






 本文介绍了Bootstrap自抽样的基本理论和R语言实现方法,通过重复抽样模拟估计量分布,计算标准误和置信区间,适用于样本量较小的情况。文章以线性回归和扔硬币示例详细阐述了Bootstrap的应用,并演示了如何使用R的boot工具包进行Bootstrap分析。
本文介绍了Bootstrap自抽样的基本理论和R语言实现方法,通过重复抽样模拟估计量分布,计算标准误和置信区间,适用于样本量较小的情况。文章以线性回归和扔硬币示例详细阐述了Bootstrap的应用,并演示了如何使用R的boot工具包进行Bootstrap分析。
开始今天的内容之前,需要大吼一声放假啦!感恩节假期正式开始,并且为防止节假日人流带来的更严重的新冠传染,感恩节之后本学期所有的课程也都将转为线上,也就是说,直到春季学期开学,我都会蜗居在自己的公寓里。来美国那么久,除了学校所在的城市,都没去过其他地方。本来今年暑假打算出游,可惜被疫情打乱,真希望疫情能早点过去。
回到我们的计量话题,今天要讲的内容是bootstrap自抽样。我还记得我在统计课上第一次学bootstrap的时候,全程都在神游,以至于后来做作业时以为bootstrap是什么特别高级难懂的技术问题,很长一段时间内碰到bootstrap就头大。但是后来重新复习的时候,发现bootstrap不过是一个非常简单的重复抽样过程,无非是使用R语言执行相关命令符的时候稍微有那么一点点复杂。如果仅仅局限于线性回归,那么Stata的bootstrap命令符使用就会简单很多。
在之前关于渐近性的推送中,我们有提到过,如果样本容量足够大的话,我们认为渐近性分布接近正态分布,也就满足了关于线性回归的正态分布的重要假设。但是,如果我们的样本容量没有那么大,没办法满足渐近性的要求,那又该怎么办呢?这时候bootstrap就是一个很有用的替代方法,bootstrap本质就是对现有的样本进行重复抽样得到新样本,以这种方法来模拟扩大样本容量。bootstrap的适用范围不仅限于线性回归估计,任何统计学里的估计量都可以通过bootstrap进行量化并且计算standard error标准误。并且我们完全不用在意估计量是否呈正态分布,通过bootstrap进行重复抽样,当重复样本足够多的时候,我们就可以模拟出估计量的分布状态。
bootstrap
bootstrap的基本理论
