






本文首发于微信公众号【面向数据编程】
知乎里很多人都问过类似的问题,
在Hadoop 和Spark之间如何取舍?www.zhihu.com我也在相应问题下面给出了自己的回答,于是我写一篇文章做个总结。
Spark是一个提供大数据分布式并行计算的开源方案,提供了诸多高层次API的数据操作方法,可以用于处理不同数据结构大规模数据的处理、计算任务。
很多人拿它与Hadoop进行比较,实际上它并不像Hadoop一样提供数据存储的方案,仅仅是Hadoop中MapReduce组件的一种替代和改进。与MapReduce相比,它做了很多性能的优化,例如将计算过程放入内存,不需要反复读写硬盘。更重要的是,它比MapReduce的操作更简单,支持的任务种类更多。
计算机科学的发展是不断地将问题进行抽象,从而让人能够在更高的层次解决问题。Spark也是对分布式大数据处理的一种抽象,让工程师或者分析人员能够不必像写MapReduce一样,太关注底层的实现逻辑,从而在处理层次上投入更多精力。
Spark在大数据生态中的定位
Spark的工作需要配合存储层,例如Hadoop中的HDFS这种分布式文件存储或者MongoDB、Cassandra这类数据库,来完成。同时,它还需要一个集群的管理器,比如YARN、Mesos等用来管理相应的数据处理任务。当然Spark自己也提供集群管理功能,这样集群的每个节点都需要安装Spark,用于进行任务的编排。
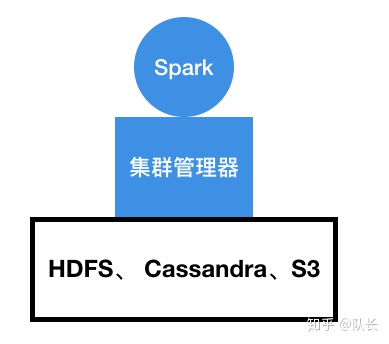
Spark发展至今也成为了一套完整的大数据处理生态,它包含了特别多的组件,可以用于不同的处理任务。例如Spark ML、Spark Streaming等等。Spark ML包含了很多内置的机器学习算法,用来处理基于大量数据的机器学习任务,Spark Streaming用于处理小批量的流式数据。这一切都基于它的核心概念,RDD,Resilient Distributed Datasets,即弹性分布式数据集。
RDD
正如上文所言,Spark对MapReduce做了一个抽象,从而让数据处理任务更加高效简洁。
这种抽象就是基于RDD完成的,对于数据应用的开发者来说,我们基于Spark进行开发就像是开发单机程序一样,只需要关注对RDD的操作,而不用关注数据具体是怎么存储,怎么调度,即可完成相应的数据处理任务。不过我们仍然还是得好好的了解一下RDD究竟是什么,它具备哪些特性。
之前的回答
