






您记得学习的第一个机器学习算法是什么?对于我们大多数人(包括我自己),答案通常是线性回归。坦率地说,线性回归支撑了我们的机器学习算法阶梯,将其作为技能组合中的基本算法和核心算法。
但是,如果您的线性回归模型无法为目标变量和预测变量之间的关系建模,该怎么办?换句话说,如果它们没有线性关系怎么办?
好吧,这就是多项式回归可能会提供帮助的地方。在本文中,我们将学习多项式回归,并使用Python实现一个多项式回归模型。
如果您不熟悉线性回归的概念,那么我强烈建议您先阅读本文,然后再继续进行。
让我们潜入吧!
什么是多项式回归?
多项式回归是线性回归的一种特殊情况,其中我们在数据上拟合了多项式方程,目标变量和自变量之间具有曲线关系。
在曲线关系中,目标变量的值相对于预测变量以不均匀的方式变化。
在具有单个预测变量的线性回归中,我们具有以下方程式:
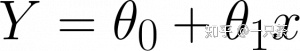
哪里,
Y是目标
x是预测变量,
0 是偏差,
和θ 1 是回归方程中的重量
该线性方程可用于表示线性关系。但是,在多项式回归中,我们有一个次数为n的多项式方程,表示为:
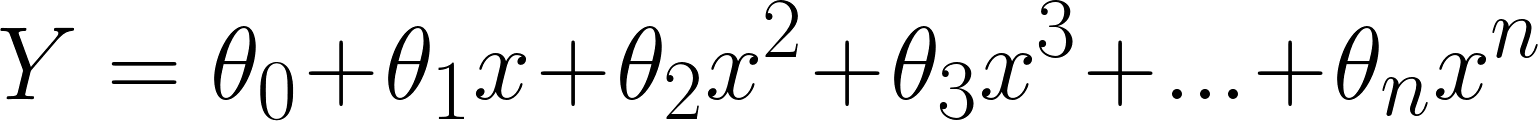
这里:
0 是偏差,
1 , 2 ,…, n 是多项式回归方程式中的权重,
和Ñ是多项式的阶数
高阶项的数量随着n值的增加而增加,因此方程变得更加复杂。
多项式回归与线性回归
现在我们对什么是多项式回归有了基本的了解,让我们打开Python IDE并实现多项式回归。
我将在这里采用稍微不同的方法。我们将在一个简单的数据集上同时实现多项式回归和线性回归算法,在该数据集上,目标和预测变量之间存在曲线关系。最后,我们将比较结果以了解两者之间的区别。
首先,导入所需的库并绘制目标变量和自变量之间的关系:
#导入库
numpy作为np
导入matplotlib.pyplot作为plt
导入pd熊猫
#用于计算sklearn.metrics的均方误差
输入mean_squared_error
#创建曲线关系为
x = 10 * np.random.normal(0,1,70)
的数据集y = 10 *(-x ** 2)+ np.random.normal(-100,100,70)
#绘制数据集
plt.figure(figsize =(10,5))
plt.scatter(x,y,s = 15)
plt.xlabel('Predictor',fontsize = 16)
plt.ylabel('Target',fontsize = 16 )
plt.show()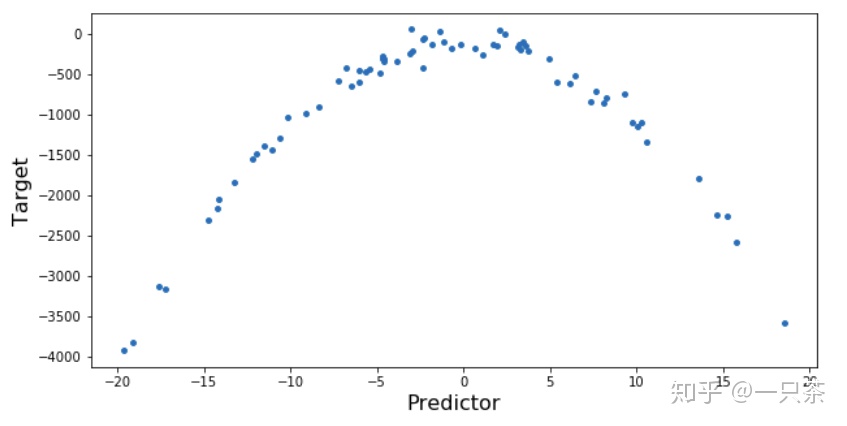
让我们先从线性回归开始:
#
从sklearn.linear_model
导入线性回归import linearRegression
#训练模型
lm = LinearRegression()
lm.fit(x.reshape(-1,1),y.reshape(-1,1))让我们看看线性回归如何在此数据集上执行:
y_pred = lm.predict(x.reshape(-1,1))
#绘制预测
plt.figure(figsize =(10,5))
plt.scatter(x,y,s = 15)
plt.plot(x,y_pred ,color ='r')
plt.xlabel('Predictor',fontsize = 16)
plt.ylabel('Target',fontsize = 16)
plt.show()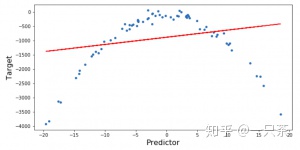
打印('RMSE线性回归=>',np.sqrt(mean_squared_error(y,y_pred)))
在这里,您可以看到线性回归模型无法正确拟合数据,并且RMSE(均方根误差)也很高。
现在,让我们尝试多项式回归。
多项式回归的实现是一个两步过程。首先,我们使用sklearn的PolynomialFeatures 函数将数据转换为多项式,然后使用线性回归拟合参数:

