







针对二元分类结果,常用的评估指标有如下三个:查准率(Precision)、查全率(Recall)以及F-score。这篇文章将讨论这些指标的含义、设计初衷以及局限性。
一、二元分类问题
在机器学习领域,我们常常会碰到二元分类问题。这是因为在现实中,我们常常面对一些二元选择,比如在休息时,决定是否一把吃鸡游戏。不仅如此,很多事情的结果也是二元的,比如向妹子表白时,是否被发好人卡。
当然,在实际中还存在一些结果是多元的情况,比如红、黄、蓝三种颜色中,喜欢哪一个,而这些多元情况对应着机器学习里的多元分类问题。对于多元分类问题,在实际的处理过程中常将它们转换为多个二元分类问题解决,比如图1所示的例子。
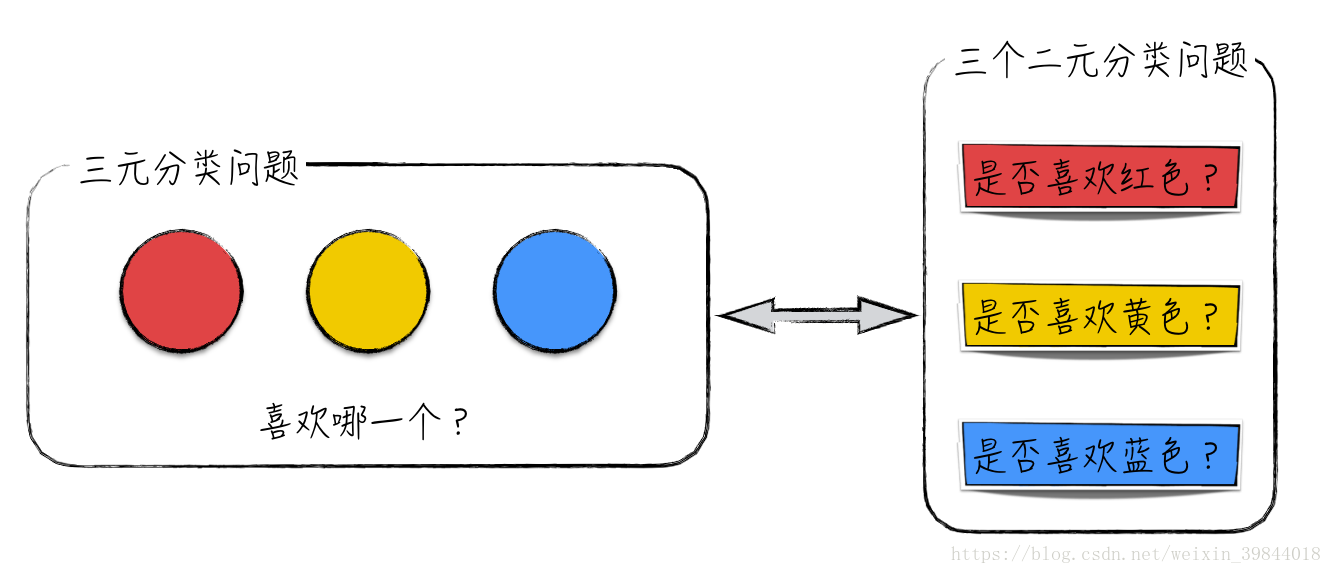 图1
图1
那么自然地,一个多元分类结果可以分解为多个二元分类结果来进行评估。这就是为什么我们只讨论二元分类结果的评估。为了更加严谨的表述,我们使用变量 y i y_i yi来表示真实的结果, y ^ i \hat{y}_i y^i表示预测的结果。其中 y i = 1 y_i = 1 yi=1表示正面的结果(在实际应用中更加关心的类别),比如妹子接受表白,而 y i = 0 y_i = 0 yi=0表示负面的结果,比如妹子拒绝表白。
二、查准率与查全率
在讨论查准查全的数学公式之前,我们先来探讨:针对二元分类问题,应该如何正确评估一份预测结果的效果。
沿用上面的数学记号。如图2所示,图中标记为1的方块表示 y ^ i = 0 \hat{y}_i = 0 y^i=0,但 y i = 1 y_i = 1 yi=1的数据;标记为3的凹型方块表示 y ^ i = 1 \hat{y}_i = 1 y^i=1,但 y i = 0 y_i = 0 yi=0的数据;标记为2的方块表示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3040
3040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