在前文介绍中我们已经提到,bootstrap本质就是对样本自身的重复抽样。我以一个非常简单的例子来进行解释,我们都知道扔硬币任意一面朝上的概率为0.5,假设我们有一枚硬币,我们随机扔10次,扔100次,扔1000次,随着次数的增多,那么其中一面朝上的概率会越来越接近0.5。假如我们没办法扔那么多次,比如只能扔10次,得出的概率值很大可能不等于0.5,如果我们想知道根据这10次计算出来的概率的误差有多少,应该怎么办呢?渐近性肯定是没办法用了,只有10次,样本容量太小。这时就我们就可以利用bootstrap,我们将这10次的结果记录下来,正面朝上为1,反面朝上为0。之后,我们对样本进行重复抽样,容量仍为10,因为是重复抽样,这10个结果中有的结果可能被抽出来两次甚至多次。第一次重复抽样得到一个新的样本,计算正面朝上的概率值;第二次重复抽样得到一个新的样本,计算正面朝上的概率值;第三次重复抽样得到一个新的样本,计算正面朝上的概率值;一直到第次,计算正面朝上的概率值。将通过重复抽样得到的估计值按照大小从低到高排列,假如我们想要获得95%置信区间,那么我们只需掐头去尾,去掉序列中前2.5%以及后2.5%的估计值,剩下的就是我们的置信区间。比如我们重复了1000次,那么95%的置信区间,从左往右数第25个以及从右往左数第25个就是分位数。我们也可以绘制分布直方图以及密度图,查看估计值的分布形态。下图是我的统计学老师的笔记中解释bootstrap流程的图:
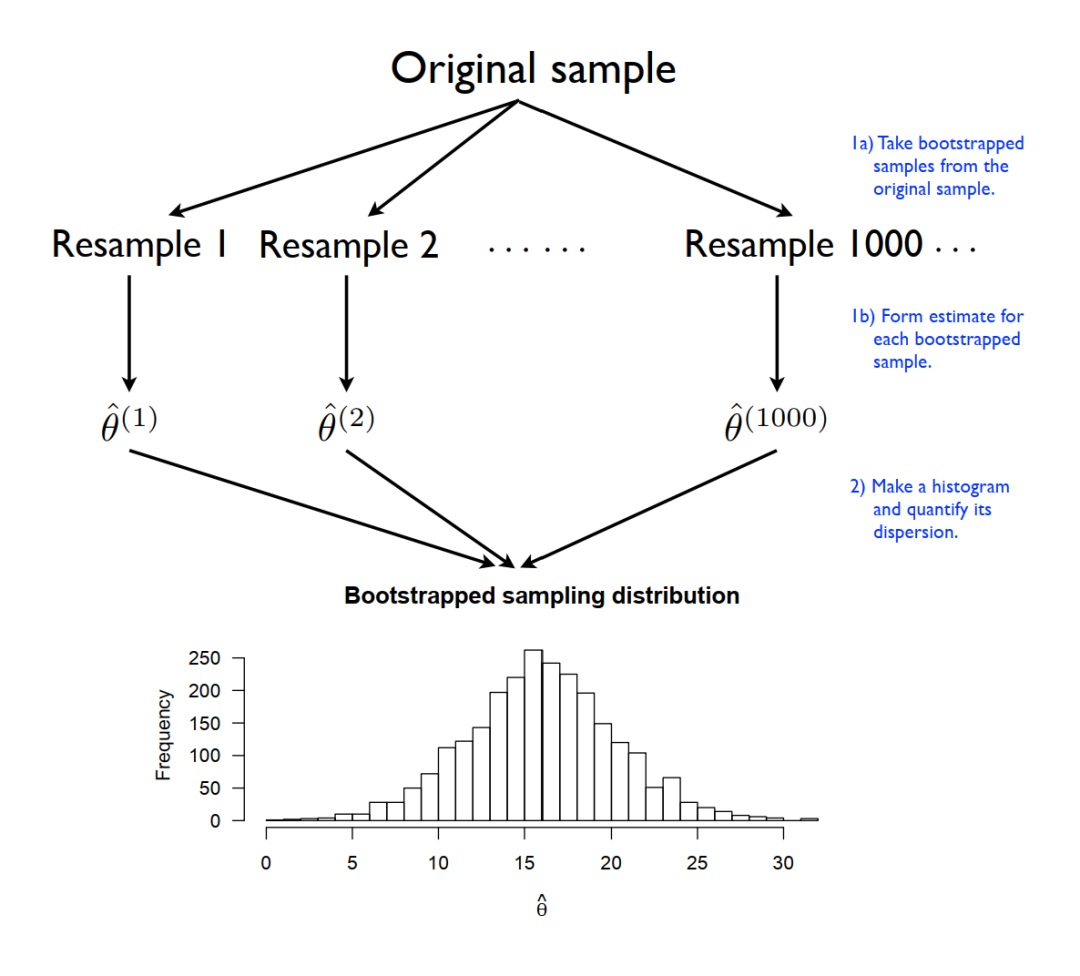
回到线性回归分析,假如我们想要获得回归系数的bootstrap standard error,那么我们只需对样本进行重复抽样,每次对重复抽样获得的样本进行一次回归,就可计算出一个回归系数估计值,而后不断进行重复抽样,假如进行1000次,我们就会获得1000个回归系数的估计值,使用standard error的计算公式,我们就可以计算出bootstrap standard error:
因为任何一个统计学的估计量都
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4456
4456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









