





《Streaming 102》将流式计算的主要问题总结成 What/Where/When/How 四个方面,What 讲的是数据流经流水线时应用各种转换(transformation)的进行的计算,流式计算特有的概念主要是后面三个,这三个概念相互关联,而其中关系到计算触发的逻辑与时间的判断和处理息息相关。
不同于批式计算处理有限的数据(至少每一批是有限的),流式计算天然地面对无界的数据集。如果只是简单的对每一条数据进行 map/flatmap/filter 操作的话,我们对于海量数据总体(聚合)所体现出来的信息挖掘就相当的不充分了。在现实生活中,我们很可能不止需要对数据进行简单的转换或者筛选——这些都是比较接近预处理的工作——真正产生价值的是诸如【每隔一个小时的成交量/访问量】【大促期间每隔五分钟输出最近一个小时成交额最高的商品】或者【实时显示用户的访问历史】这样的计算,而这些计算都与时间相关。只有把时间人为的划分成一块一块的时间片,我们才能在无限的数据集中取出有限的子集来聚合产生有价值的结果。
完整地介绍整个产生价值的过程牵涉到基于时间或记录的触发计算阶段(trigger)(when),聚合计算的不同类型(window)(where)和多个聚合结果的再聚合(accumulation)(how)。我能力有限,对这三个内容展开主题讲述还是颇为费劲,退而求其次先拆分成各个部分介绍,在行文过程中整理自己思路以后或许可以有一次 recap 来做主题介绍。
本文介绍流式计算系统当中的时间概念,同样在过程当中可能会引用 FLINK 作为实际的流式计算系统例子来说明。
流式计算中的时间分类
时间可以说是分布式系统当中最神奇的属性。时间不会倒退,只会前进,但是不同机器上的时钟却很可能是不同步的。另外,由于网络延时和处理延时,甚至数据被主动存储并延后处理,事件产生的时间往往和它被处理的时间是不一致的,甚至有可能有巨大的差别。在流式计算系统当中有两种典型的时间,一种是事件产生的时间(event time),另一种是事件被处理的时间(processing time),它们的区别简单来说如下所示。
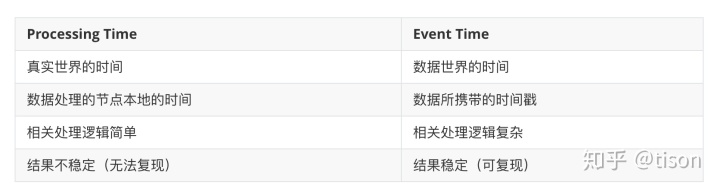
展开来说,Processing Time 表示的是数据被处理的时间,即真实世界当中发生数据被处理的时刻;Event Time 是数据产生时所带有的有信息价值的时间。回忆本系列前一章的内容,在容错场景下,由于 Event Time 是关联到数据记录的,也即是可重放的,因此基于 Event Time 的数据处理结果是可复现的;与之相对的,Processing Time 与实际处理的时间有关,在容错场景下并不能保证容错前后的结果一致(回忆前一章提到的非确定性的输出)。
可想而知,对于基于时间的数据处理逻辑,Event Time 几乎是必需的选项。Processing Time 的用处通常用于流式计算系统自身的指标监控以及系统告警,或者作为周期性的触发时间无关的数据窗口计算的触发器。
另外,在 FLINK 以及其他一些系统当中还会有一种 Ingestion Time 的概念,它指的是数据进入流式计算系统的时间。也就是说,数据的时间戳信息等于它进入流式计算系统的时刻。这样的时间能够避免使用 Processing Time 时由于不同计算节点之间的数据传输延迟等等的原因带来的更大幅度的结果抖动。但是它并不一定是准确的 Event Time,如果事件在产生之后立即进入流式计算系统被处理,而且这部分延迟先验地知道可以忍受,就可以使用 Ingestion Time 来处理数据,如果数据源本身没有 Event Time 的消息,或者进入流式计算系统的时间就是逻辑上的的 Event Time,那么这个时候 Ingestion Time 与 Event Time 就是等价的。
Watermark
Watermark 定义
在我们开篇就提到的例子里有一个是【每隔一个小时的访问量】,关于这个例子与窗口相关的语义我们暂且不提,在 Processing Time 的场景下,我们可以根据节点本地的时间使用 Timer 每隔一个小时定期触发一次计算。可是在 Event Time 的场景下,上游数据并不一定是有序产生的,传输过程也未必处处都保证有序,因此我们并不能保证到来的数据其 Event Time 属性必定是递增的。即使我们通过数据携带的 Event Time 得知当前数据的时间戳距离上次触发的窗口的时间戳达到一定时间,我们也无法确定后面就再也没有更早的数据了。
那么,在 Event Time 的场景下,我们要怎么知道【一个小时内的数据均已到达】这件事情呢?
现有的流式计算系统基本都支持一种称为 Watermark 的机制来解决这个问题。Watermark 是一种标识输入完整性的标记,携带一个时间戳,当节点收到 Watermark 时,即可认为早于该时间戳的数据均已到达,从而得到某个时间区间内的数据均已到达的结论。这里我们对 Watermark 能够标识数据完整性做一点讨论。
实际上,Watermark 本身是一种先验知识,也就是说是脱离于流式计算系统本身的,外部的,能够判断数据完整性的标识。从定义上说它就被定义成这样的标识,而不依靠流式计算系统本身来实现。对于 FLINK 这样一个具体实现来说,如果是作业本身定义的 Watermark 产生逻辑,只要它是可靠的,由于 FLINK 底层使用 TCP 传输,那么这个顺序就不会被打破。从概念上说,Watermark 可以按 Perfect Watermark 和 Heuristic Watermark 区分开来。其中前者指的是 Watermark 准确地标识了数据的完整性,后者则是说 Watermark 作为一种启发式的参考不保证准确地标识数据的完整性。在绝大多数情况下,确保数据的完整性要求知道所有输入的信息,这样的条件过于严苛,而且各个组件之间的网络延迟是无可避免的,实在迟到的数据未必会对结果造成显著的影响,因此实践当中 Heuristic Watermark 是常被采用的方式。当然,如果条件允许,Perfect Watermark 是语义上的上位替代。
Watermark 生成
数据处理逻辑处于上述不同时间策略的情况下对 Watermark 的处理方式是不同的。Processing Time 的场景不需要考虑 Watermark,只需要处理节点本地的时间;Event Time 的场景下,数据源根据先验知识产生数据对应的时间戳,理所当然的,Watermark 可以由数据源产生;Ingestion Time 的场景下,数据从数据源产生时即被附上当时时间戳,相应的 Watermark 也由数据源负责产生(在 FLINK 的实现里,Ingestion Time 的数据源根据配置的 Watermark 间隔产生 Watermark,结合 TCP 传输的特点,这是 Perfect Watermark 的一个实例)。
相关源码位置
SourceContext#collectWithTimestamp和SourceContext#emitWatermarkWatermarkContext及其子类
在 FLINK 的实现中,还支持另外一种 Watermark 的生成方式,即通过在上游算子后面串接一个专门处理上游数据并产生 Watermark 的算子。这适用于数据源本身不支持产生 Watermark 或者需要在中间算子根据具体情况产生尽可能精确的 Watermark 的情况。这种方式产生的算子会根据定制的逻辑处理上游到来的数据及其可能带有的时间戳,随后根据定制的逻辑构造 Watermark 向下游发送。FLINK 支持两种插入算子生成 Watermark 的方式。

