








01
缘起统一调度和弹性调度
Aliware
ASI 是 Alibaba Serverless infrastructure 的缩写,是针对云原生应用设计的统一基础设施。
为了实现最大化利用云的能力,通过统一调度,实现了 ASI 成为阿里集团所有业务的底座,包括新加入到统一调度架构的搜推广业务,实时计算 Flink 业务,FaaS 业务,中间件,新计算 PAI 等,以及通过统一调度来进行架构升级的 MaxCompute 业务, 泛电商业务等。ASI 通过一套架构成为所有业务和基础服务的底座,带来的是整体阿里集团的站点交付在容器和调度层面完成大一统,今年在云侧的交付效率提升,在 9.15 完成建站压测验收发挥了非常重要的作用。

图 1:统一调度的合作模式
在这个过程当中,统一调度是 ASI 技术底座,一层调度和各个二层调度,业务方一起通力合作(如图1),从研发,测试,发布一起完成技术大升级,以及通过业务迁移实施最终实现千万级核的规模,确保了双十一 9.15 的云侧顺利交付,并完成双十一大考。
在统一调度的架构基础上,通过弹性调度体系来完成资源和能效优化的目标。包括 CPUShare,CPU 归一化,VPA 垂直伸缩,Federation 集群联邦,重调度技术的规模化铺开,以及 HPA 横向扩缩,ECI 弹性调度的探索。
统一调度架构的升级,弹性调度体系的建设对集群规模化都提出了更高的需求,单集群规模化的需求成为了今年最大的挑战。如搜推广在离线集群实际达到了万级别的节点数,十万级别的 pod 数,调度吞吐千级别 pod/s;MaxCompute 业务 Task 链路达到了每秒十万级别的调度频次;在快上快下大促当天通过在大数据离线集群中快速拉起在线站点场景中,完成了大促当日多个交易导购单元站点的快速拉起和释放。apiserver/scheduler/etcd/webhook/kubelet 上完成了大量的性能优化,具备行业领先性。
02
统一调度架构
Aliware
在线场景下应用服务的资源约束多,追求最佳部署:既要保障应用服务的高可用性,还要保障应用服务的运行时效果,调度吞吐一般比较慢;离线场景下,尤其是以 MaxCompute 为代表的大数据计算场景任务规模大、任务规格小、运行周期短,就要求调度离线任务时需要具备很高的调度吞吐能力(十万级别的调度频次)。
针对在线以及搜索的离线我们采用的 K8s 原生的 pod 链路或 pod 兼容链路。针对 MaxCompute 采用自研的 Task 链路。MaxCompute 单集群上万台机器时,每秒十万级别的调度频次带来这样高频的资源流转对 Kube ApiServer 消息转发以及 etcd 造成很大压力,我们通过性能分析以及压测得出,K8s 的原生 pod 链路能力无法满足 MaxCompute 的性能需求。因此 ASI 统一调度在 K8s 原生 pod 链路上,创造出了基于 Pod 和 Task 双链路的统一调度架构。
03
统一调度架构规模化对 ASI 底座带来的全方位挑战
Aliware
ASI 在统一调度中完成 2 个重要的角色,第一个是供给云原生资源,为业务提供 pod 对应的计算资源;第二个是提供状态数据库,为业务提供状态信息存储。基于 ASI 构建的搜推广等上面跑的离线业务,Blink、PAI、Holo 等新计算平台,APICallLatency 已经成为其计算链路服务 SLO 的关键部分,大促建站,快上快下的在线站点快速交付,APICallLatency 也成为其 Pod 交付 SLO 的关键部分。
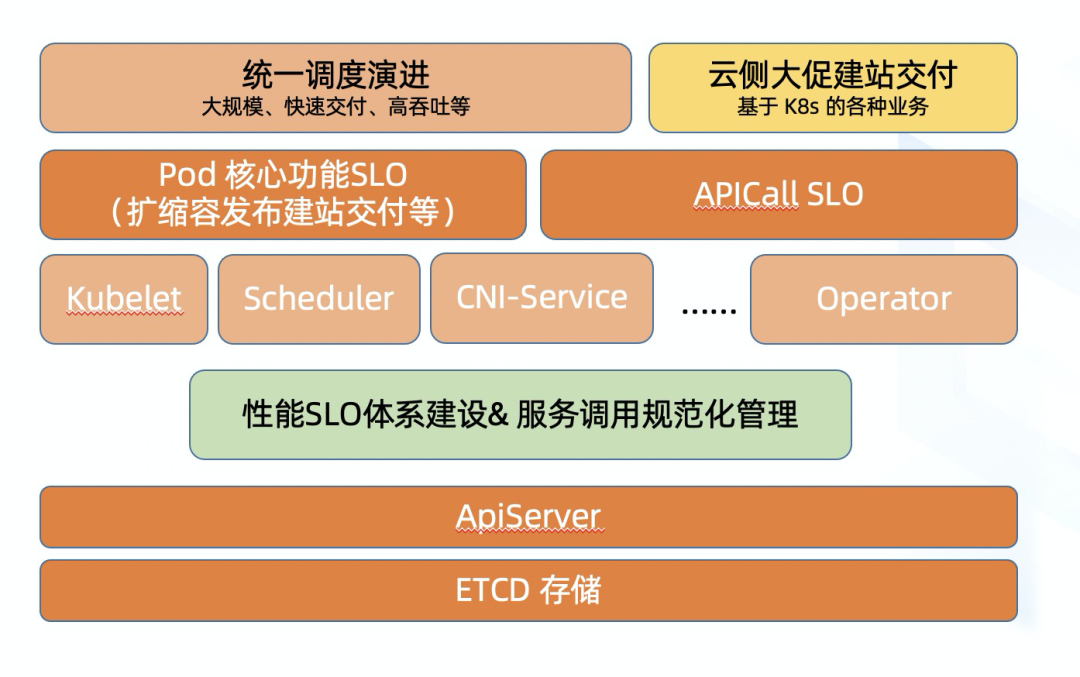
图 2:性能 SLO 体系&服务调用管理大图-APICallLatency 成为 SLO 的关键部分

