





在看文章前可以先看下这个,
吴海波:专栏的序。
先有个大概的认识会对阅读有所帮助。
在介绍后续章节内容之前,我们介绍下I/O设备这个概念以及OS如何和这些设备进行交互。I/O对于计算机系统来说是非常重要的,想象下,如果一个程序没有输入或者输出,那么会是什么样的场景(你永远不能操作什么也无法得到什么)?。。。。所以为了让计算机系统更有吸引力,就必须要同时存在输入和输出,所以我们遇到的问题是:
如何将I/O设备集成到计算机系统中?
通用的原理是什么?
我们怎么让这些设备高效的运行?
在开始讨论前,先看下下面这个“经典”的计算机系统的图示。
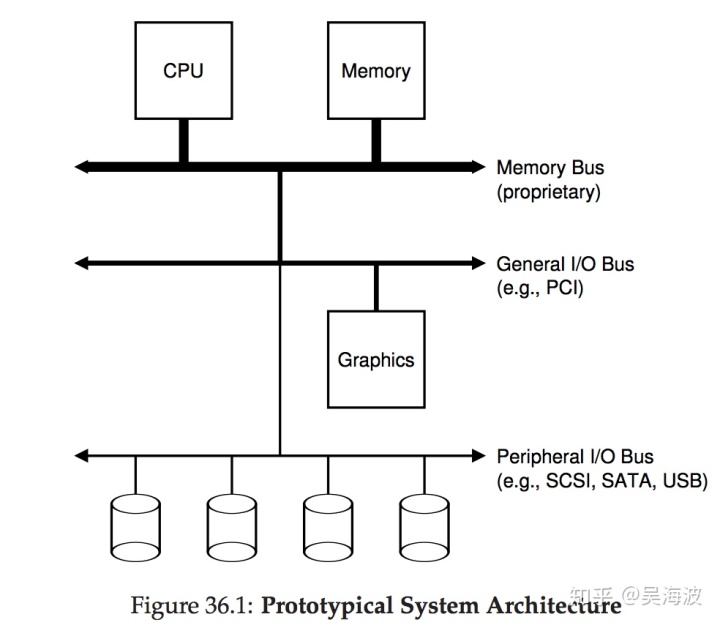
图中cpu和主存通过内存总线连接。一些设备通过I/O总线和系统进行连接,在大多数现代操作系统中是PCI(或是其它的衍生品);包括图像处理以及其他一些需要高传输速率的设备。其他的一些比较慢的设备,比如SCISI,SATA,USB是通过“外围总线“和系统连接的。通常硬盘,鼠标和键盘就是属于慢速的设备。
你可能会想:为什么我们需要一个像这样的层次结构? 简单地说:客观世界的限制和成本。 比如公交车越快,公交线路必须越短; 因此,高性能的内存总线没有空间插入很多的设备。 另外,高性能的公共汽车也会非常昂贵。 因此,系统设计师采用这种分层方法,让其中需要高性能的组件(如显卡)更靠近CPU,低性能的设备则相对较远。放置磁盘和其他慢速设备在外围总线上的好处是多方面的; 尤其是可以在其上放置大量设备(这里的想法其实和缓存的概念是相似的)。
当然,现代系统越来越多地使用专用芯片组和更快的点对点互连,以提高性能。 图36.2显示了英特尔Z270芯片组的大致设计图。在顶部,CPU紧密地连接到内存系统,而且还具有与显卡的高性能连接。
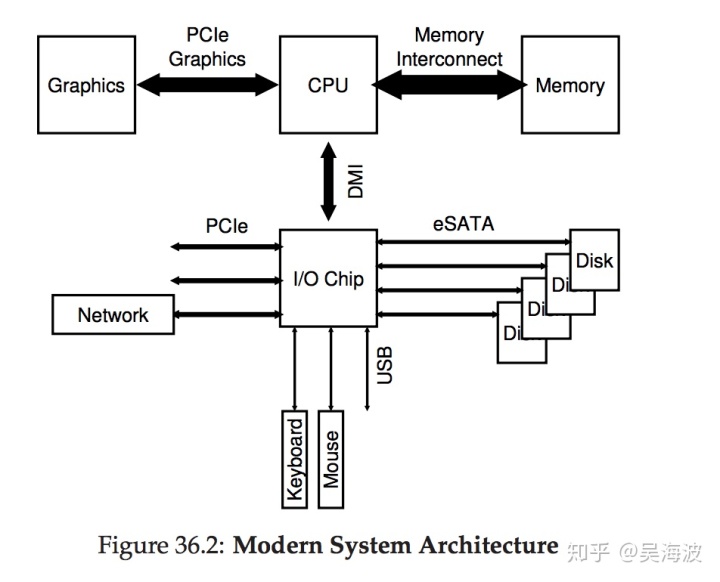
CPU通过英特尔专有的DMI(Direct Media Interface)连接I/O芯片,外围的设备通过不同种类的内部连接到I/O芯片。 在右侧,一个或多个硬盘驱动器通过eSATA接口连接到系统; ATA(AT Attachment,用来连接IBM PC AT类型机器的接口),然后是SATA(Serial ATA),现在eSATA(external SATA),这些接口的更新迭代代表着过去几十年的存储接口的进化,每一步都提高性能以跟上现代存储设备的步伐。I / O芯片下面是许多USB(通用串行总线)连接,可以连接键盘和鼠标到电脑。 在许多现代系统中,USB用于低速的设备。
最后,在左侧,可以通过PCIe(Peripheral Component Interconnect Express)连接其他更高性能的设备到系统。 在此图中,网络通过PCIe接口连接到系统; 更高性能存储设备(如NVMe持久存储设备)通常也在这里连接。
现在让我们看一个典型设备(不是真实设备),并使用该设备,来推动我们对于设备高速连接所需的一些原理的理解。从图36.3,我们可以看到设备有两个重要组件。首先是硬件层面呈现给外部的接口。就像软件一样,硬件必须提供允许系统软件进行操作的接口。因此,所有设备都有一些指定的典型交互接口和交互协议。

