






多⽬标排序介绍
为什么要有多⽬标排序:
⼯业界推荐系统多基于隐式反馈
• Global bias:不同⽬标表达不同的偏好程度;• Item bias:单个⽬标衡量不全⾯(标题党);• User bias:⽤户表达满意度的⽅式不同;• 综合⽬标收益最⼤化
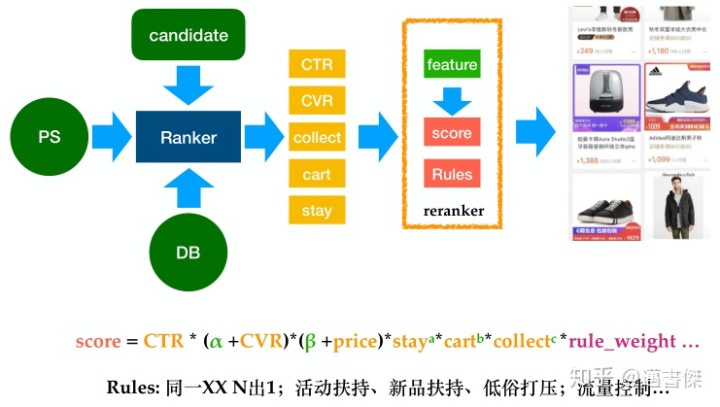
多⽬标排序的难点:
多⽬标 vs CTR预估;• 部分⽬标数据稀疏,模型准确率低;• 在线服务计算量⼤;• 多个⽬标间重要性难以量化;• 分数融合的超参难以学习(• ⼈⼯标注为label;• 长期⽬标为label);• 规则不够智能化
• learning to rank
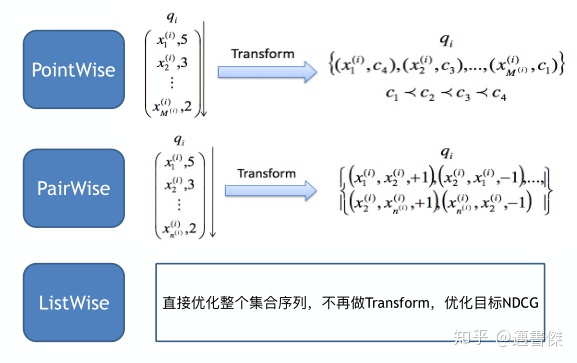
LTR evaluation-MAP:

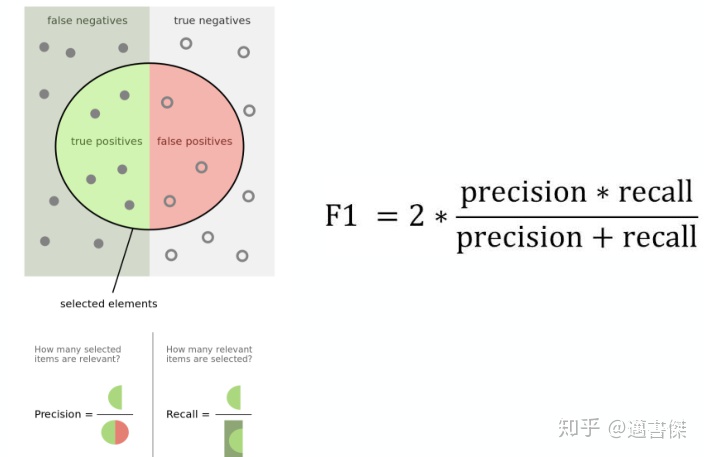
LTR evaluation-F1 score:
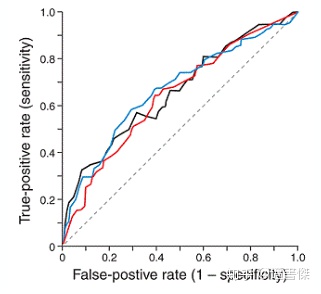
LTR evaluation-AUC:
AUC:Area Under ROC curve,ROC曲线下的⾯积,取值范围为[0.5,1]。
AUC的直观意义:当你随机挑选⼀个正样本以及⼀个负样本时,当前的分类算法将这个正样本排在负样本前⾯的概率。
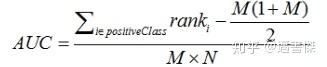
AUC越⼤,分类器的准确性越⾼。
LTR evaluation-nDCG:

