







目录
监督机器学习问题就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时最小化误差。最小化误差是为了让我们的模型拟合我们的训练数据,而规则化参数是防止我们的模型过分拟合我们的训练数据。
规则化符合奥卡姆剃刀(Occam's razor)原理。在所有可能选择的模型中,我们应该选择能够很好地解释已知数据并且十分简单的模型。从贝叶斯估计的角度来看,规则化项对应于模型的先验概率。民间还有个说法就是,规则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)。
一般来说,监督学习可以看做最小化下面的目标函数:
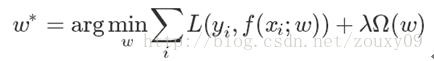
其中,第一项![]() 衡量我们的模型(分类或者回归)对第i个样本的预测值
衡量我们的模型(分类或者回归)对第i个样本的预测值![]() 和真实的标签
和真实的标签![]() 之前的误差。因为我们的模型是要拟合我们的训练样本,所以要求这一项最小,也就是要求我们的模型尽量的拟合我们的训练数据。但正如上面说言,我们不仅要保证训练误差最小,我们更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数w的规则化函数
之前的误差。因为我们的模型是要拟合我们的训练样本,所以要求这一项最小,也就是要求我们的模型尽量的拟合我们的训练数据。但正如上面说言,我们不仅要保证训练误差最小,我们更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数w的规则化函数![]() 去约束我们的模型尽量的简单。
去约束我们的模型尽量的简单。
机器学习的大部分带参模型都和这个神似。其实大部分就是变换这两项而已。对于第一项Loss函数,如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是exp-Loss,那就是Boosting了;如果是log-Loss,那就是Logistic Regression了;还有等等。不同的loss函数,具有不同的拟合特性,这个也得就具体问题具体分析。但这里,我们先不研究loss函数的问题,我们把目光转向“规则项![]() ”。
”。
规则化函数![]() 也有很多种选择,一般是模型复杂度的单调递增函数,模型越复杂,规则化值就越大。比如,规则化项可以是模型参数向量的范数。然而,不同的选择对参数w的约束不同,取得的效果也不同,但我们在论文中常见的都聚集在:L0范数、L1范数、L2范数、迹范数、Frobenius范数和核范数等等。
也有很多种选择,一般是模型复杂度的单调递增函数,模型越复杂,规则化值就越大。比如,规则化项可以是模型参数向量的范数。然而,不同的选择对参数w的约束不同,取得的效果也不同,但我们在论文中常见的都聚集在:L0范数、L1范数、L2范数、迹范数、Frobenius范数和核范数等等。
0 范数
在线性代数,函数分析等数学分支中,范数(Norm)是一个函数,其赋予某个向量空间(或矩阵)中的每个向量以长度或大小。对于零向量,另其长度为零。直观的说,向量或矩阵的范数越大,则我们可以说这个向量或矩阵也就越大。有时范数有很多更为常见的叫法,如绝对值其实便是一维向量空间中实数或复数的范数,而Euclidean距离也是一种范数。
范数的一般化定义:设p≥1的实数,p-norm定义为:

- 当p=1时,我们称之为taxicab Norm,也叫Manhattan Norm。其来源是曼哈顿的出租车司机在四四方方的曼哈顿街道中从一点到另一点所需要走过的距离。也即我们所要讨论的l1范数。其表示某个向量中所有元素绝对值的和。
- 当p=2时,则是我们最为常见的Euclidean norm。也称为Euclidean distance。也即我们要讨论的l2范数。
- 而当p=0时,因其不再满足三角不等性,严格的说此时p已不算是范数了,但很多人仍然称之为l0范数。 这三个范数有很多非常有意思的特征,尤其是在机器学习中的正则化(Regularization)以及稀疏编码(Sparse Coding)有非常有趣的应用。
下图给出了一个Lp球的形状随着P的减少的可视化图。 
1 L0 范数
虽然L0严格说不属于范数,我们可以采用以下公式来给出L0-norm得定义:

0的指数和平方根严格意义上是受限条件下才成立的。因此在实际应用中,多数人给出下面的替代定义:

其表示向量中所有非零元素的个数。正是L0范数的这个属性,使得其非常适合机器学习中稀疏编码,特征选择的应用。通过最小化L0范数,来寻找最少最优的稀疏特征项。但不幸的是,L0范数的最小化问题在实际应用中是NP难问题。因此很多情况下,L0优化问题就会被relaxe为更高维度的范数问题,如L1范数,L2范数最小化问题。
2 L1 范数
2.1 L1
对于向量X,其L1范数的定义如下:

L1范数(Lasso回归)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。如在计算机视觉中的Sum of Absolute Differents,Mean Absolute Error,都是利用L1范式的定义。
2.2 L1正则化和特征选择
稀疏模型与特征选择:
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0。通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
假设有如下带L1正则化的损失函数:
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此J是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=![]() ,则J=J0+LJ,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1、w2的二维平面上画出来。如下图:
,则J=J0+LJ,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1、w2的二维平面上画出来。如下图:
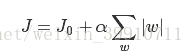
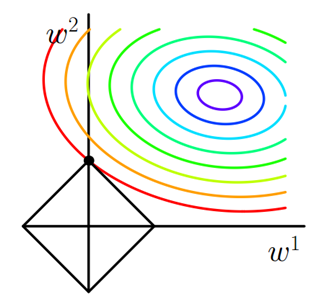
图1 L1正则化
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中原始损失函数J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数α,可以控制L图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
2.3 拉普拉斯先验与L1正则化
2.3.1 拉普拉斯分布
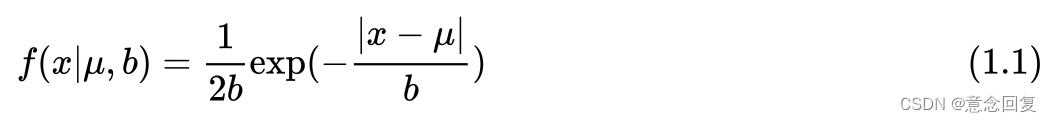
2.3.2 拉普拉斯先验
假设数据服从拉普拉斯分布,即参数遵循拉普拉斯分布

从这里我们可以看出拉普拉斯先验等同于常数+L1正则化,即MLE+L1正则化。
3 L2 范数
3.1 L2
范数中最常见,也最著名的非L2范数莫属。其应用也几乎包括科学和工程的各个领域。定义公式如下:

也叫Euclidean Norm(欧几里得范数),如果用于计算两个向量之间的不同,即是Euclidean Distance。
在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。
欧几里德范数的最优化问题可以用如下公式表述:

3.2 L2正则化和过拟合
假设有如下带L2正则化的损失函数:
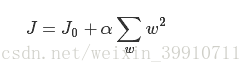
同样可以画出他们在二维平面上的图形,如下:
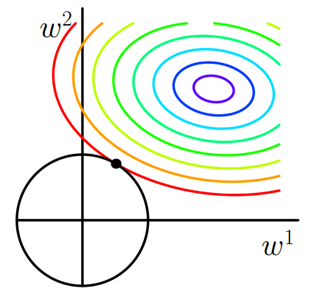
图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θ,hθ(x)是我们的假设函数,那么线性回归的代价函数如下:
那么在梯度下降法中,最终用于迭代计算参数θ的迭代式为:
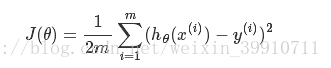
其中α是learning rate。上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:
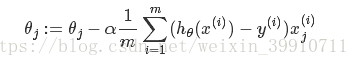
其中λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θj都要先乘以一个小于1的因子,从而使得θj不断减小,因此总得来看,θ是不断减小的。
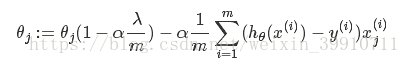
L2正则化参数:
从上式可以看到,λ越大,θj衰减得越快。另一个理解可以参考图2,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
3.3 L2正则化和优化计算
从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下,矩阵求逆很困难的问题。
3.3.1 condition number
condition number衡量的是输入发生微小变化的时候,输出会发生多大的变化。
优化有两大难题,一是:局部最小值,二是:ill-condition病态问题。(1)我们要找的是全局最小值,如果局部最小值太多,那我们的优化算法就很容易陷入局部最小而不能自拔。(2)ill-condition对应的是well-condition。那他们分别代表什么?假设我们有个方程组AX=b,我们需要求解X。如果A或者b稍微的改变,会使得X的解发生很大的改变,那么这个方程组系统就是ill-condition的,反之就是well-condition的。
举个例子:

图3 ill-conditioned

图4 well-condition
如图3,第一行假设是AX=b,第二行稍微改变下b,得到的x和没改变前的差别很大。第三行稍微改变下系数矩阵A,可以看到结果的变化也很大。换句话来说,这个系统的解对系数矩阵A或者b太敏感了。又因为一般系数矩阵A和b是从实验数据里面估计得到的,所以它是存在误差的,如果我们的系统对这个误差是可以容忍的就还好,但系统对这个误差太敏感了,以至于我们的解的误差更大,那这个解就太不靠谱了。所以这个方程组系统就是ill-conditioned病态的,不正常的,不稳定的,有问题的。图4 是well-condition的系统了。
对于一个ill-condition的系统,输入稍微改变下,输出就发生很大的改变,这表明系统不实用。例如对于一个回归问题y=f(x),用训练样本x去训练模型f,使得y尽量输出我们期待的值,例如0。那假如遇到一个样本x’,这个样本和训练样本x差别很小,面对他,系统本应该输出和上面的y差不多的值,例如0.00001,最后却输出了一个0.9999,这很明显不对。所以如果一个系统是ill-conditioned病态的,我们就会对它的结果产生怀疑。那到底要相信它多少呢?得找个标准来衡量,上面的condition number就是拿来衡量ill-condition系统的可信度的。
condition number衡量的是输入发生微小变化的时候,输出会发生多大的变化。也就是系统对微小变化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。
条件数的计算:设e为b的误差,A为非奇异矩阵,则方程解x的相对误差与b的相对误差的比率为
ratio=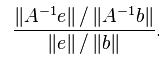
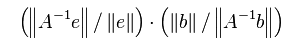
注意|| ||定义的是矩阵的2-范数,矩阵的范数确定了被该矩阵相乘向量长度的最大可能的放大倍数
该式的最大值等于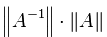
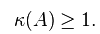
即:如果方阵A是非奇异的,那么A的condition number定义为:
![]()
也就是矩阵A的norm乘以它的逆的norm。
如果方阵A是奇异的,那么A的condition number就是正无穷大了。这时即使不改变 b,x 也可以改变。奇异的本质原因在于矩阵有 0 特征值,x 在对应特征向量的方向上运动不改变 Ax 的值。如果一个特征值比其它特征值在数量级上小很多,x 在对应特征向量方向上很大的移动才能产生 b 微小的变化,这就解释了为什么这个矩阵为什么会有大的条件数,事实上,正则阵在二范数下的条件数就可以表示成 abs(最大特征值/最小特征值)。
注:定义,奇异矩阵是线性代数的概念,就是对应的行列式等于0的矩阵,反之则为非奇异矩阵
两者的判断方法:
首先,看这个矩阵是不是方阵(即行数和列数相等的矩阵。若行数和列数不相等,那就谈不上奇异矩阵和非奇异矩阵)。 然后,再看此方阵的行列式|A|是否等于0,若等于0,称矩阵A为奇异矩阵;若不等于0,称矩阵A为非奇异矩阵。 同时,由|A|≠0可知矩阵A可逆,这样可以得出另外一个重要结论:可逆矩阵就是非奇异矩阵,非奇异矩阵也是可逆矩阵。 如果A为奇异矩阵,则AX=0有无穷解,AX=b有无穷解或者无解。如果A为非奇异矩阵,则AX=0有且只有唯一零解,AX=b有唯一解。
每一个可逆方阵都存在一个condition number。但如果要计算它,我们需要先知道这个方阵的norm(范数)和Machine Epsilon(机器的精度)。为什么要范数?范数就相当于衡量一个矩阵的大小,我们知道矩阵是没有大小的,当上面不是要衡量一个矩阵A或者向量b变化的时候,我们的解x变化的大小吗?所以肯定得要有一个东西来度量矩阵和向量的大小,他就是范数,表示矩阵大小或者向量长度。经过比较简单的证明,对于AX=b,我们可以得到以下的结论:
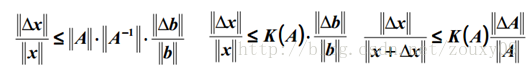
也就是我们的解x的相对变化和A或者b的相对变化是有像上面那样的关系的,其中k(A)的值就相当于倍率,相当于x变化的界。
总结:condition number是一个矩阵(或者它所描述的线性系统)的稳定性或者敏感度的度量,如果一个矩阵的condition number在1附近,那么它就是well-conditioned的,如果远大于1,那么它就是ill-conditioned的;如果一个系统是ill-conditioned的,它的输出结果就不要太相信了。
3.3.2 L2正则化和condition number
从优化或者数值计算的角度来说,L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题。因为目标函数如果是二次的,对于线性回归来说,那实际上是有解析解的,求导并令导数等于零即可得到最优解为:
然而,如果当我们的样本X的数目比每个样本的维度还要小的时候,矩阵![]() 将会不是满秩的,也就是
将会不是满秩的,也就是![]() 会变得不可逆,所以w*就没办法直接计算出来了。或者更确切地说,将会有无穷多个解(因为我们方程组的个数小于未知数的个数)。也就是说,我们的数据不足以确定一个解,如果我们从所有可行解里随机选一个的话,很可能并不是真正好的解,总而言之,我们过拟合了。
会变得不可逆,所以w*就没办法直接计算出来了。或者更确切地说,将会有无穷多个解(因为我们方程组的个数小于未知数的个数)。也就是说,我们的数据不足以确定一个解,如果我们从所有可行解里随机选一个的话,很可能并不是真正好的解,总而言之,我们过拟合了。
但如果加上L2规则项,就变成了下面这种情况,就可以直接求逆了:
要得到这个解,我们通常并不直接求矩阵的逆,而是通过解线性方程组的方式(例如高斯消元法)来计算。考虑没有规则项的时候,也就是λ=0的情况,如果矩阵![]() 的 condition number 很大的话,解线性方程组就会在数值上相当不稳定,而这个规则项的引入则可以改善condition number。
的 condition number 很大的话,解线性方程组就会在数值上相当不稳定,而这个规则项的引入则可以改善condition number。
另外,如果使用迭代优化的算法,condition number 太大仍然会导致问题:它会拖慢迭代的收敛速度,而规则项从优化的角度来看,实际上是将目标函数变成λ-strongly convex(λ强凸)的了。
λ强凸:
时,我们称f为λ-strongly convex函数,其中参数λ>0。当λ=0时退回到普通convex 函数的定义。
在直观的说明强凸之前,我们先看看普通的凸是怎样的。假设我们让f在x的地方做一阶泰勒近似(一阶泰勒展开:f(x)=f(a)+f'(a)(x-a)+o(||x-a||).):
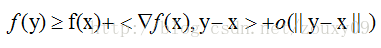
直观来讲,convex 性质是指函数曲线位于该点处的切线,也就是线性近似之上,而 strongly convex 则进一步要求位于该处的一个二次函数上方,也就是说要求函数不要太“平坦”而是可以保证有一定的“向上弯曲”的趋势。专业点说,就是convex 可以保证函数在任意一点都处于它的一阶泰勒函数之上,而strongly convex可以保证函数在任意一点都存在一个非常漂亮的二次下界quadratic lower bound。当然这是一个很强的假设,但是同时也是非常重要的假设。可能还不好理解,那我们画个图来形象的理解下。
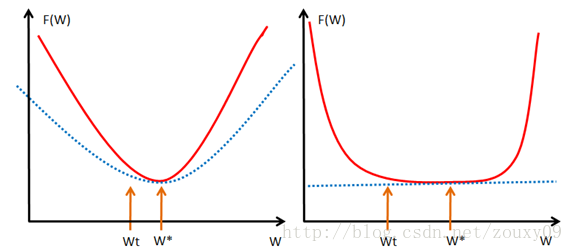
取最优解w*的地方。见左图,函数f(w),也就是红色那个函数,都会位于蓝色虚线的二次函数之上,这样就算wt和w*离的比较近的时候,f(wt)和f(w*)的值差别还是挺大的,也就是会保证在我们的最优解w*附近的时候,还存在较大的梯度值,这样我们才可以在比较少的迭代次数内达到w*。但对于右图,红色的函数f(w)只约束在一个线性的蓝色虚线之上,假设是如右图的很不幸的情况(非常平坦),那在wt还离我们的最优点w*很远的时候,我们的近似梯度(f(wt)-f(w*))/(wt-w*)就已经非常小了,在wt处的近似梯度∂f/∂w就更小了,这样通过梯度下降wt+1=wt-α*(∂f/∂w),我们得到的结果就是w的变化非常缓慢的向我们的最优点w*爬动,那在有限的迭代时间内,它离我们的最优点还是很远。
所以仅仅靠convex 性质并不能保证在梯度下降和有限的迭代次数的情况下得到的点w会是一个比较好的全局最小点w*的近似点(插个话,有地方说,实际上让迭代在接近最优的地方停止,也是一种规则化或者提高泛化性能的方法)。正如上面分析的那样,如果f(w)在全局最小点w*周围是非常平坦的情况的话,我们有可能会找到一个很远的点。但如果我们有“强凸”的话,就能对情况做一些控制,我们就可以得到一个更好的近似解。至于有多好,这里面有一个bound,这个 bound 的好坏也要取决于strongly convex性质中的常数α的大小。如果要获得strongly convex,最简单的就是往里面加入一项![]() 。
。
实际上,在梯度下降中,目标函数收敛速率的上界实际上是和矩阵![]() 的 condition number有关,
的 condition number有关,![]() 的 condition number 越小,上界就越小,也就是收敛速度会越快。
的 condition number 越小,上界就越小,也就是收敛速度会越快。
L2范数不但可以防止过拟合,还可以让我们的优化求解变得稳定和快速。
3.4 高斯先验与L2正则化
3.4.1 高斯分布
假设随机变量X分布的期望为![]() ,方差为
,方差为![]()

