network(RPN)和anchor box。
对于RPN,其实不难发现,RPN也是“网格”思想的产物,RPN的作用就是end-to-end给出RoI,替代了以前的费事费力的selective search算法,加速了two-stage 中的第一个阶段,给出的RoI再由前任老大哥Fast RCNN利用RoI Pooling技术来试别出类别。那么,RPN应该如何给出RoI呢?况且,“网格”的弊端前面也提到了,该怎么解决呢?于是,anchor box就提出来了:
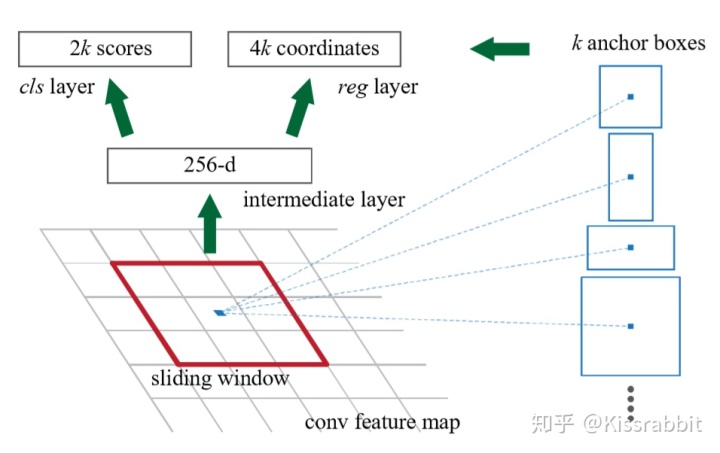
其思想很简单:我们在feature map的每一个位置上都设立K个anchor box,对于给定的一个真实框gt box,我们用这些anchor box分别和gt box计算IoU,选出最大或者IoU大于给定阈值的anchor box作为positive example,如果,这个位置有物体重叠了,也不用担心,我们有k个呢,一个anchor box匹配出去了,我们还剩下好几个可以接着去匹配另一个目标。这里我们也不用非得纠结于中心点这一处的anchor box,中心点周围的也可以。总之,anchor box很漂亮地解决了物体重叠的问题。
有了anchor box,RPN就通过这些anchor box(我们也称之为先验框)去找物体,然后调整一下它(bbox regression)就可以把它输出来作为下一个阶段的RoI了。
于是,Faster RCNN又一次让将wo-stage推向了一个高峰。然而,正当我们这位刚完成超进化的老大哥沉浸在胜利的喜悦中时,隔壁YOLO-v1再一次投来意味深长的目光……
2、YOLO-v1进化——YOLO-v2
上回说到,Faster RCNN凭借RPN+anchor box的新技术改良了Fast RCNN,为two stage家族添上了新武器。YOLO-v1一看,呦呵!anchor box,这好用啊,正愁俺这“网格”问题不知道咋解决呢。同时呢,好多DL的trick和好东西都出来了,YOLO-v1这四处一看,到处都是宝啊,于是,我们就在YOLO-v2的文中看到了这样有意思的一幕:
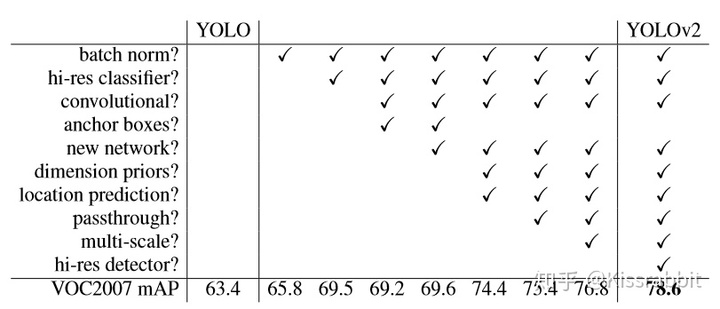
BN!——first blood!
darknet19!——double kill!
anchor box+kmeans!——triple kill!
multi-scale training!——quadra kill!
hi-res detector!——penta kill!