我们可以使用管道使这一过程自动化。可以使用sklearn中的"https://www.analyticsvidhya.com/blog/2020/01/build-your-first-machine-learning-pipeline-using-scikit-learn/?utm_source=blog&utm_medium=polynomial-regression-python">Pipeline 创建管道。
让我们创建一个执行多项式回归的管道:
#从sklearn导入用于多项式转换的
库.preprocessing import PolynomialFeatures
#
从sklearn.pipeline导入
创建管线#创建管线并将其拟合到数据上
Input = [('polynomial',PolynomialFeatures(degree = 2)),('modal' ,LinearRegression())]
pipe =管道(输入)
pipe.fit(x.reshape(-1,1),y.reshape(-1,1))在这里,我采用了2次多项式。我们可以根据目标和预测变量之间的关系选择多项式的阶数。1度多项式是简单的线性回归;因此,度数的值必须大于1。
随着多项式次数的增加,模型的复杂度也增加。因此,必须精确选择n的值。如果此值较低,则模型将无法正确拟合数据;如果该值较高,则模型将很容易过度拟合数据。
在此处阅读有关机器学习中的不足和过度拟合的更多信息。
让我们看一下模型的性能:
poly_pred = pipe.predict(x.reshape(-1,1))
#相对于预测变量对预测值进行
排序sorted_zip = sorted(zip(x,poly_pred))
x_poly,poly_pred = zip(* sorted_zip)
#绘图预测
图(figsize =(10,6))
plt.scatter(x,y,s = 15)
plt.plot(x,y_pred,color ='r',label ='Linear Regression')
plt.plot(x_poly,poly_pred, color ='g',label ='多项式回归')
plt.xlabel('Predictor',fontsize = 16)
plt.ylabel('Target',fontsize = 16)
plt.legend()
plt.show()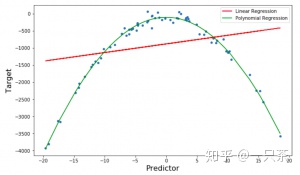
打印('RMSE用于多项式回归=>',np.sqrt(mean_squared_error(y,poly_pred)))
我们可以清楚地观察到,多项式回归比线性回归更适合拟合数据。同样,由于拟合效果更好,多项式回归的RMSE远低于线性回归的RMSE。
但是,如果我们有多个预测变量,该怎么办?
对于2个预测变量,多项式回归方程变为:
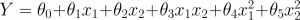
哪里,
Y是目标
x1,x2是预测变量,
0 是偏差,
并且, 1 , 2, 3, 4和 5 是回归方程式中的权重
对于n个预测变量,该方程式包含不同阶多项式的所有可能组合。这被称为多维多项式回归。
但是,多维多项式回归存在一个主要问题-多重共线性。多重共线性是多维回归问题中预测变量之间的相互依存关系。这限制了模型无法正确拟合数据集。
尾注
这是多项式回归的快速介绍。我没有看到很多人在谈论这一点,但是它可以作为一种有用的算法供您在机器学习中使用。














 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









