





上篇内容,我们对决策树进行了介绍,探讨了决策树的回归和分类方法,并列出了一些关键参数的说明,构建了超参数学习曲线,本篇内容,我们将基于决策树进行分组回测,对结果进行展示。
开始之前,我们在来回顾一下决策树,决策树学习能根据数据的属性采用树状结构建立决策模型,能够用来解决分类和回归问题,决策树方法简单自然,符合人脑的思维逻辑,除了构建单棵决策树,我们还可以建立多棵决策树并通过某种方式将它们结合在一起,综合投票产生最后的预测值,也就是随机森林。
本篇报告中我们将基于决策树进行预测,并将这个模型应用于多因子选股。
关于模型的思路
在用决策树构建模型的时候,我们先来考虑这个问题,树模型与传统的线性模型相比,优势和缺点在哪里?
首先,它可以处理非数值类特征,如不同板块风格股票涨跌分类问题,也就是说,我们可以将行业标签、甚至地域标签、这样的非数值特征放入特征数据中。
其次,对于连续数值的非线性问题,就比如不做倒数处理的估值因子PE、PB。理论上拿这些数据应用在决策树中时,可以不必考虑数据在0轴上下的不同处理方式。
树模型同样有其缺陷,单独决策树使用时,对特征是带有一定随机性的,并且,在对训练样本敏感,训练过程如不加适当的限制,则结果基本上就会过拟合。
参数寻优的问题与方法
模型的参数优化部分可以参考上篇介绍决策树文章内容,进行学习曲线或者网格搜索,进行剪枝处理。
模型构建过程
参考《人工智能选股之随机森林模型》中模型构建过程,我们按下面步骤进行预测模型搭建
1.数据获取:我们选择股票池为中证500,并剔除ST股票,剔除上市3个月内新股,获取的数据区间为20090101到20190101,回测区间为20140101到20190101。2.特征和标签提取:每个自然月的第一个交易日,计算统计期的 39个因子暴露 度,作为样本的原始特征;计算下一整个自然月的个股超额收益(以中证500 指数为基准),作为样本的标签。3.特征预处理:进行去极值、标准化、中性化操作。 a) 中位数去极值:我们取每个月第一个交易日的因子数据,截面上对各个因子值进行去极值操作; b) 缺失值处理:将缺失的因子值设为申万一级行业相同个股的平均值。 c) 行业市值中性化:将填充缺失值后的因子暴露度对行业哑变量和取对数后的市值 做线性回归,取残差作为新的因子暴露度。 d) 标准化:将因子值减均值除以标准差,得到均值为0,标准差为1的因子值序列 4.训练集合成: a)使用回归方法时,在每个月初截面期,将下月收益作为标签y值,将当前时间往前推 60 个月的样本合并,随机选取 70%的样本作为训练集,余下 30%的样本作为测试集。 b)使用分类方法时,在每个月初截面期,选取下月收益排名前 30%的股票作为正例(y = 1),后 30%的 股票作为负例(y = 0)。 将当前时间往前推60个月的样本合并,随机选取 70%的样本作为训练集,余下 30%的样本作为测试集。 5.样本内训练:使用决策树模型对每期的训练集进行训练,并计算测试集得分。6.样本外测试:得出模型后,以 T 月月初截面期所有样本(即个股)预处理后的特征作为模型的输入,得到每个样本的 T+1 月的预测值(可以根据该预测值构建策略组合,具体细节参考 下文)应用于选股策略