请用通俗形象的语言解释下:Spark中的RDD到底是什么意思?www.zhihu.com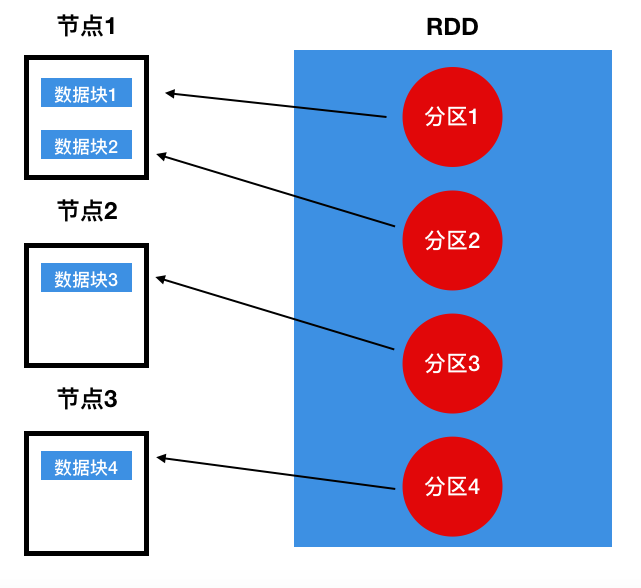
大致介绍过RDD,它具备三个特性:
- 不可变
- 可并行操作
- 分区
实际上并行操作和分区是一个意思,正因为不同的分区的数据处于不同节点,所以才能进行并行操作。整个RDD实际上是一个类似数组的结构,每一个分区即一个元素,在实际的物理存储中,每一个分区指向节点中存放在内存的数据块,
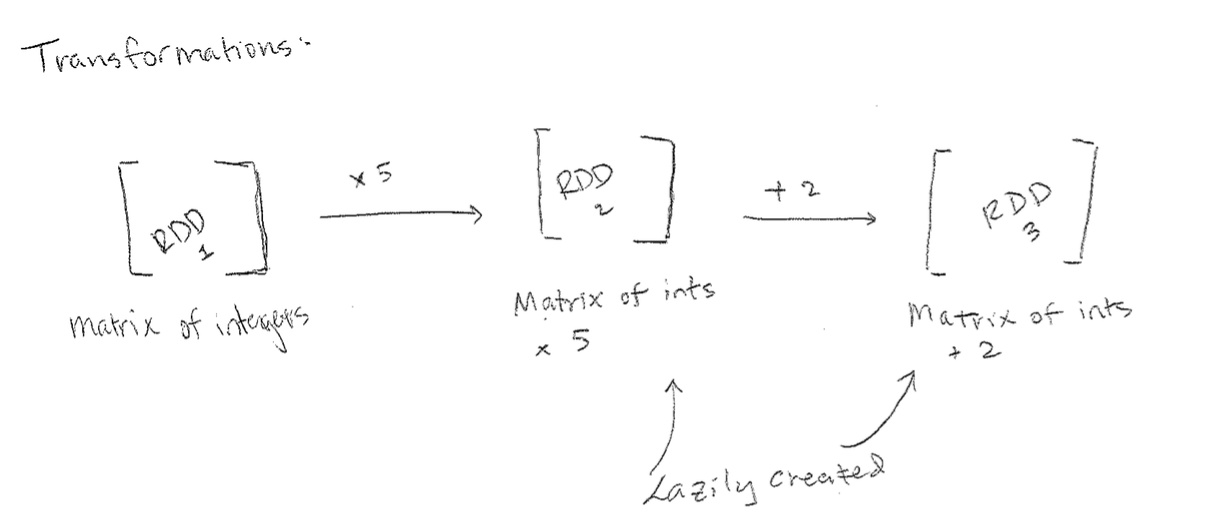
RDD本身是不可变的,即只读的。如果想要改变RDD里的数据,对于它的任何转换操作,会产生一个新的RDD作为结果,新的RDD会包含从其它RDD衍生而来的所有信息。比如最经典的Word Count程序:
val textFile = spark.sparkContext.textFile("README.md")
val words = textFile.flatMap(line => line.split(" "))
val word_pairs = words.map(word => (word, 1))
val word_counts = reduceByKey(_ + _)整个过程可以用下图表示,
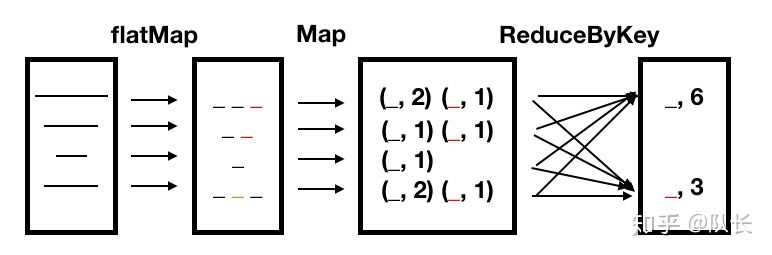
首先我们读入了一个文件,形成了第一个RDD,RDD中的每一个元素是文件中的每一行。然后我们使用flatMap操作对每一行进行分词,形成了第二个RDD,每一个元素是每一行分词后的结果。之后我们使用Map对每一行每一个单词进行计数,形成第三个RDD。最后我们使用ReduceByKey对每一个单词在每一行出现的次数进行加和,得到最终的词频统计结果。
每一步的结果跟上一步都存在依赖关系,然而Spark并不会将中间产生的结果写入硬盘,而是只记录这些RDD之间的依赖关系。如果说某一步出错了,我们只需要从这一步之前的RDD出发,再次进行计算,而不需要从头开始。这些特点造就了Spark的优势:
- 速度快,因为不需要将每一步的结果写入硬盘,所以节省了大量读写时间
- 容错程度高,保留依赖关系使得错误恢复更加容易,快速
懒加载
另外,我们需要知道,RDD的执行是以一种懒加载的方式进行的。这是什么意思呢?RDD实际上定义了两种操作,一种叫Transformation,一种叫Action。Transformation用于对RDD定义转换操作,Action则用来触发RDD的计算。
