







本系列所有的代码和数据都可以从陈强老师的个人主页上下载:Python数据程序
参考书目:陈强.机器学习及Python应用. 北京:高等教育出版社, 2021.
本系列基本不讲数学原理,只从代码角度去让读者们利用最简洁的Python代码实现机器学习方法。
线性回归Python案例:
数据集介绍
首先导入以下包,下载回归问题最常用的波士顿房价数据集。
import pandas as pd
from sklearn.datasets import load_boston
import statsmodels.formula.api as smf
dataset = load_boston()
type(dataset)
Boston = pd.DataFrame(dataset.data, columns=dataset.feature_names)
Boston['MEDV'] = dataset.target
Boston.info()
Boston.head()利用pd.DataFrame()变为数据框,Boston['MEDV'] 将响应变量y名称变为medv,利用Boston.info()查看数据信息。Boston.head()查看数据前五行。
数据长这个样子(前五行)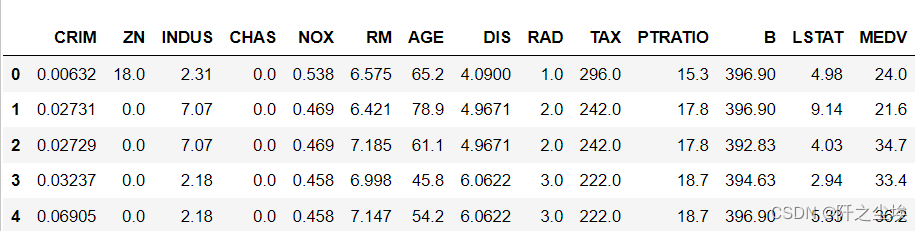
其中MEDV是响应变量y,就是房价的中位数,其他都是特征变量x,表示的是房子的一些信息,比如房间数RM,房产税TAX等
statsmodelsi进行线性回归
这是利用sklearn库自带的数据集,如果要读取本地数据集采用pd.read_excel('文件路径.xlsx')也可以读入转化为上面这样。下面利用statsmodels.formula.api进行线性回归
model = smf.ols('MEDV ~ RM', data=Boston)
results = model.fit()
results.summary() # Use print(results.summary()) to remove triple quotes
Python里面的statsmodels是模仿R语言的形式,只需要将你想放入回归方程里面的变量名称写上就行。这个是MEDV 与RM进行回归。得到结果如下:
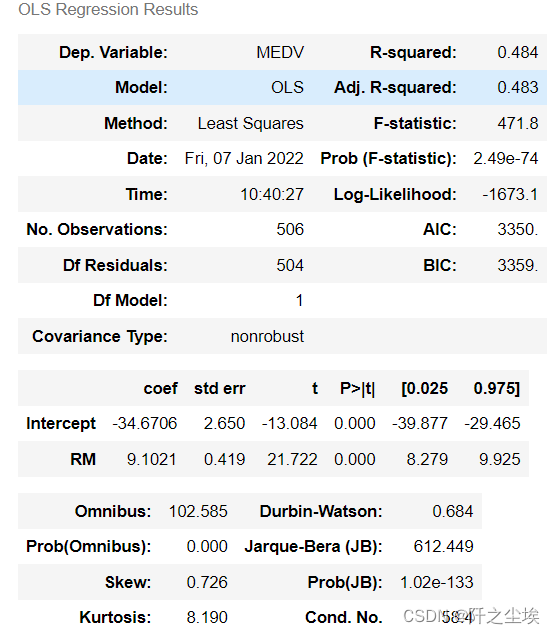
输出和Eviews软件的结果很像,其实也可以改成表格形式输出,类似stata,例如:
results = smf.ols('MEDV ~ RM + AGE', data=Boston).fit()
print(results.summary().tables[1])将MEDV ~与这两个RM + AGE回归,结果如下:

这样只报告了单个变量的系数,没有F值,R方等 。
如果想把所有变量都直接回归,也不想一个一个的去打变量名字,可以采用join连接方式,直接生成回归的公式:
all_columns = "+".join(dataset.feature_names)
print(all_columns)
formula = 'MEDV~' + all_columns
print(formula)
results = smf.ols(formula, data=Boston).fit()
print(results.summary().tables[1])
得到结果如下:

基于statsmodel接口的线性回归介绍到这。下面介绍基于sklearn库的线性回归。
sklearn库的线性回归
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
X_train, X_test, y_train, y_test = train_test_split(dataset.data, dataset.target, test_size=0.3, random_state=0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape导入sklearn库的一些包,然后划分测试集和训练集,并且查看他们形状。
model = LinearRegression()
model.fit(X_train, y_train)
model.coef_
进行线性回归模型拟合,并查看系数。注意sklearn库的线性回归是给不出每个系数的P值,t值,F值,因为机器学习不做参数估计和假设检验,只关心模型估计的y和真实的y相似程度。
,
model.score(X_test, y_test)计算测试集上的评分(拟合优度)
![]()
pred = model.predict(X_test)
mean_squared_error(y_test, pred)
r2_score(y_test, pred)进行预测,得到预测数据,然后和真实数据计算MSE和R方进行评价。R方应该和上面的评分是一样的。
使用交叉验证评价模型泛化能力
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import RepeatedKFold
X, y = load_boston(return_X_y = True)
model = LinearRegression()
kfold = KFold(n_splits=10,shuffle=True, random_state=1)
scores = cross_val_score(model, X, y, cv=kfold)
print(scores)
print(scores.mean())
print(scores.std())因为测试集和训练集是随机划分的,模型的结果会因为训练数据不一样而不一样。这里采用十折交叉验证得到十个评分,然后再取评分的均值。

还可以采用多次的重复K折交叉验证:
rkfold = RepeatedKFold(n_splits=10, n_repeats=10, random_state=1)
scores_mse = -cross_val_score(model, X, y, cv=rkfold, scoring='neg_mean_squared_error')
#print(scores_mse)
print(scores_mse.shape)
scores_mse.mean()
10折交叉验证重复了10次,会得到100个评分,可以画出这组评分的直方图
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.distplot(pd.DataFrame(scores_mse))
plt.xlabel('MSE')
plt.title('10-fold CV Repeated 10 Times') 结果如下:
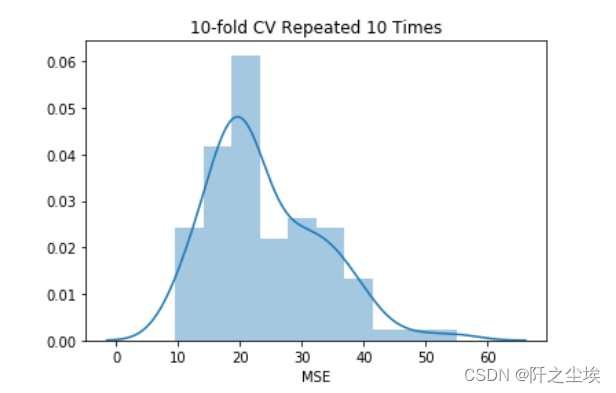
留一交叉验证,就是每次只采用一个样本进行评估,适合用于小数据集。
loo = LeaveOneOut()
scores_mse = -cross_val_score(model, X, y, cv=loo, scoring='neg_mean_squared_error')
scores_mse.mean()
















 9763
9763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











