









1.数据集使用ADFA-LD数据集
def load_all_files():
import glob
x=[]
y=[]
files=glob.glob("ADFA-LD/Attack_Data_Master/*/*")
for file in files:
with open(file) as f:
lines=f.readlines()
x.append(" ".join(lines))
y.append(1)
print("Load black data %d" % len(x))
files=glob.glob("ADFA-LD/Training_Data_Master/*")
for file in files:
with open(file) as f:
lines=f.readlines()
x.append(" ".join(lines))
y.append(0)
print("Load full data %d" % len(x))
return x,y
2.使用N-Gram和TF-IDF提取特征
def get_feature_wordbag():
max_features=1000
x,y=load_all_files()
vectorizer = CountVectorizer(
ngram_range=(3, 3),
token_pattern=r'\b\d+\b',
decode_error='ignore',
strip_accents='ascii',
max_features=max_features,
stop_words='english',
max_df=1.0,
min_df=1 )
print(vectorizer)
x = vectorizer.fit_transform(x)
transformer = TfidfTransformer(smooth_idf=False)
x=transformer.fit_transform(x)
x = x.toarray()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4)
return x_train, x_test, y_train, y_test
3.用多层感知器,XGBoost,朴素贝叶斯训练
def do_mlp(x_train, x_test, y_train, y_test):
clf = MLPClassifier(solver='lbfgs',
alpha=1e-5,
hidden_layer_sizes = (5, 2),
random_state = 1)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print(classification_report(y_test, y_pred))
print(metrics.confusion_matrix(y_test, y_pred))
def do_xgboost(x_train, x_test, y_train, y_test):
xgb_model = xgb.XGBClassifier().fit(x_train, y_train)
y_pred = xgb_model.predict(x_test)
print(classification_report(y_test, y_pred))
print(metrics.confusion_matrix(y_test, y_pred))
def do_nb(x_train, x_test, y_train, y_test):
gnb = GaussianNB()
gnb.fit(x_train,y_train)
y_pred=gnb.predict(x_test)
print(classification_report(y_test, y_pred))
print(metrics.confusion_matrix(y_test, y_pred))
4.训练结果
1)MLP,3-Gram,TF-IDF : 准确率91%
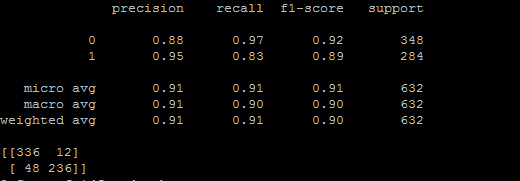
2)XGBoost,3-Gram,TF-IDF : 准确率93%

3)NB,3-Gram,TF-IDF : 准确率90%
















 7658
7658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