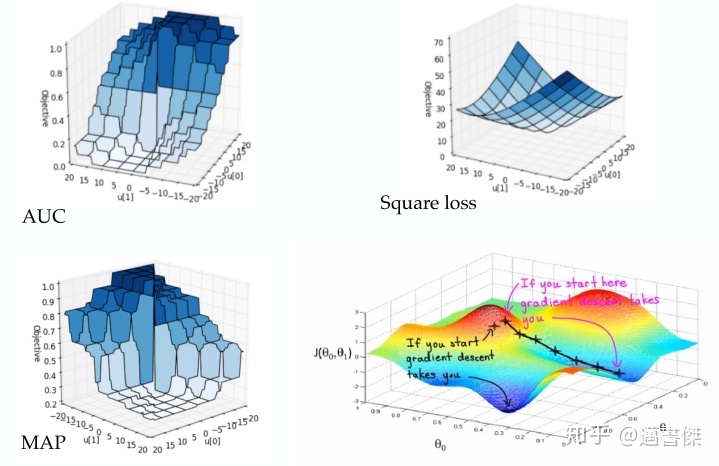
Non Smoothness:
Bayesian Personalized Ranking:
每个⽤户之间的偏好⾏为相互独;同⼀⽤户对不同物品的偏序相互独⽴;表⽰⽤户u对i的偏好⼤于对j的偏好;i>u j满⾜完全性,反对称性和传递性
最⼤后验估计

• BPR-BPR推导

BPR-MF:
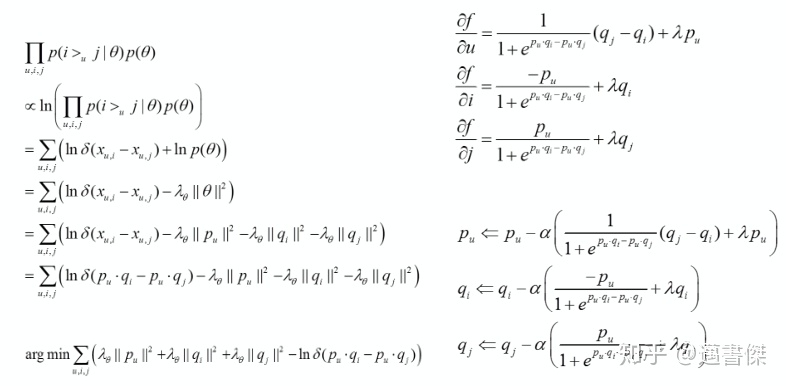
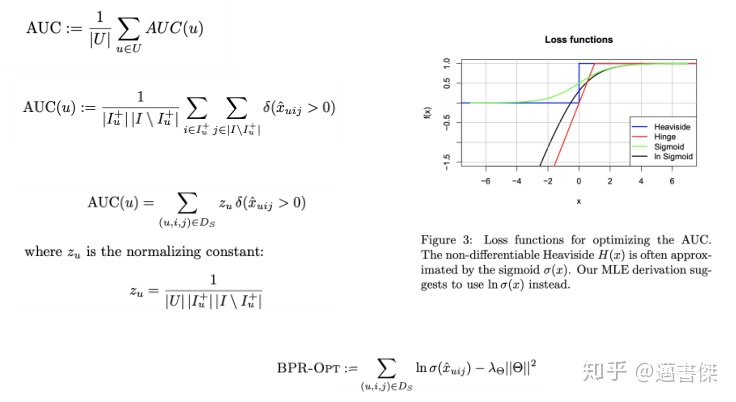
BPR-AUC analogy:
RankNet:
常见的排序指标⽆法求梯度;通过概率损失函数学习Ranking Function;两个候选集之间的相对排序位置作为⽬标概率;交叉熵(cross entropy loss function)作为概率损失函数

