







编辑推荐:
本文来自csdn,本文主要介绍了Pipeline(流水线)模式的问题解决思路,并通过示例代码介绍Pipeline模式的服务,希望本文对您的学习有所帮助。
模式名称
Pipeline(流水线)模式
模式解决的问题
有时一些线程的步奏比较冗长,而且由于每个阶段的结果与下阶段的执行有关系,又不能分开。
解决思路
可以将任务的处理分解为若干个处理阶段,上一个阶段任务的结果交给下一个阶段来处理,这样每个线程的处理是并行的,可以充分利用资源提高计算效率。
模式所使用的类:
Pipe对处理阶段的抽象,负责对输入进行处理,并将输出作为下一个阶段的输入:process()用于接收前一个处理阶段的处理结果,作为该处理阶段的输入,init()初始化当前处理阶段对外提供的服务,shutdown()关闭当前处理阶段对外提供的服务,setNextPipe()设置当前处理阶段的下一个处理阶段。
PipeContext对各个处理阶段的计算环境进行抽象,主要用于异常处理:handleError()用于对处理阶段泡醋的异常进行处理。
AbstractPipe类Pipe接口的抽象实现类:process()接收抢一个处理阶段的输入并调用其子类实现的doProcess方法对输入元素进行处理,init()保存对其参数中制定的PipeContext实例的引用,子类可根据需要覆盖该方法以实现其服务的初始化。
Shutdown默认实现什么也不做,子类可根据需要覆盖该方法实现服务停止:setNextPipe()设置当前处理阶段的下一个处理阶段,doProcess()留给子类实现的抽象方法,用于实现其服务的初始化。
WorkerThreadPipeDecprator基于工作线程的Pipe实现类,该Pipe实例会将接收到的输入元素存入队列,由制定个数的工作者线程对队列中输入元素进行处理,该类的自身主要负责工作者线程的生命周期的管理:process()接收前一个处理阶段的输入,并将其存入队列由工作者线程运行时取出进行处理,init()启动工作者线程并调用委托Pipe实例的init方法,shutdown()停止工作者线程并委托Pipe实例的shutdown方法,setNextPipe()调用委托Pipe实例的setNextPipe方法,dispatch()取队列中的输入元素并调用委托Pipe实例的process方法对其进行处理
ThreadPoolPopeDecorator基于线程池的Pipe的实现类:process()接收前一个处理阶段的输入,并向线程池提交一个对该输入进行相应处理的任务,init()调用委托pipe实例的init方法,shutdown()关闭当前Pipe实例对外提供的服务并调用委托Pipe实例的shutdown方法,setNextPipe()调用委托Pipe实例的setNextPipe方法。
AbstractParallelPile类AbstractPipe的子类,支持并行处理的Pipe实现类,该类对其每个输入元素(原始任务)生成相应的一组子任务,并以并行的方式去执行这些子任务,各个子任务的执行结果会被合并为相应原始任务的输出结果:bulidTasks()流给子类实现的抽象方法,用于根据制定的输入构造一组子任务,combineResults()留给子类实现的抽象方法,对各个并行子任务的处理结果进行合并,形成相应输入元素的输出结果。invokeParallel()实现以并行的方式执行一组任务,doProcess()实现该类对其输入的处理逻辑。
ConcreteParallelPipe类由应用定义的AbstractParallelPipe的子类:buildTasks()根据指定的输入构造一组子任务,combineResults()对各个并行子任务的处理结果进行合并,形成相应输入元素的输出结果
Pipeline类对符合Pipe的抽象:addPipe()往该Pipeline实例中添加一个Pipe实例。
SimplePipeline类基于AbstractPipe的Pipeline接口的一个简单实现类:addPipe()往该Pipeline实例中添加一个Pipe实例,addAsWorkerThreadBasedPipe()将制定的Pipe实例用WorkerThreadPipeDecorator实例包装后加入Pipeline实例,addAsThreadPoolBasedPipe()将制定的Pipe实例用ThreadPoolPipeDecorator实例包装后加入Pipeline实例。