设备的第二部分是其内部结构。这一部分是每个设备自己的特定实现,这个部分负责实现设备呈现给系统的抽象。非常简单的设备将有一个或几个硬件芯片来实现他们的功能;更复杂的设备可能包括一个简单的CPU,一些通用的内存和其他完成特定功能的芯片。例如,现代RAID控制器可能包含数十万行固件(即硬件设备内的软件)以实现其功能。
在上图中,(简化)设备接口由三个寄存器组成:状态寄存器,可以读取以查看设备的当前状态; 命令寄存器,告诉设备执行某项任务; 和数据寄存器,用于将数据传递给设备,或从设备获取数据。
通过读写这些寄存器,操作系统可以控制设备行为。
下面是描述操作系统可能与设备进行的典型交互。 协议如下:
While (STATUS == BUSY)//当设备处于忙的状态的时候,cpu循环等待
; // wait until device is not busy
Write data to DATA register//将数据写入i/o设备的数据寄存器
Write command to COMMAND register//将命令写入设备的命令寄存器
(Doing so starts the device and executes the command)//设备开始执行该i/o请求
While (STATUS == BUSY)//等待设备的空闲
; // wait until device is done with your request该协议有四个步骤。
首先,OS等待,直到设备为准备接收命令的状态(通过循环不断重复读取状态寄存器来获取设备状态);我们称之为轮询设备(基本上,只是询问它发生了什么)。
然后,OS将一些数据发送到数据寄存器。当CPU参与数据移动时(如本示例协议中所述),我们将其称为编程I / O(programmed I/O,PIO)。
第三,OS将命令写入命令寄存器;这样做会隐式地让设备知道数据都存在并且它应该开始处理。
最后,操作系统等待设备完成,再次轮询它,等待最终执行的结果(然后它可能会得到一个代码来指示成功或失败)。
这个基本协议具有简单和有效的优点。但是,也存在一些低效率和不方便的地方。协议第一个问题是轮询效率低下;特别是,它等待(可能很慢的)设备完成其活动而浪费了大量的CPU时间,而不是切换到另一个就绪进程,从而更好地利用CPU。那么怎么解决这个问题呢?
通过中断机制可以解决轮询慢的问题。 操作系统可以发出请求,将调用进程置于休眠状态,并将上下文切换到另一个任务,而不是重复轮询设备。当设备最终完成操作时,它将引发硬件中断,导致CPU去执行预定的中断服务程序(ISR)或更简单的中断处理程序。处理程序只是一个操作系统代码,它将接受中断(例如,通过从设备读取数据和可能的错误代码)并唤醒等待I / O的进程。因此,中断允许cpu运行和I / O操作的重叠,这是提高利用率的关键。 此时间线显示如下:

在图中,进程1在CPU上运行一段时间(由CPU行上的重复1表示),然后向磁盘发出I / O请求以读取一些数据。 在没有中断的情况下,系统只需重复轮询设备的状态,直到I / O完成(由p表示)。磁盘完成请求后进程1可以再次运行。
如果我们使用中断,操作系统可以在等待磁盘时执行其他操作:

