






在机器人的动作学习,传统的方法基于任务训练强化学习(reinforcement learning)的策略,即针对每一个成功完成的任务的动作序列,训练得到一条策略。或者在该基础上,当奖励讯号稀疏出现时,利用各种技术完成各项模仿学习 (imitation learning)。但模仿学习的问题是,它的各种任务是独立的。例如,通过训练一个模仿学习算法(神经网络)能够得到一个关于如何将块堆叠到高度为 3 的塔中的策略。但当希望机器人完成将块堆叠到高度为 2 的塔中的动作时,则需要重新训练神经网络,从而得到另外一个策略。
单样本模仿学习(One-Shot Imitation Learning)最先是伯克利大学著名的 Pieter Abbeel 教授以及他的学生在 2017 年提出来的 [1]。是指通过一次演示(可能包含一个或多个任务),告诉机器人当前有哪些任务以及如何完成这项任务。此时,不再是基于特定任务的神经网络学习,而是一种「演示模仿」学习。从有监督学习的角度讨论,给定包含几个训练任务的演示,单样本模仿学习能够根据当前样本推广到未知但相关联的任务中,从而做到一眼就能模仿。至于如何制定「相关联」,就是各位研究者所要探讨的内容。
单样本模仿学习的经典方法是元学习(Meta-Learning)。在训练阶段,通过给定已知域中的一组任务及对应的动作完成模型学习;测试阶段,利用模型通过一段演示推广并具备完成未知任务的能力。基于元学习的单样本模仿学习方法存在的主要问题是需要大量的数据(演示视频)完成模型训练。最近,李飞飞组提出将单样本模仿学习定义为一个符号规划问题(Symbolic Planning),利用符号域定义的结构将策略执行与任务间的泛化处理分离开来,从而大大减少元学习方法在训练阶段所需的任务数量,提高了方法的效率。
元学习和符号规划问题的方法思路都是以第一人的角度观看并学习演示(视频),因此演示的情况直接影响方法的效果。Leo Pauly 等提出了观察学习(Observation Learning)的概念,即从第三人的角度观看演示,同时利用深度网络将演示视频片段转化为活动的抽象表示(活动特征)。基于活动特征的不可变性,该方法可以在不同的观察视角、对象属性、场景背景和机械手形态下,跟随演示中学习任务。
本文主要介绍了 3 篇有关 one-shot imitation learning 的代表作,分别针对元学习、符号规划问题和观察学习的单样本模仿学习进行分析:Yu, Tianhe, et al. "One-shot hierarchical imitation learning of compound visuomotor tasks." arXiv preprint arXiv:1810.11043(2018). https://arxiv.org/pdf/1810.11043.pdf,基于元学习的单样本模仿学习。
De-An Huang, et al.「Continuous Relaxation of Symbolic Planner for One-Shot Imitation Learning.」arXiv preprint arXiv:1908.06769 (https://arxiv.org/abs/1908.06769) (2019). https://arxiv.org/pdf/1908.06769.pdf,利用符号规划问题的单样本模仿学习。
Leo Pauly, et al.「One-Shot Observation Learning Using Visual Activity Features .」arXiv:1810.07483(V2. 2019). https://arxiv.org/pdf/1810.07483.pdf,基于视觉活动特征的单样本观察学习。
One-shot hierarchical imitation learning of compound visuomotor tasks

本文是 Abbeel 和他的老搭档 Sergey Levine 教授利用他们学生 Finn 提出的 MAML 添了自己的坑。相比起 One-shot imitation learning 的开山之作的概念性模型 [1],这里实际中利用了视觉像素输入,解决了单样本模仿学习中处理多阶段复杂视觉任务的问题。即针对一条原始演示视频(没有经过任何预标记处理的执行整个任务的未剪辑原始视频),通过有效利用子任务的演示数据和其他对象信息等,完成模仿学习。本文使用元学习方法,同时为了解决原始视频中存在的未标记、多任务问题,本文提出的方法同时完成动作学习和动作合成两项任务。本文的主要贡献是提出了一种没有预标注的人类演示动态学习和组合策略序列的方法。由实验分析可知,这种方法可以用来动态地学习和排序用户在测试时提供的单个视频演示的技巧。
方法分析
文章首先解决教会机器人通过模仿人类演示来学习原始动作技能的问题。本文使用领域自适应元学习(Domain-adaptive meta learning,DAML)方法从单个演示推断策略。DAML 是模型不可知元学习算法(Model-agnostic meta-learning algorithm,MAML)的扩展。Finn 中首次提出了 MAML 的概念 [2],其目标是通过二重循环 1. 分别学习不同任务的深度网络的参数 ($\theta_1,\theta_2,\theta_3$),2. 找到不同任务间的共同次优解($\theta$),从而通过一步或几步梯度下降实现有效的泛化处理。图 1 中给出 MAML 原理示意图,找到这样的模型参数,对于任一任务产生的参数微小变化,能够使得损失函数具有很大的改进,因此通过优化表示$\theta$,能够快速完成新任务的适应性学习。
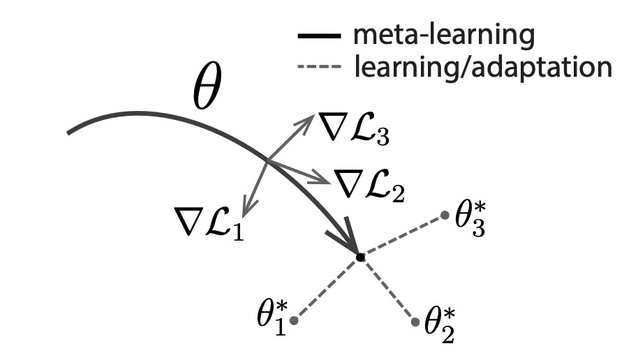
Fig. 1. Diagram of MAML, which optimizes for a representation θ that can quickly adapt to new tasks.














 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









