







上一篇我们学习了BeautifulSoup的基本用法,本节我们使用它来爬取豆瓣图书Top250。
一、网页分析
我们爬取的网页的url是https://book.douban.com/top250?icn=index-book250-all。首页如图
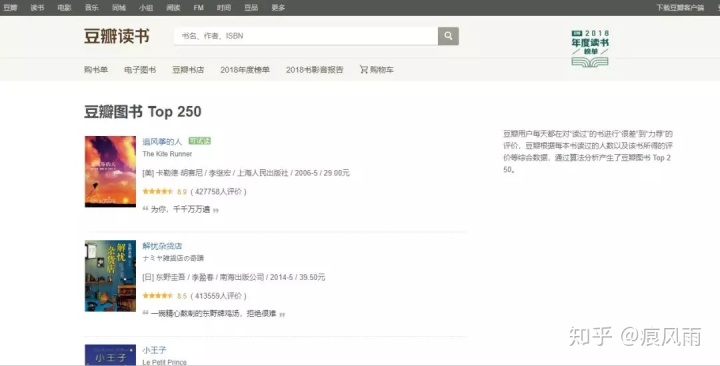
与豆瓣电影Top250差不多,将页面拉到最底部,可以看到分页列表
并且每一页的url也是以25递增,所以爬取思路与豆瓣电影Top250一致。
二、爬取目标
我们本篇要爬取的信息包括书名、作者、出版社、价格、评分、推荐语。
三、爬取首页
- 网页获取源代码
import requests
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
html = requests.get(url,headers=headers)
return html.text
if __name__ == '__main__':
url = 'https://book.douban.com/top250?start=0'
html = get_html(url)
print(html)输出结果

- 解析提取所需信息
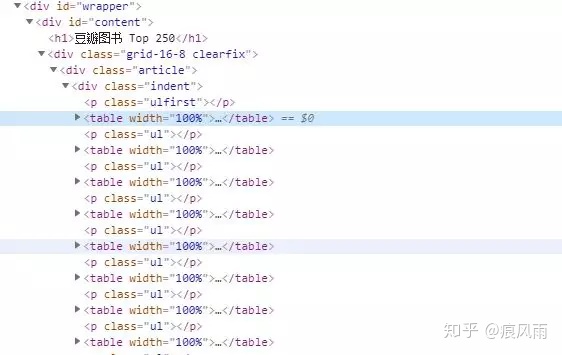
如图,查看源代码我们可以知道页面中书的信息均包含在一个个<table>标签中,所以我们可以先用CSS选择器将一个个<table>节点选出来,然后在使用循环提取每一本书的信息。提取<table>节点的代码如下:
def parse_html(html):
soup = BeautifulSoup(html,'lxml')
books = soup.select('div.article div.indent table')
print(books)运行结果如下:

可以看到输出为列表,并且第一个元素包含《追风筝的人》的相关信息。这里我们使用BeautifulSoup中的select()加CSS选择器提取<table>节点。传入的CSS选择器为:div.article div.indent table。其中div.article的意思为选择包含属性class="article"的<div>标签,然后跟空格代表嵌套关系,表示接着选择该<div>下的包含cla
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