于是,在一堆trick的狂轰滥炸下,力压同期ECCV 2016的另一个很出色的SSD,并且吊打板凳还没坐热乎的Faster RCNN老大哥。
但是呢,我们稍微冷静一下,仔细看看YOLO-v2有什么很新颖的创新点吗?笔者认为是没有的。不过,YOLO-v2的工作中,有两点是很特色:
- 这之前,大家都是用ImageNet pre-trained model来作为backbone,而这些backbone只见过
的图像,没见过
这些大更大的图片,所以,要是冷不丁让人家“小眼睛”瞅大图,有点强人所难!所以,YOLO心里寻思,俺得让你先瞅瞅啥叫”大图“才行,就这样,YOLO把darknet19在
上fine-tune了10个epoch后,然后再来做backbone,结果,mAP涨点了,YOLO点点头,心里很美滋滋的。
- 老大哥Faster RCNN中的anchor box的长宽比、面积大小都是人工设计的,YOLO寻思这玩意很不AI,虽然咱AI现在是没有A(人工),就没有I(智能),不过,咱好歹得往这个大方向奔啊!于是,YOLO就在VOC数据集上用kmeans方法聚类出k个框,作为先验,有了这些先验,网络只需要输出一些小的增量
来微调anchor box就行,这一招就叫”dimension prior+location prediction“,一下子mAP涨了不少。此时此刻的YOLO-v2,感觉自己的查克拉已经快爆棚了!
上面两点,就是YOLO-v2的独到之处。凭借这些新奇的技能,再一次地在OD江湖中巩固了自己的地位,从这开始,YOLO-v2就踏上了独孤求败之路,渐渐地,隐退江湖。(各位抱歉,我有点收不住了,我想把v3也讲了,哈哈哈哈哈哈哈哈哈!)
在YOLO-v1完成进化,成为YOLO-v2,并且拳打Faster RCNN老大哥,脚踹SSD小老弟(这里是艺术夸张了,实际不是这样,大家一笑了之即可,不要在意),威震四方后,内心中却感受到了强者的孤独,头发也不知不觉稀疏了不少,于是选择了隐退(其实就是作者跳坑了,又是研究GAN,又是外出旅游,没事还总逛推特)。然而,殊不知,这一走,OD江湖却又一次血雨腥风了起来。
前有Faster RCNN老大哥扶持Mask RCNN一鸣惊人,后有装载Focal Loss内核的RetinaNet勇夺one-stage最强的称号,多尺度FPN更是紧随其后,而这一切的背后,都指向了一个姓何的大佬。但这场新的风云并未就此结束,不甘寄人篱下的SSD换上新装,化身RFBNet与DSSD,重回江湖。CornerNet更是靠着为keypoint prediction的鬼斧神工半路杀出。在这一次的新的江湖纷争中,各路门派如雨后春笋,层出不穷。一时间,one-stage流派的风头逐渐压过了two-stage,而one-stage流派内部,更是拼得天昏地暗。
直到2018年的某一天,曾经的那个王者,回来了。
在他不断的这段时间里,各种新技术遍地开花,于是,他将眼神又一次盯上了各大门派的武功秘籍:
Residual Connection不错,装上——DarkNet-53!拎起ResNet就是一顿胖揍;
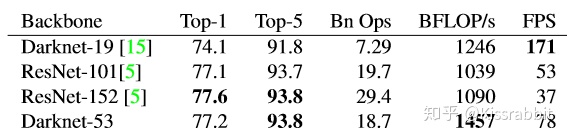
FPN,DSSD,多尺度,反卷积?不错,装上——谁还说我小目标检测不行?!

Focal loss,看起来有点意思,装上——啥玩意?咋不好使呢?是不是俺没用明白?算了,扔了。
总之,在吸收了各家门派的精髓之后,曾经的那个王者,卷土归来!
YOLO-v3[4]!