优化逆序对数(13->11);希望出现红⾊箭头的趋势;直接优化NDCG
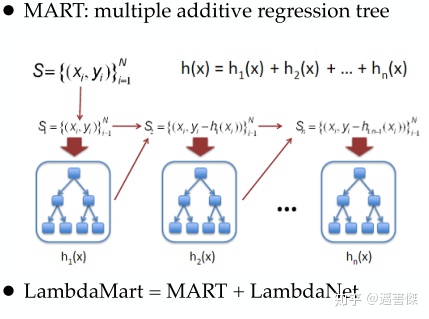
LambdaMart:
训练模型只需要⽤到梯度,⽽不是损失函数本⾝;直接定义损失函数的梯度:lambda梯度;更关注位置靠前的优质⽂档的排序位置的提升


Learning to Rank优缺点:
优势(直接优化排序⽬标,排序效果好;单模型融合多⽬标,serving压⼒⼩)
劣势(样本数量⼤,训练速度慢;有些偏序关系不容易构造;多⽬标间的关系不易调整)
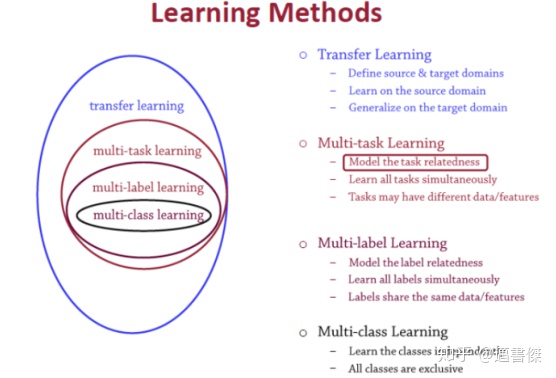
• Multi-task learning
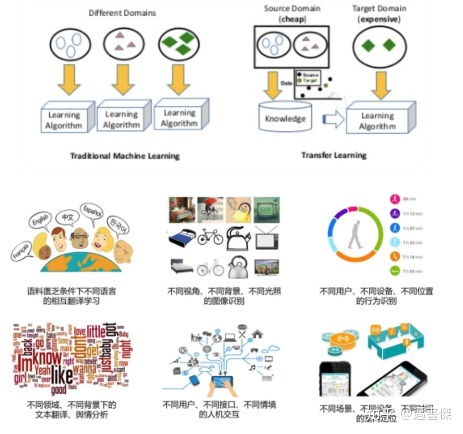
transfer learning:
• MTL介绍
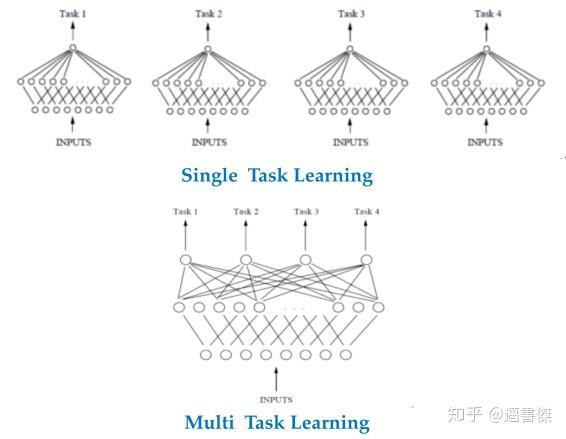
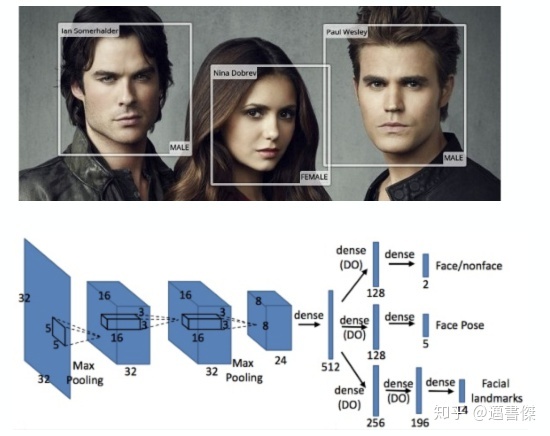
为什么MTL有效:
前提:多个任务具有相似性,可以共享底层特征• 解决数据稀疏问题• 不同模型善于学习不同特征,特征学习更充分• 引⼊归纳偏置(inductive bias),提⾼泛化性
MTL for FM:
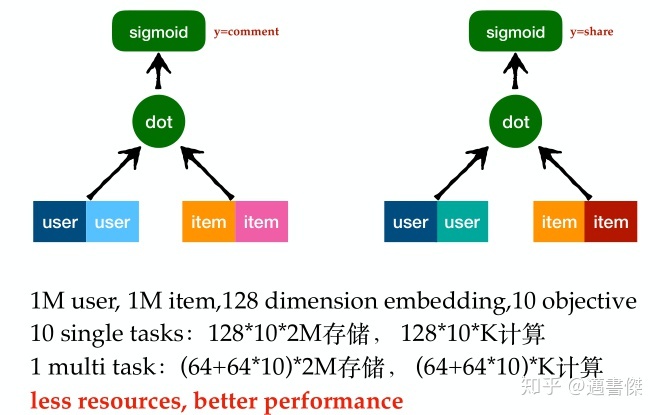
CVR in Alibaba:
CVR problem( post-click CVR 是指点击后转化率)
CVR 应⽤场景(• CPM 最⼤化:OCPC ⼴告系统使⽤ pCVR 来调整每次点击出价;• GMV 最⼤化:推荐系统排序中 pCVR 是关键因⼦)
⽤ CTR 的⽅法做 CVR 模型(• 采⽤类似点击率(CTR)预估任务的技术,通过点击的样本⼦集进⾏训练,推理的时候对整个展现样本空间进⾏推断)
CVR预估的难点:
样本选择偏差 (Sample Selection Bias, SSB) 问题:后⼀阶段的模型基于上⼀阶段的采样后的样本⼦集进⾏训练,但是最终是在全样本空间进⾏推理,这带来了严重的模型的泛化性问题
数据稀疏性 (Data Sparsity, DS) 问题 :通常后⼀阶段模型的训练样本规模通常远低于前⼀阶段任务,加⼤了模型训练的难度,同样带来了泛化性问题。

