





窗口函数在工作中经常用到,在面试中也会经常被问到,你知道它背后的实现原理吗?
这篇文章从一次业务中遇到的问题出发,深入聊了聊hsql中窗口函数的数据流转原理,在文章最后针对这个问题给出解决方案。

一、业务背景
先模拟一个业务背景,比如大家在看淘宝app时,如下图:
搜索一个关键词后,会给展示一系列商品,这些商品有不同的类型,比如第一个是广告商品,后面这几个算是正常的商品。把这些数据用下面的测试表来描述:
create 在该表中插入以下数据:
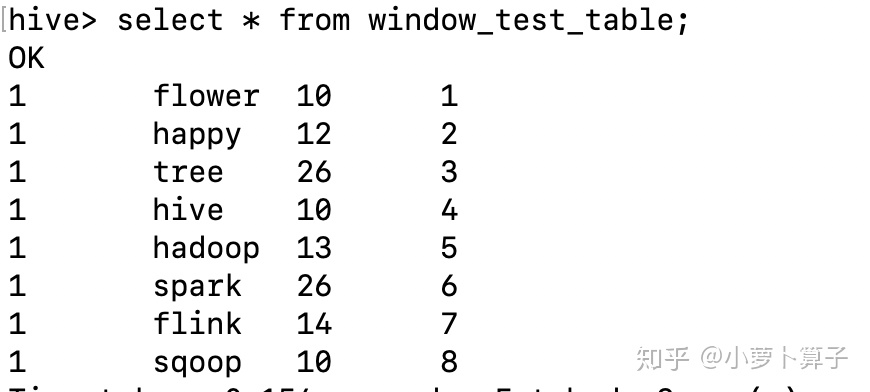
以上数据中,cell_type列,假设26代表是广告,现在有个需求,想获取每个用户每次搜索下非广告类型的商品位置自然排序,如果下效果:
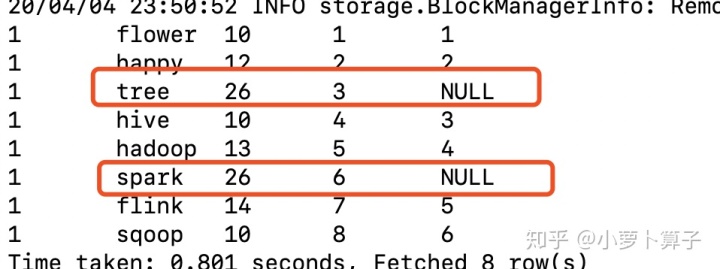
业务方的实现方法:
--业务方的写法
结果如下:

