





岭回归(Ridge Regression)是一种正则化方法,而所谓的正则化,就是对模型的参数加一个先验证假设,控制模型空间,以达到使得模型复杂度较小的目的,通过引入正则化方法能够减小均方差的大小。
岭回归通过来损失函数中引入L2范数惩罚项,来控制线性模型的复杂度,从而使得模型更稳健。Ridge实现了岭回归模型,其原型为:
class sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,normalize=False,copy_x=True, max_iter=None,tol=0.001,solver='auto',random_state=None)
参数说明:
alpha:a值,其值越大说明正则化项的占比越大。
fit_intercept:一个布尔值,制定是否需要计算b值,如果为False,那么就不用计算b值(模型会假设你的数据已经中性化了,这里的b值是线性函数y=w1*x1+w2*x2+...+Wn*Xn +b中的b值)
max_iter:指定最大的迭代次数,值为整数。如果为None,则表示使用默认值(不同的solver其默认值不同)。
copy_x:是否复制x的布尔值,为True表示要复制。
solver:指定求解最优化问题的算法,可以为:
auto:根据数据集自动选择算法;
avd:使用奇异值分解来计算回归系数;
cholesky:使用scipy.sparsesolve函数来求解;sparse_cg:使用scipy.sparse.cg函数来求解;
lsqr:使用 scipy.sparse.lsqr函数求解最优化问题,其运算速度最快,但可能老版本的scipy不支持。
sag:使用Stochastic Average Gradient descent算法,求解最优化问题。
tol:一个浮点数,指定判断迭代收敛与否的阈值。
random_state:一个整数或者RandomState实例,也可能是None,他在solver=sag时使用(如果random_state为整数,则他指定了随机数生成的种子。如果为RandomState实例,则指定了随机数生成器。如为None,则使用默认的随机数生成器)
属性说明:
coef_:权重向量。
intercept_:b值
n_iter_:实际迭代次数。
方法说明:
fit(x, y[,sample_weight):训练模型。
predict(x):用模型进行预测。
score(x, y[,sample_weight]):返回测试性能得分(测试分数不超过1,但是可能为负数(当预测效果太差的时候),score值越接近1,说明预测效果越好)
Ridge函数使用示例:
from sklearn.model_selection import train_test_split
import sklearn.linear_model
def load_data():
#使用鸢尾花数据集
diabetes = sklearn.datasets.load_iris()
return cross_validation.train_test_split(diabetes.data, diabetes.target, test_size=0.3,
random_state=0)
def test_Ridge(*data):
#参数:data依次指定了训练、测试样本集,训练样本集对应的标签值,测试样本对应的标签值,然后函数
#对其进行简单的预测,学习。
x_train, x_test, y_train, y_test = data
regr = sklearn.linear_model.Ridge()
regr.fit(x_train, y_train)
print("Coefficients:%s, intercept: %.2f"%(regr.coef_, regr.intercept_))
print("Residual sum of squares: %.2f"%np.mean((regr.predict(x_test)-y_test)**2))
print("score: %.2f" %regr.score(x_test, y_test))
x_train, x_test, y_train, y_test = load_data()
test_Ridge(x_train, x_test, y_train, y_test)
运行后其结果如下:
Coefficients:[-0.1627909 -0.01659315 0.31127324 0.47346343], intercept: 0.29
Residual sum of squares: 0.06
score: 0.90
可以看出,在使用默认值a的情况下,Ridge和LinearRegression的预测精度是一样的。下面我们来看一下不同的a值对预测性能的影响。
对应Ridge函数如下(其他代码保持上述内容不变):
def test_Ridge_alphavalue(*data):
x_train, x_test, y_train, y_test = data
alphas=[0.01,0.03,0.05,0.07,0.09,0.11,0.13,0.15,0.17,0.19,0.5,0.7,0.9,1,2,5,8,50,300,500,1000,2000,10000]
scores=[]
for i, alpha in enumerate(alphas):
regr = sklearn.linear_model.Ridge(alpha=alpha)
regr.fit(x_train, y_train)
scores.append(regr.score(x_test, y_test))
print("Different Coefficients:%s, intercept: %.2f"%(regr.coef_, regr.intercept_))
print("Different Residual sum of squares: %.2f"%np.mean((regr.predict(x_test)-y_test)**2))
print("Different score: %.2f" %regr.score(x_test, y_test))
#我们将最终的结果绘制成图
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(alphas, scores)
ax.set_xlabel("$alphas value")
ax.set_ylabel("$scores value")
ax.set_xscale('log')
ax.set_title("Ridge result of different alpha value" )
plt.show()
x_train, x_test, y_train, y_test = load_data()
test_Ridge_alphavalue(x_train, x_test, y_train, y_test)
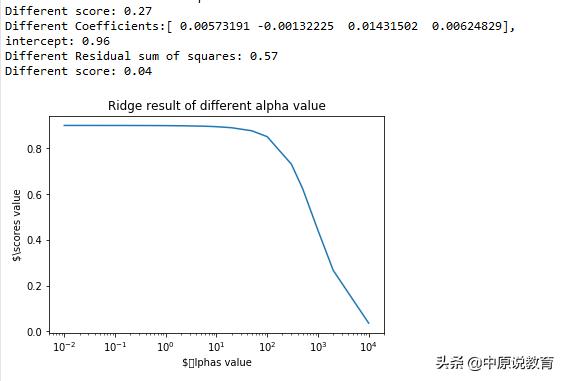
不同的alpha值对应的Ridge函数对鸢尾花数据的预测精度示意图
可以看到,当a超过1以后,随着a的增长,预测性能下降,当a很大是,正则化的影响较大,模型变得更为简单,但是预测性能也更加的小,预测性能变差,当a趋向于无穷大时,预测精度也趋向于0.















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