相关源码位置
AssignerWithPunctuatedWatermarksTimestampsAndPunctuatedWatermarksOperatorAssignerWithPeriodicWatermarksTimestampsAndPeriodicWatermarksOperatorDataStream#assignTimestampsAndWatermarks
Watermark 传播
Watermark 在流式计算系统当中与数据一起从上游传播到下游。
如果算子只有一个上游,由于 Watermark 标识了比其所携带的时间戳早的数据均已到达,因此记录当前的 Watermark 需要对上游发来的 Watermark 从概念上说对其历史序列做取最大值操作。
如果算子具有多个上游,典型的是 KeyBy 的场景,此时算子会接受到多个上游发送的 Watermark,考虑 Watermark 的语义,此时能够确定的完整的数据是对应不同上游的 Watermark 之间最小的那个 Watermark,即时间最早的那一个。这是一种兜底的策略,如果不同输入彼此互不相关或者存在分组的不相关性,这种策略会导致在某一个输入延迟的情况下其他输入被延迟并缓存,可能会导致不必要的延时和缓存爆满。
从上游的角度来说,自身产生的 Watermark 会向所有下游广播。
相关源码位置
Output#emitWatermarkStatusWatermarkValve
Watermark 处理
我们说 Watermark 标识了数据的完整性,回忆一开始我们描述的场景,实际上我们是希望在获取一块完整的数据之后触发相应的聚合操作。因此,当算子收到上游发来的 Watermark 之后,需要执行相应的逻辑来触发计算。
在 FLINK 中,上游到来的 Watermark 会被发送到 InternalTimerService 中,更新其时间戳,并回调相应的触发逻辑,随后被发送到下游。
部分相关源码位置
AbstractStreamOperator#processWatermarkInternalTimerServiceImpl#advanceWatermarkWindowOperator#onEventTime
Lateness
即使使用了 Watermark 的机制,如果是 Heuristic Watermark 的话,仍然可能出现数据迟于 Watermark 到的情况。如前所述,由于现实世界的不确定性和网络延时的普遍性,这几乎不可避免。
在绝大多数流式计算系统都提供了迟到数据的处理,例如在 FLINK 中支持收到 Watermark 后保留一段时间的 WindowState 以相应迟到数据,或者将迟到数据输出到一个 side output 中接入下游或其他算子单独处理。
这部分的内容可以参考官方文档的相应内容,在这里提出是为了完整的说明常见的 Watermark 的启发式特性。在实际生产中,迟到数据不可避免,我们不可能长时间地去等待迟到数据。如果上游的数据总是迟到,那很有可能有更严重的问题需要排查。
不基于时间的触发
上面介绍的是流式计算系统当中的时间的概念,以及时间作为触发聚合的条件的来由和为了这么做需要面对的挑战。实际上,在许多实际应用场景中,我们还可能基于数据来做触发。例如,当收到上游传来的若干条数据时触发一个窗口。
相关源码的位置
Trigger及其子类,特别地CountTrigger实现了上面提到的功能WindowedStream#triggerAllWindowedStream#trigger















 4691
4691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