上面这种写法的结果显然不是我们想要的,虽然把26类型的rank去掉,但是非广告类的商品的位置排序没有向上补充
为什么呢?感觉写的也没错呀?~~~~
下面,我们来盘一盘window Funtion的实现原理
二、window 实现原理
在分析原理之前,先简单过一下window Funtion的使用范式:
select
上面的语句主要分两部分
- window函数部分(window_func)
- 窗口定义部分
2.1 window函数部分
windows函数部分就是所要在窗口上执行的函数,spark支持三中类型的窗口函数:
- 聚合函数 (aggregate functions)
- 排序函数(Ranking functions)
- 分析窗口函数(Analytic functions)
第一种都比较熟悉就是常用的count 、sum、avg等
第二种就是row_number、rank这样的排序函数
第三种专门为窗口而生的函数比如:cume_dist函数计算当前值在窗口中的百分位数
2.2 窗口定义部分
这部分就是over里面的内容了里面也有三部分
- partition by
- order by
- ROWS | RANGE BETWEEN
前两部分就是把数据分桶然后桶内排序,排好了序才能很好的定位出你需要向前或者向后取哪些数据来参与计算。这第三部分就是确定你需要哪些数据了。
spark提供了两种方式一种是ROWS BETWEEN也就是按照距离来取例如
- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW就是取从最开始到当前这一条数据,row_number()这个函数就是这样取的
- ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING代表取前面两条和后面两条数据参与计算,比如计算前后五天内的移动平均就可以这样算.
还有一种方式是RANGE BETWEEN 这种就是以当前值为锚点进行计算。比如RANGE BETWEEN 20 PRECEDING AND 10 FOLLOWING当前值为50的话就去前后的值在30到60之间的数据。
2.3 window Function 实现原理
窗口函数的实现,主要借助 Partitioned Table Function (即PTF);
PTF的输入可以是:表、子查询或另一个PTF函数输出;
PTF输出也是一张表。
写一个相对复杂的sql,来看一下执行窗口函数时,数据的流转情况:
select
数据流转如下图:
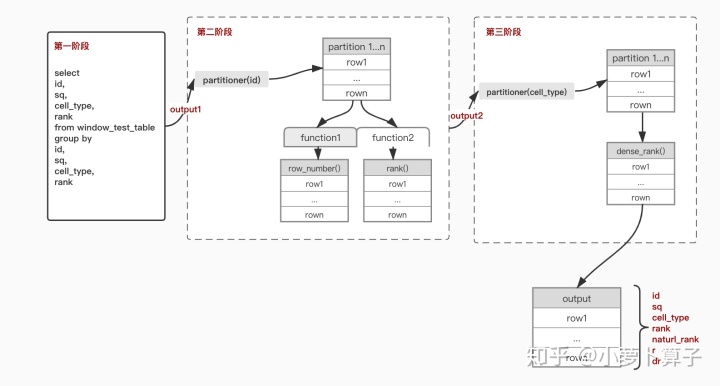
以上代码实现主要有三个阶段:
- 计算除窗口函数以外所有的其他运算,如:group by,join ,having等。上面的代码的第一阶段即为:
select
- 将第一步的输出作为第一个 PTF 的输入,计算对应的窗口函数值。上面代码的第二阶段即为:
select 由于row_number(),rank() 两个函数对应的窗口是相同的(partition by id order by rank),因此,这两个函数可以在一次shuffle中完成。
- 将第二步的输出作为 第二个PTF 的输入,计算对应的窗口函数值。上面代码的第三阶段即为:
select 由于dense_rank()的窗口与前两个函数不同,因此需要再partition一次,得到最终的输出结果。
以上可知,得到最终结果,需要shuffle三次,反应在 mapreduce上面,就是要经历三次map->reduce组合;反应在spark sql上,就是要Exchange三次,再加上中间排序操作,在数据量很大的情况下,效率基本没救~~
这些可能就是窗口函数运行效率慢的原因之一了。
这里给附上spark sql的执行计划,可以仔细品一下(hive sql的执行计划实在太长,但套路基本是一样的):
spark三、解决方案
回顾上面sql的写法:
select
从执行计划中,可以看到sql中 if 函数的执行位置如下:
spark数据流转:
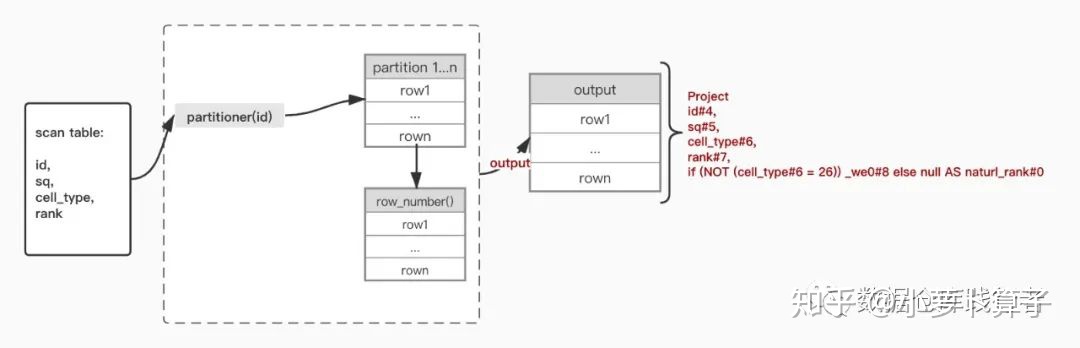
if函数在partition以及row_number后执行,因此得到的位置排名不正确。
改写一下:
select
这样写法要注意的地方:要保证 rand() 函数不会与id发生碰撞。
或者下面的写法也可以:
select
缺点就是要读两遍 window_test_table 表
http://weixin.qq.com/r/pi06IojEMtVNrcxB93i0 (二维码自动识别)
推荐阅读:
flink_sql_client 1.10 与 hive集成 读取实时数据mp.weixin.qq.com





















 4142
4142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