图 3:社区版本 K8s 的规模限制
面对社区 K8s 5000 的能力现状,ASI 需要满足统一调度万级别节点需要做些什么呢?会面临哪些挑战呢?
1)资源层面:
随着集群规模增大,业务形态的变化,以 IP、云盘为代表的核心资源会打破已有计划性的资源供应,间断性的突发增长,造成资源短缺,出现云资源申请超时问题,造成 Pod 交付失败。
日常单集群每天十万级别的扩缩容量级,如果采用社区版本单机的 DaemonSet 直接访问阿里云 openapi 和 K8s api,对 ASI 的压力都是非常巨大的,都会很容易触发 ASI 或云 openapi 的限流,造成 Pod 交付超时失败。同时在 Serverless 场景下,对这块的扩容效率有更高的要求。
2)节点层面:
随着节点规模增大,kubelet 无法及时更新 node 心跳时间问题,导致节点状态 NotReady,导致容器调度受影响,特别影响到训练作业的生产以及迁移。
3)APIServer 层面:
随着 Pod 规模的增大,WatchCache 的大小满足不了 Pod 访问的要求,出现了大量的watch Error 及 relist 情况。
随着集群资源变化更大时,watch 的性能压力会越大,而在统一调度中,离线的单机客户端也会 watch pod,这意味着 pod 的 watch 请求直接翻倍。在快上快下场景下,需要数十分钟级别快速拉起 10 级别 pod,大规模的 event 推送延迟会更加严峻。
4)ETCD 层面:
随着集群中资源对象数据量的增大,ETCD 存储的数据规模过大,引起 Latency 大幅上涨。
伴随着 Mesh、Dapr、ingress、安全 sidecar 等云原生的需求产生,也包括集团场景以及历史需求的适配和兼容, Pod Size 变得越来越大,阿里面临 50Kb 的 pod Size,远远超过 etcd 2k 性能边界。
同时伴随着单集群组件数量的暴增,超过 100 个以上组件,通过逐层的读写放大,最终造成请求量过多引起的 TooMany Request 问题也此起彼伏。
04
性能瓶颈的分析思考
Aliware
统一调度项目对 ASI 单集群的规模化能力是强依赖的。
首先是搜推广独立集群年初计划数十个集群即将迁移 ASI,并进一步迁移统一调度协议。它上面的集群需要跑大量离线任务,这些离线任务扩缩容接口 QPS 将预计达到千级别 QPS。同时搜推广业务对管控面的可用性依赖比较高,管控面不可用中断时间过长可能会导致 P1、P2 级别故障,需要将管控面性能抖动或者异常恢复时长控制在安全时间范围内。
另外是 ODPS&电商混部场景,快上快下(大促当日在数分钟内完成站点的拉起和释放)第一次在 ASI 场景落地,另外快上快下第一次在 ASI 上进行落地,研发,性能优化和稳定性保障都面临挑战,新的链路对周边系统的系统压力变化也是优先要关注,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