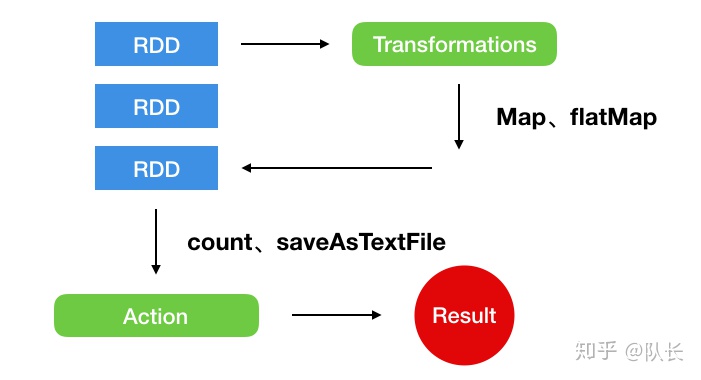
比如上图,我们对某一个RDD定义了一系列的变换过程,例如Map、flatMap等,这些操作不会被立刻执行,只有在需要的时候才会被执行。Spark维护的是整个数据的变换记录,当我们需要真正对数据进行实际的操作时,比如存储、计数等,才会触发整个过程。这也是Spark与MapReduce的区别之一,在Spark中,我们不创建单个执行图,而是将许多简单的操作结合在一起。这种方式无疑维护性更强,速度也更快,同时降低了整个操作的复杂度。
依赖关系
依赖关系使得用户能够很方便的使用有向无环图图的方式来定义数据的任务流,虽然说用户不需要关心依赖的具体实现方式,但是仍然有必要了解它的原理。我们从Word Count图示可以看出,各个RDD的分区之间实际上是存在一对一以及多对多的关系。Spark将这两种关系分别称之为窄依赖和宽依赖。
尽管依赖关系能够让程序在发生错误时候方便的进行回退,如果遇到依赖链比较长的RDD,恢复还是会比较耗时的。因此Spark引入了CheckPoint机制来处理长依赖的RDD。CheckPoint会将数据直接保存进存储层中,并切断此RDD之前的依赖关系,当需要回退时候,CheckPoint RDD后面的RDD就不需要知道前面的依赖关系了,可以直接从存储层直接读取相应的数据,开始进行接下来的RDD变换操作。
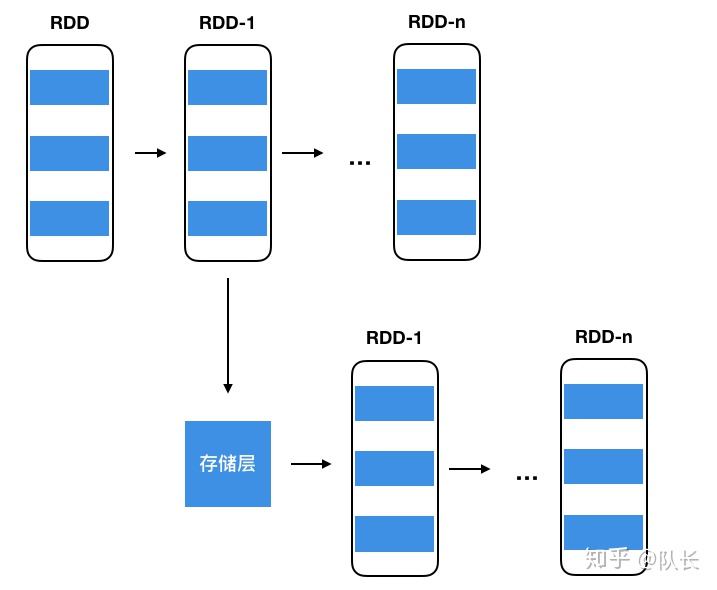
同样,对于某些经常使用的RDD也有相应的缓存机制,如果我们对RDD调用一个新的Action操作都要从头开始进行运算,会非常低效。因此Spark提供了相应的接口persist()与cache(),支持将RDD的数据缓存入内存或者存储层中。当下次进行同样的操作,可以直接读取相应的结果,提高了效率。
小结
本文主要介绍了RDD的基本设计思想与特性,
- 利用分布式内存,提高数据的读写速度。
- 使用依赖关系,将数据操作抽象为有向无环图,使得数据操作的中间结果不需要被反复读写,提高了计算速度。
- 通过一系列缓存措施,降低容错成本,使得计算流程更快,恢复成本更低。
- 通过RDD这一数据抽象,提供了简单的数据处理接口,让用户能够尽量减少对底层的关注,从而只需要专注于完成任务。















 4943
4943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









