








作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
今天我们来介绍一个非常“暴力”的模型:可逆 ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的 ResNet 模型搞成了可逆的!
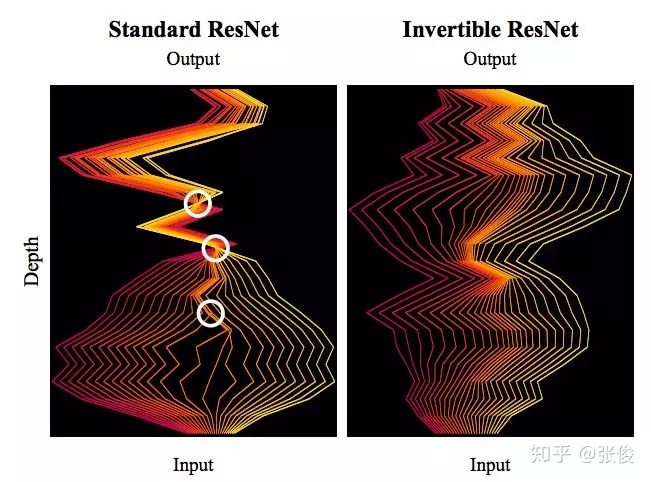
模型出自 Invertible Residual Networks,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。

论文链接:PaperWeekly
可逆模型的点滴
为什么要研究可逆 ResNet 模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于 ResNet 强大的能力,意味着它可能有着比之前的 Glow 模型更好的表现。
总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
而本文要介绍的可逆 ResNet 基本上满足这几点要求,它可逆起来比较简单,而且基本上不改变 ResNet 的拟合能力。因此,我认为它称得上是“美”的模型。
旧模型的局限
可逆模型的研究由来已久,它们被称为“流模型(flow-based model)”,代表模型有 NICE、RealNVP 和 Glow,笔者曾撰文介绍过它们,另外还有一些自回归流模型。除了用来做生成模型,用可逆模型来做分类任务的也有研究,代表作是 RevNet [1] 和 i-RevNet [2]。
这些流模型的设计思路基本上都是一样的:通过比较巧妙的设计,使得模型每一层的逆变换比较简单,而且雅可比矩阵是一个三角阵,从而雅可比行列式很容易计算。
这样的模型在理论上很优雅漂亮,但是有一个很严重的问题:由于必须保证逆变换简单和雅可比行列式容易计算,那么每一层的非线性变换能力都很弱。事实上像 Glow 这样的模型,每一层只有一半的变量被变换,所以为了保证充分的拟合能力,模型就必须堆得非常深(比如 256 的人脸生成,Glow 模型堆了大概 600 个卷积层,两亿参数量),计算量非常大。
硬“杠”残差模型
而这一次的可逆 ResNet 跟以往的流模型不一样,它就是在普通的 ResNet 结构基础上加了一些约束,就使得模型成为可逆的,实际上依然保留了 ResNet 的基本结构和大部分的拟合能力。这样一来,以往我们在 ResNet 的设计经验基本上还可以用,而且模型不再需要像 Glow 那样拼命堆卷积了。
当然,这样做是有代价的,因为没有特别的设计,所以我们需要比较暴力的方法才能获得它的逆函数和雅可比行列式。所以,这次的可逆 ResNet,很美,但也很暴力,称得上是“极致的暴力美学”。
可逆“三要素”
ResNet 模型的基本模块就是:

也就是说本来想用一个神经网络拟合 y 的,现在变成了用神经网络拟合 y−x 了,其中 x,y 都是向量(张量)。这样做的好处是梯度不容易消失,能训练深层网络,让信息多通道传输,等等。可逆的意思就是 x+g(x) 是一个一一映射,也就是说每个 x 只有一个 y 与之对应,反过来也是,换言之我们理论中可以从中解出反函数 x=h(y) 来。
背景就不多说了,但是要说明一点,我们在分类问题中用的广义上的 ResNet,是允许通过 1×1 卷积改变维度的,但这里的 ResNet 指的是不改变维度的 ResNet,也就是说 x,y 的大小保持一样。
对于一个号称“可逆”的模型,必须要回答三个问题:
- 什么时候可逆?
- 逆函数是什么?
- 雅可比行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