在上图中,操作系统在CPU上运行进程2,而磁盘服务进程1的请求。 磁盘请求完成后,会发生中断,操作系统唤醒进程1并再次运行它。因此,CPU和磁盘在中间段时间内都得到了合适的利用。
需要注意的是,使用中断并不总是最佳的解决方案。 例如,假设一个设备可以非常快速地执行其任务:轮询第一次的时候请求就完成了。在这种情况下使用中断实际上会降低系统速度:因为切换到另一个进程,处理中断,然后再切换回原来的进程的代价是很昂贵的。因此,如果设备速度很快,最好进行轮询; 如果它很慢,允许中断是最好的。如果设备的速度未知,或者有时速度快,有时速度慢,最好使用轮询和中断的混合,首先先轮询一段时间,如果设备尚未完成,则使用中断。
不使用中断的另一个场景是在网络服务器中。当大量传入数据包每个都产生一个中断时,操作系统可能会活锁,也就是说,os只处理中断,从不允许用户级进程运行并实际为请求提供服务。例如,想象一个经历负载突发的Web服务器,可能是因为它成为了Hacker News中排名第一的条目。在这种情况下,最好偶尔使用轮询来更好地控制系统中发生的事情,并允许Web服务器在返回检查是否有更多的数据包到达之前为某些请求提供服务。另一种基于中断的优化是合并。在这样的设置中,需要引发中断的设备在将中断传递给CPU之前首先等待一会。在等待期间,可能会再收到中断,最终可以将这些中断进行合并再统一传递,这样可以降低中断处理的开销。当然,等待太久会增加请求的延迟,这个时间可以试具体情况而定。
我们的规范协议还有另外一个方面需要我们注意。特别是,当使用PIO将大量数据传输到设备时,CPU再次承担了相当繁琐的任务负担,因此浪费了大量时钟周期,此时间表说明了问题:

在时间线中,进程1正在运行,然后希望将一些数据写入磁盘。接着它启动I / O,cpu必须将数据从内存复制到设备中,一次一个字(在图中标记为c)。复制完成后,磁盘开始工作,这个时候CPU才可用于其他操作。所以怎么样减少这种复制数据的损耗呢?
解决方案就是直接内存访问(Direct Memory Access,DMA)。DMA引擎本质上是系统中一个特定的设备,它可以在没有太多CPU干预的情况下协调设备和主存之间的传输。DMA的工作原理如下。 例如,要将数据传输到设备,操作系统对DMA引擎进行编程来告知数据存储在内存中的位置,要复制的数据量以及将数据发送到哪个设备。这样就相当于操作系统完成了传输,可以继续进行其他工作。然后DMA开始工作,DMA完成后,DMA控制器会产生中断,因此操作系统知道传输完成。修订后的时间表:
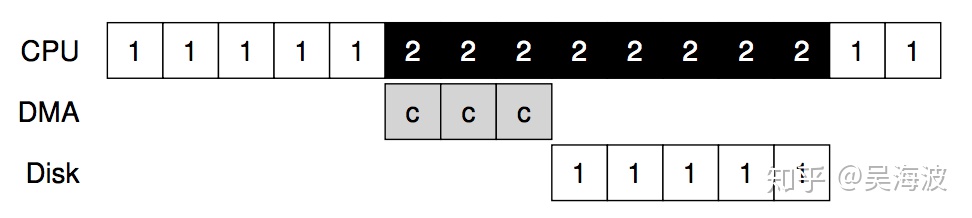
可以看到数据的复制现在由DMA控制器处理。 由于CPU在此期间是空闲的,因此操作系统可以执行其他操作,此处选择运行进程2。因此,在进程1再次运行之前,进程2可以使用更多的CPU。
现在我们已经了解了执行I / O所涉及的效率问题,我们需要处理一些其他问题才能将设备整合到现代系统中。到目前为止你可能已经注意到的一个问题:我们还没有真正说过操作系统如何与设备进行实际通信!因此,现在面临的问题是:
怎么和硬件设备进行通信? 应该是明确的指令吗? 或者还有其他方法吗?
在计算机发展的历程中,有两种主要的设备通信方法。第一个最古老的方法(多年来由IBM大型机使用)是有明确的I / O指令。这些指令指定OS将数据发送到特定设备寄存器的方式。例如,在x86上,in和out指令可用于与设备通信。要将数据发送到设备,调用者将数据放入指定寄存器,以及通过特定的端口来指定设备。然后执行指令就可以了。这些指示通常是特权指令。所以操作系统控制设备,是唯一允许与它们直接通信的实体。与设备交互的第二种方法称为内存映射I / O.通过这种方法,对硬件的寄存器的访问就像访问内存一样。为了访问特定寄存器,OS对指定区域的内存读取或写入,然后硬件将该数据读取/写入设备中。这2种方式没有孰优孰劣,内存映射方法不需要新指令来支持它(这是优势),但这两种方法至今仍在使用。
我们将讨论的最后一个问题是:如何将每个都具有非常特定接口的设备安装到操作系统中,我们希望这种安装方式能尽可能保持通用。例如,我们想构建一个在SCSI磁盘,IDE磁盘,usb等设备之上工作的文件系统,我们希望文件系统能够相对忽略掉一些具体的设备细节。这个问题是通过古老的抽象技术解决的。在最低级别,操作系统中的特定软件必须详细了解设备的工作原理。我们将这个软件称为设备驱动程序,设备驱动程序将与设备交互的任何细节都封装在其中。让我们通过Linux文件系统来看看抽象如何来帮助OS设计和实现。图36.4是Linux软件组织的粗略描述。
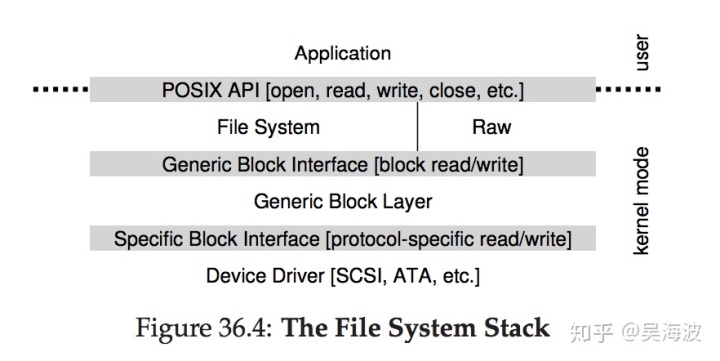
从图中可以看出,文件系统(当然还有上面的应用程序)完全忽略了它所使用的磁盘的细节;它只是向通用块层发出块读取和写入请求,通用通用层将它们路由到适当的设备驱动程序,驱动程序来实际处理请求。虽然简化了,但该图显示了大多数操作系统中隐藏的细节。该图还显示了设备的原始接口,可以使特殊的应用程序(例如文件系统检查程序,或磁盘碎片整理工具)能够直接读取和写入块,而无需使用文件抽象。大多数系统都提供此类接口来支持这些低层级存储管理应用程序。
需要注意的是上面看到的封装也有其缺点。例如,如果某个设备具有许多特殊功能,但又必须向内核的其余部分提供通用接口,那么这些特殊功能就不能使用了。例如,SCSI设备具有非常丰富的错误报告;因为其他块设备(例如,ATA / IDE)只有简单的错误报告,所以更高级别的软件接收的就是通用EIO(通用IO错误)错误代码;因此,SCSI可能提供的任何额外细节都会丢失。有趣的是,因为你插入系统的任何设备都需要设备驱动程序,随着时间的推移,它们代表了很大比例的内核代码。对Linux内核的研究表明,超过70%的OS代码存在于设备驱动程序中;对于基于Windows的系统,它可能更高。因此,当人们告诉你操作系统有数百万行代码时,他们真正说的是操作系统有数百万行设备驱动程序代码。也许更令人沮丧的是,由于驱动程序通常由“业余爱好者”(而不是全职内核开发人员)编写,它们往往会有更多的错误,因此是内核崩溃的主要原因。
为了深入学习,让我们快速浏览一下实际设备:IDE磁盘驱动器。