一个能打的都没有……
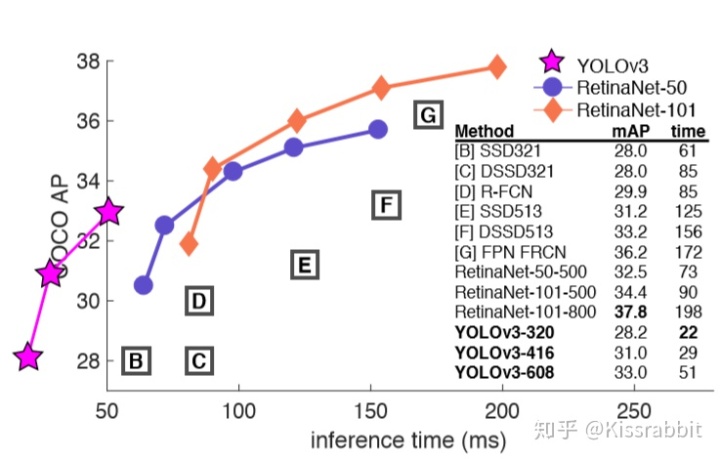
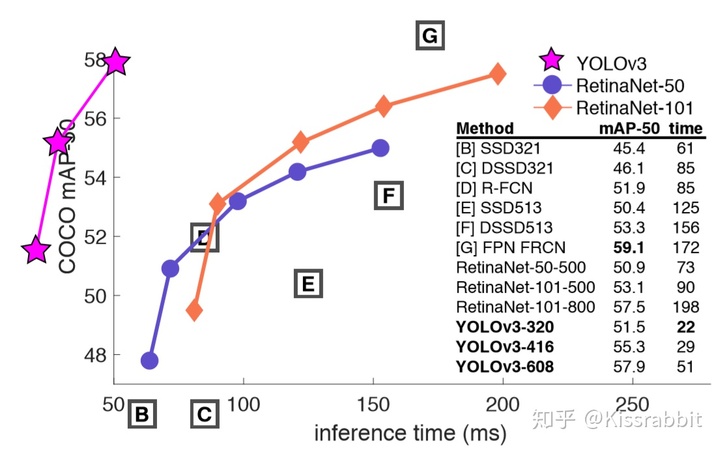
AP50和RetinaNet一样,但速度上却快了将近3倍!小老弟,孰强孰弱,心里总有点数了吧~
这一刻,大家再一次想起曾经被YOLO支配的恐惧……
话再说回来,无论这场纷争多么激烈,大家都有一个不变的内核,那就是anchor box。不管各家门派的武功是多么花里胡哨,其内在,仍是共通。
anchor-based的时代也够久了,该让让位了。
一股暗流,开始涌动。某处,有人已经盯上了anchor box,因为这个统治江湖多年的内核却有着内在的弊端:
- anchor box需要人工设计长宽比,面积,数量。纵然YOLO-v2给出了kmeans方法,却也不过是将人力换成了计算机算力,换汤不换药。这些超参数为OD带来了不必要的冗余;
- 无论多么精心设计anchor box,只要这个模型训练完了,这一切就成了定数,一旦遇到他从未遇见的数据(与训练数据的分布有较大的偏差),anchor box的泛化问题就不可避免了;
- 为了提高recall值,各大门派通常都会增加anchor box的数量,这无疑会对内存占用和计算力消耗带来负担。
- 这么多anchor box,后处理(post-process)的压力也大啊!
意识到了这个问题,各家门派之上,再一次蒙上了新的一团乌云。
3、anchor-free强势归来——FCOS!
在意识到anchor box的种种弊端之后,沉睡许久的anchor-free,再一次苏醒。
2019年,代表着旧势力的FCOS(Fully Convolutional One-Stage Object Detection)以全新的样貌强势回归,在这场OD争夺战中,脱颖而出!
在这之前,anchor-free这一one-stage的开山流派的消沉主要有以下几点原因:
- 首先是YOLO-v1。在YOLO-v1中,positive sample只有中心点所在的网格,其他都是negative sample,这对recall带来了很不好的影响。
- 物体重叠。这是个老问题,后来被anchor box解决了,但是,anchor-free就真的解决不了这个问题吗?
问题1的解决方案:
这两个问题一度让anchor-free陷入低迷,最终被遗忘。为了重振雄风,FCOS提出了一系列的解决方案:我们不应该只看中心点的网格,只要这个网格处于gt box的框内,我们就应该都视为positive sample。因此,FCOS不再只学习预测中心点,对于每个位置,我们学习预测它到gt box的上,下,左,右的四个距离
这里需要注意一点的是,上面的计算是在feature map的尺度上计算的,因此,为了判断fmap上一个位置
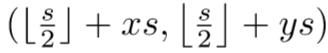
其中的
于是,FCOS通过将gt box所有覆盖的所有网格都作为正例,来提高recall,并且预测使用了相对位置

问题2的解决方案:
虽然问题1解决了,但是这种方法下,物体重叠的问题反而加重了,以前的YOLO-v1只是担心物体的中心点重叠,只要中心点不重叠,两个物体的gt box怎么重叠都无所谓。但是,由于FCOS的这种思想,一旦两个gt box发生重叠,那么重叠区域的样本应该作为谁的正例呢?