进行分层回溯是常见的单因子分析方法,根据因子值对股票进行打分,构建投资组合回测,是最直观的衡量因子优劣的手段。树模型属于分类器,最终在每个月底可以产生对全部个股下月上涨或下跌的预测值(即各决策树分类结果的投票平均值),可以将预测结果转换为一个因子合成模型,即在每个月底将因子池中所有因子合成为一个“因子”。接下来,我们对该模型合成的这个“因子”(即个股下期预测值)进行分层回测,从各方面考察该模型的效果。仿照华泰单因子测试系列报告中的思路,分层回测模型构建方法如下
分层回测分析
股票池:中证500股票池股票,剔除 ST 股票,剔除上市 3 个月以内的股票。
回测区间:2014-01-01 至 2019-01-01(5年)
换仓期:在每个自然月第一个交易日核算因子值,在下个自然月首个交易日按当日 收盘价换仓。
数据处理方法:将模型的预测值视作单因子,因子值为空的股票不参与分层。
分层方法:按因子值大小进行排序。
评价方法:回测年化收益率、夏普比率、信息比率、最大回撤、胜率等。
下面是该模型中因子值排名靠前的50只股票组合的超额收益净值曲线
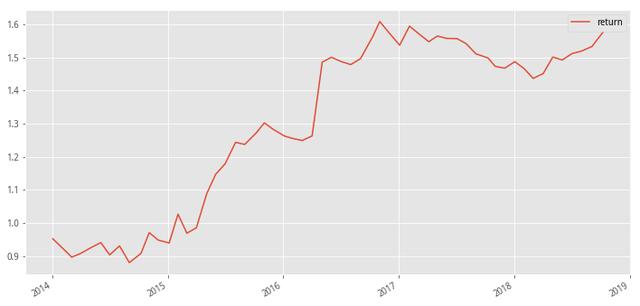
下面是进行分组回测的各分层组合收益情况,决策树所呈现出的分层效果并不理想,未能有明显的分层效果

模型样本内(外)得分
与决策树回归模型相比,得分即是模型判断的正确率,决策树分类模型能更直观的展示决策效果,下面就是对该模型样本内与样本外得分情况进行了统计,在每个月月初截面期,将当前时间往前推 60 个月样本内模型得分记为score_p,将对下一期预测值实际得分记为score_r,统计得分如下
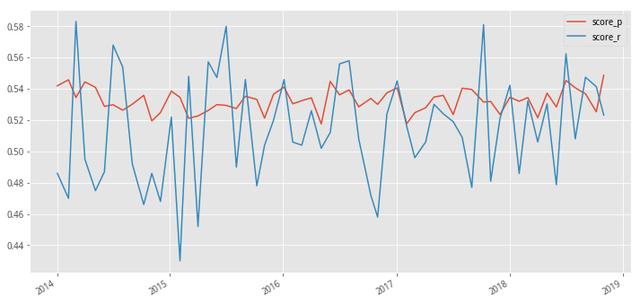
可以看到,样本内与样本外得分差异还是较为明显的,将模型外推进行预测时,预测正确率波动较大。
模型因子特征重要性统计
在上篇决策树介绍中,我们提及过模型有很多属性和方法可以进行获取查看,
在具体的决策树模型构建中,我们将当期股票的各个因子作为输入特征,按照股票下月收益情况分为不同类别,也就是以股票下期收益为标签,以此进行模型训练。对于决策树这一非线性分类器,我们依然可以 通过特征划分过程来计算评估各个因子特征的重要性,
下面我们给出 2014-2019 年间39个模型的特征重要性评分均值柱状图
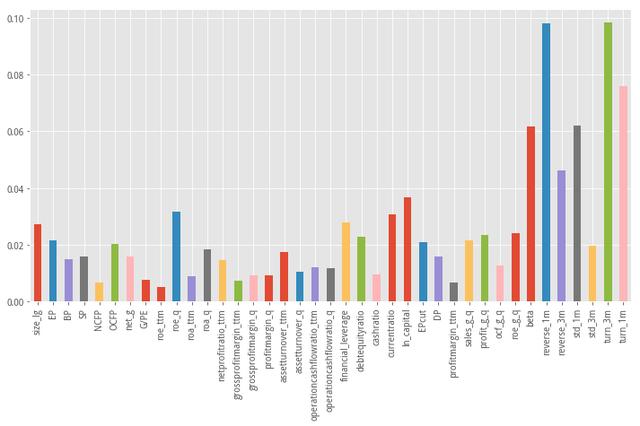
综合历史的特征重要性信息来看,波动率、动量、Beta因子对股价的预测能力明显强于财务类因子,这也印证了A股市场投机行为显著的特性。
总结说明
这篇内容基本上是在展示机器学习中简单模型决策树的工具性,更多的是研究流程方法的说明,从如何构建模型,搭建回测的角度出发,到结果展示汇总。
就模型本身而言,虽然多头部分有超额收益,但是不足以证明该模型的优越性;模型的准确率也有待提高;特征重要性统计部分能获知哪些因子对股价影响较大。一定有很多比决策树更好的方法可以用,比如已知的模型中,由决策树作为基学习器的集成算法随机森林模型,就会比决策树模型要好,有一些认真好学的同学问我,为什么不直接用随机森林呢,那就试试吧, 核心的模型代码替换部分不算多,可以克隆代码进行操作,或者尝试更多的模型。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









