






社区发现
这篇文章汇总了一些常见的社区发现概念和算法,包括
- Modularity Q
- Fast Unfolding(Louvain Algorithm)
- LPA
- SLPA
- KL算法
- GN算法
社区: a group of nodes that are well-connected to each other
常用的社区发现方法和计算复杂度:
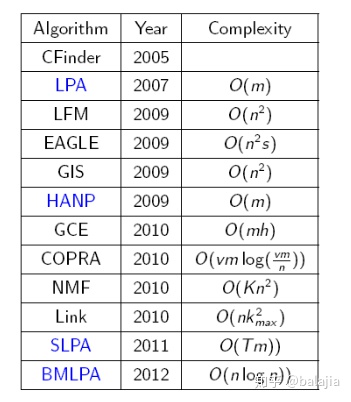
1. Modularity Q (衡量指标)
Modularity Q 是用来衡量发现的社区的好坏的指标:
理解上是,实际在group s中的边的数量减去随机的图中,可能在group s中的边的数量。其中 |expected edges within group s| 的计算需要一个null model。
Null Model G'
- 和原图有相同的度的分布, 但边使用随机连接
- 可以是multigraph
- 拥有度
和
的节点i和节点j中间的边的个数满足::
Q的计算
m: G中边的个数
- m:总边数,2m:总度数
- A:边权矩阵,
表示i和j的边权,
表示i的度数,
表示i所属的社区
-
在i和j属于相同社区时为1,否则为0。
可以转化为:
- m: 图中的总边数
-
: 社区为c的点之间的总度数 (1-2, 1-3, 2-3)内连接度数为6
-
: 社区为c的点的总度数之和
Q的数值
Q 大于0.3-0.7表示有意义的社区结构。Q的取值范围为[-1, 1],我们可以以最大化Q为社区发现任务的目标。
2. Fast Unfolding (Louvain Algorithm)
- O(nlogn)
- 支持weighted graphs
- hierarchical partitions 分层分区
- 适合大图:fast, rapid convergence properties, high modularity output
步骤
- 通过局部的更改节点社区分类来优化Modularity:先将每个节点指定到唯一的一个社区,然后按顺序将节点在这些社区间进行移动。以节点 i 为例,它有三个邻居节点 j1, j2, j3,我们分别尝试将节点 i 移动到 j1, j2, j3 所在的社区,并计算相应的 modularity 变化值,哪个变化值最大就将节点 i 移动到相应的社区中去,如果最大的变化值也为负,则不移动。
- 按照这个方法反复迭代,直到网络中任何节点的移动都不能再改善总的modularity值为止。
- 1,2两个步骤看做第一阶段。把第一阶段得到的社区视为一个新的节点。重新构造子图,两个节点之间边的权值为相应两个社区之间各边的权值的总和。
- 重复1,2,3步骤的操作,直到Modularity不再增加为止。
在这个过程中,把计算Modularity Q的变化的计算方法如下。
比如一孤立的节点i移到社区C中时:
-
-
-
: sum of the weights of the links inside C
-
, sum of the weights of the links from i to nodes in C
-
:sum of the weights of the links incident to nodes in C
-
: sum of the weights of the links incident to node i
-
: sum of the weights of all the links in the network
-
-
实际上,我们在计算时需要把节点i从社区D中移除,所以,还需要计算从社区D中移除节点i得到的Q的增量。一次移动给Q带来的变化为:
3. LPA 标签传播
Label Propagation Algorithm
算法:
- 为所有节点指定一个唯一的标签;
- 逐轮刷新所有节点的标签,直到达到收敛要求为止。
对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
问题:
- 随机性太大,更新顺序和初次迭代的时候选择的标签很大程度影响了结果
4. SLPA
Speaker-listener Label Propagation Algorithm
一个节点可以属于多个社区,比LPA鲁棒。
算法:
- LPA的加强版,记录更新序列
- 当迭代停止时,对每一个节点历史标签序列中各把标签出现的频率做统计,按照某一个给定的阈值过滤掉出现概率小的标签。
- 根据阈值,得到重叠性社区标签
5. K-L算法
将已知网络划分为已知大小的两个社区的二分方法,它是一种贪婪算法。它的主要思想是为网络划分定义了一个函数增益Q,Q表示的是社区内部的边数与社区之间的边数之差,根据这个方法找出使增益函数Q的值成为最大值的划分社区的方法。具体策略是,将社区结构中的结点移动到其他的社区结构中或者交换不同社区结构中的结点。从初始解开始搜索,直到从当前的解出发找不到更优的候选解,然后停止。
K-L算法的缺陷是必须先指定了两个子图的大小,不然不会得到正确的结果,实际应用意义不大。
6. GN算法
介数:betweenness
- 节点介数定义为网络中所有最短路径中经过该节点的路径的数目占最短路径总数的比例,
- 边介数定义为网络中所有最短路径中经过该边的路径的数目占最短路径总数的比例。
GN算法的步骤如下:
- 计算每一条边的边介数;
- 删除边界数最大的边;
- 重新计算网络中剩下的边的边阶数;
- 重复(3)和(4)步骤,直到网络中的任一顶点作为一个社区为止。
GN算法的缺陷:
- 不知道最后会有多少个社区;
- 在计算边介数的时候可能会有很对重复计算最短路径的情况,时间复杂度太高;GN算法不能判断算法终止位置。
参考资料
cs224Wweb.stanford.edu 社区发现(Community Detection)算法blog.csdn.net















 6201
6201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