IDE磁盘提供了简单的系统接口,包括四种类型的寄存器:控制,命令块,状态和错误。使用(在x86上)in和out I / O指令,可以访问这些寄存器。假设已经初始化,与设备交互的基本协议如下。
1.等待驱动器做好准备。读取状态寄存器(0x1F7)直到驱动器状态不是busy而是ready。
2.将参数写入命令寄存器。扇区数,要访问的扇区的逻辑块地址(LBA)和驱动器号(master = 0x00或slave = 0x10,因为IDE只允许两个驱动器),命令寄存器对应的编号是(0x1F2-0x1F6)。
3.启动I / O。对命令寄存器0x1F7写入READ—WRITE 命令。
4.数据传输(用于写入):等待驱动器状态为READY和DRQ(数据驱动请求);将数据写入数据端口。
5.处理中断。在最简单的情况下,处理每个数据块传输的中断;更复杂的方法允许批处理,当整个传输完成时,才发出一次中断。
6.错误处理。每次操作后,读取状态寄存器。如果ERROR位有置位,读取错误寄存器以获取详细信息。

上面说到的协议的内容大多数都可以在xv6 IDE驱动程序中找到(图36.6),该驱动程序(初始化后)通过四个主要函数工作。第一个是ide_rw(),这个方法首先将I/O请求组成一个队列(如果有其他的等待处理的请求),或者直接通过ide_start_request()方法处理请求,在这2种情况下,调用的进程都会进入睡眠,等待请求的完成。对于ide_start_request()方法,它是用来处理硬盘收到的请求的。使用in和out指令分别去读取和写入设备寄存器。在这个方法中还会调用ide_wait_ready()方法来判断设备的状态是否是ready。最后,当中断产生的时候调用ide_intr() ,这个方法从设备中读取数据(如果产生中断的请求是读任务),唤醒等待I/O的进程,并且如果还有等待执行的请求,调用ide_start_request()方法执行下一个I/O请求。















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