学术界解决⽅案:
✓缓解 DS 问题
• 分层CVR模型 :通过构建不同特征上层次建树,粗⼒度预估以解决 DS 问题。依赖于先验知识来构建分层结构,难以在具有数千万 user 和 item 的推荐系统中应⽤。
• 过采样⽅法: 通过复制稀少类的样本缓解 imbalance,这有助于缓解数据的稀疏性,对采样率很敏感。
✓缓解 SSB 问题
• All Missing As Negative :应⽤随机抽样策略来选择未点击的展现作为负样本。它可以在⼀定程度上通过引⼊缺失观察的样本来消除 SSB 问题,通常会导致预测低估。
ESMM:Entire Space Multi-Task Model:

ESMM解决⽅案:
✓SSB问题:
• 全空间建模: 和 在全部展现样本上建模。pCTCVR 和 pCTR,pCVR 都定义在全样本空间。通过分别估算单独训练的模型 pCTR和 pCTCVR 并通过上式可以获得 pCVR,三个关联和共同训练的分类器能够利⽤数据的序列模式并相互传递信息,保障物理意义
✓DS问题:
• 迁移学习:在 ESMM 中,CVR ⽹络的 Embedding 参数与 CTR 任务共享,遵循特征表⽰迁移学习范式。Embedding Layer 将⼤规模稀疏输⼊映射到低维稠密向量中,主导深度⽹络参数。CTR 任务所有展现样本规模⽐ CVR 任务要丰富多个量级,该参数共享机制使ESMM 中的 CVR ⽹络可以未点击展现中学习。
多⽬标排序实践:
• 构造评分矩阵;• 多⽬标召回;• learning to rank(• BPR• LambdaMart);• multi-task learning;• 如何更好的融合各个⽬标的得分
MTL在阿⾥的实践:ESMM















 3668
3668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