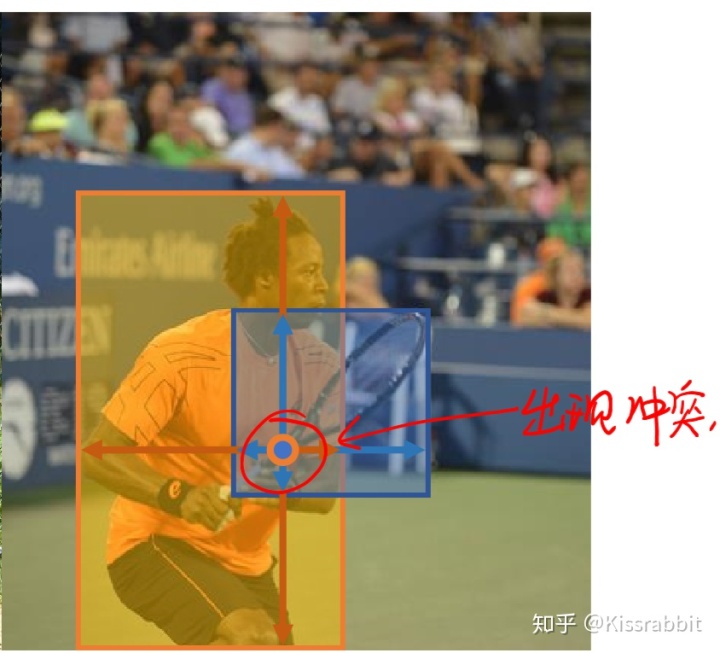
不过,请诸位放心,FCOS对此早有对策,原文中一开始提到了个很naive的方法来解决这个问题,不过,既然naive,咱就不提了,毕竟FCOS后面给了个更好的办法!说到这个问题之前,我们再回顾一下YOLO,YOLO-v1只用到了最后一个feature map,YOLO-v2也是,而后来FPN的工作问世,告诉了大家:我们可以在多个feature map上去做预测,并且不同尺度(
FCOS使用5个fmap:
这个阈值怎么用呢?
首先,我们要遍历每一个fmap的所以位置,对于一个fmap
为什么这样就可以保证多尺度了呢?
我们以上图的蓝框和黄框为例,很明显,更小的蓝框中算出来的所有的
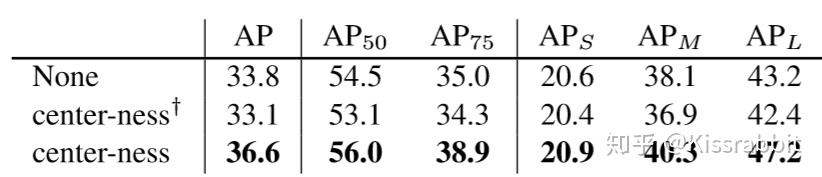
因此,FCOS不仅有了多尺度预测的能力,还很漂亮地解决了物体重叠的问题。看一下论文中放出的数据:

可见,使用FPN的技术的确带来了很大的提升!
完美~

到此,FCOS既增加了正例样本个数,还解决了物体重叠的问题,可以说是很excellent了。
但是,FCOS又往前走了一步。一个gt box中这么多点,它们的贡献都应该是一样的吗?我们再看一下下面这个图:

bounding box的作用其实是想告诉我们目标在图像中的哪个地方。按照FCOS的思想,不包含目标的像素也会成为正例,就比如上面图中的左上角小部分,都是背景,没有人的像素,因此,FCOS认为,这样地方的预测应该贡献小一些,而包含物体的像素应该贡献大一些。在这个很自然的想法的驱使下,FCOS又加了个新装备:center-ness:

center-ness的作用就是加大中心点附近的贡献,离中心点越远,贡献越小。其实,仔细想想,这就是YOLO-v1的中心点即正例的soft版本——我不只取中心点,但我也不是很想要离中心点远的样本,可是呢,也不能就这么扔了它们,于是,hard变为soft,既然不能舍弃你们,那就让你们的贡献小一些吧。
对于每个位置,其center-ness的学习目标如下:
由于这个值的范围是在0,1之间,因此,FCOS就用BCE来学它。center-ness相对于对每个位置预测的bbox的置信度,因此,在test的时候,将预测的center-ness的值乘到类别置信度上去,用二者的乘积作为最终的
最后的Loss 函数中,类别损失使用Focal Loss,bbox损失用IoU,center-ness损失用BCE。
齐了!