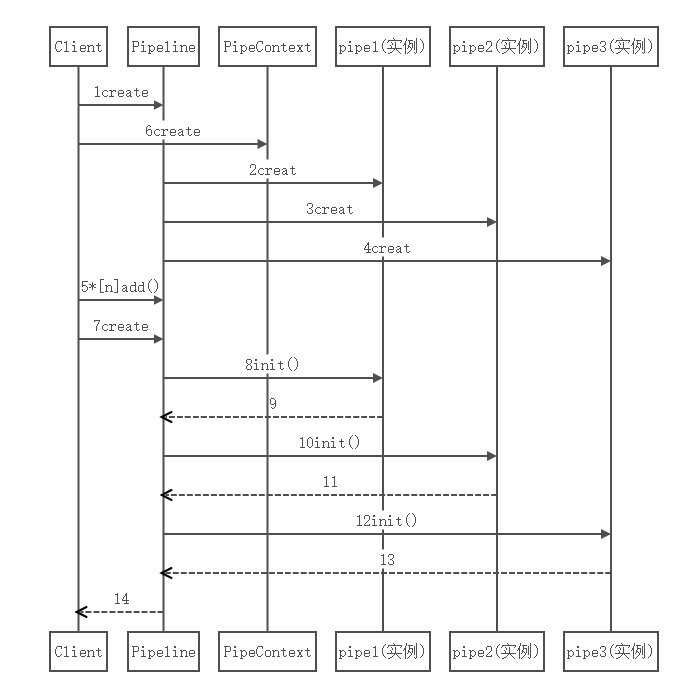
Pipeline模式的服务初始化序列图
示例代码
某系统需要一个数据同步的定时任务,该定时任务将数据库中符合制定条件的记录数据以文件的形式FTP传输(同步)到制定的主机上。该定时任务需要满足以下要求:
1.每个数据文件最多只包含N(如10000,具体可配置)条记录;当一个数据文件被写满时,其他代谢记录会被写入新的数据文件。
2.每个数据文件可能需要被传输到多台主机上。
3.本地要保留同步过的数据文件的备份。
因此,该定时任务需要做三件事情,都是比较耗时的操作,而且后面的操作还需要依赖前面操作的结果才能进行,不易拆分,如果只是用多线程,每个线程中仍然是按顺序串行处理也是不合适的,这样的话第二个步奏会出现多线程之间争夺资源导致时间浪费的问题,会更难完成任务,所以需要有Pipeline模式去执行。
数据同步定时任务
public class
DataSynctask implements Runnable{
public void run(){
ResultSet rs = null;
SimplePipeline
pipeline = buildPipeline();
pipeline.init(pipeline.newDefaultPipeContext());
Connection dbConn = null;
try{
dbConn = getConnection();
rs = qryRecords(dbConn);
processRecords(rs.pipeline);
}catch(Exception e){
e.printStackTrace();
}finally{
if(null != dbConn){
try{
dbConn.close();
}catch (SQLException e){
;
}
}
pipeline.shutdown(360,TimeUnit.SECONDS);
}
private ResultSet qryRecords(Connection dbConn)
throws Exception{
dbConn.setReadOnly(true);
PreparedStatement ps = dbConn
.prepareStatement("select id,productId,packageId,msisdn,operationTime,
operationTyoe," +
"effectiveDate,dueDate from subscriptions
order by operationTime",
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ
_ONLY);
ResultSet rs = ps.executeQuery();
return rs;
}
private static Connection getConnection() throws
Exception{
Connection dbConn = null;
Class.forName("org.hsqldb.jdbc.JDBCDriver");
dbConn = DriverManager.getConnectio
("jdbc:hsqldb:hsql://192.168.1.105:9001","SA","");
return dbConn;
}
private static Record makeRecordFrom(ResultSet
rs)
throws SQLException{
Record record = new Record();
record.setId(rs.getInt("id"));
record.setProductId(rs.getString("productId"));
record.setPackageId(rs.getString("msisdn"));
record.setOperationTime(rs.getTimestamp
("operationTime"));
rec
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1244
1244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