于是,新一代的anchor-free巨作诞生了!
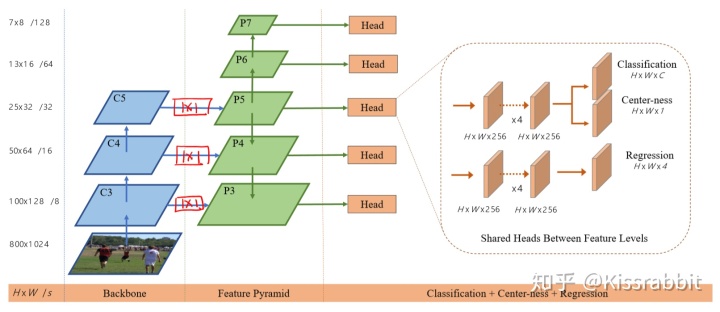
这里还有个小细节需要说一下,FCOS所使用的backbone是ResNet-50,而所有的fmap的detection head部分是权重共享的,但是,FCOS考虑到了一个问题:不同尺度的fmap预测的物体大小也不同,从bbox预测的角度来讲,这种共享合理吗?FCOS给出的答案是不合理,为了缓和这个问题,在每个尺度负责预测bbox四个参数的
就这样,anchor-free的大旗再一次被扛起,FCOS在江湖中混得是风生水起,OD的格局又一次被重新洗牌。
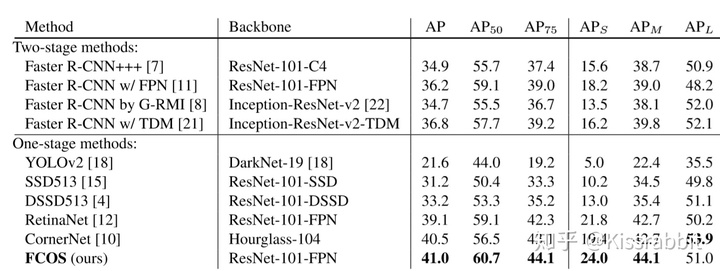
对比结果一上来,FCOS直冲one-stage顶峰,就问还有谁?还有谁?!
然而,YOLO-v3看了半天,只想问一句,为什么表中没有我?
好了,故事讲完了,FCOS的论文细节都讲出来了,至于代码上的实现细节,由于笔者没有去看过源码,因此暂且不清楚。不过,笔者有一个问题:
FCOS使用的图片输入是
最后,既然FCOS讲了这么多,笔者手有点痒,就按照它的思想,写了个demo尝试了一下(不是复现呦~),大家可以看笔者的另一篇文章:
Kissrabbit:目标检测——FCOS-LITEzhuanlan.zhihu.com不过,由于只是demo嘛,所以没有花心思去设计里面的参数,效果也只是能够看看,大家不要太较真哈~毕竟没卡嘛!
那么,FCOS讲完了,希望大家能喜欢,能从中有所收获。有什么问题,欢迎在下面留言!
参考文献:
[1]. Yu J, Jiang Y, Wang Z, et al. UnitBox: An Advanced Object Detection Network[C]. acm multimedia, 2016: 516-520.
[2]. Redmon J, Divvala S K, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]. computer vision and pattern recognition, 2016: 779-788.
[3]. https://arxiv.org/pdf/1506.01497.pdf
[4]. Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[J]. arXiv: Computer Vision and Pattern Recognition, 2018.
[5]. Tian Z, Shen C, Chen H, et al. FCOS: Fully Convolutional One-Stage Object Detection[J]. arXiv: Computer Vision and Pattern Recognition, 2019.














 1543
1543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