3.4.2
假设数据服从高斯分布,即参数![]() 服从高斯分布 :
服从高斯分布 :

从这里我们可以看出高斯先验等同于一个常数+L2正则化即 MLE+L2正则化。
4 L1与L2的差别
对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。

此时加入的正则化项,是解决过拟合问题。
下图是Python中Lasso回归的损失函数,式中加号后面一项![]() 即为L1正则化项。
即为L1正则化项。
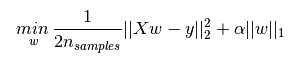
下图是Python中Ridge回归的损失函数,式中加号后面一项![]() 即为L2正则化项。
即为L2正则化项。
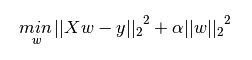
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为
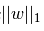
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为
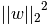
一般都会在正则化项之前添加一个系数。
4.1 下降速度
L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快。所以会非常快得降到0。
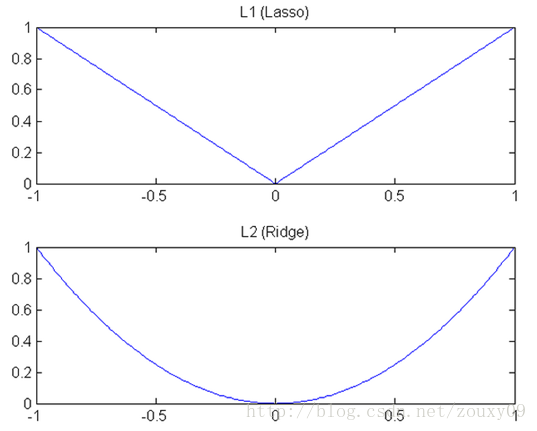
4.2 模型空间的限制
对于L1和L2规则化的代价函数来说,我们可以写成以下形式:
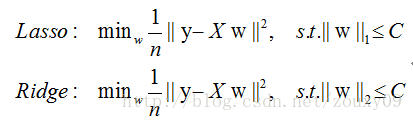
我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解。如图1和图2所示。
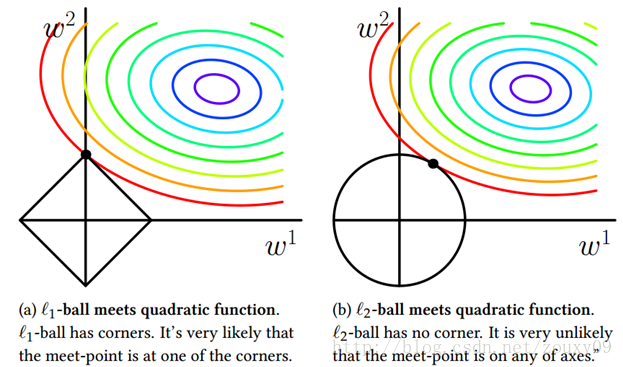
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0;而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
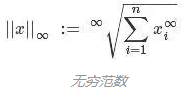
5 无穷范数
借助拉格朗日乘子,我们便可以解决该最优化问题。由L2衍生,我们还可以定义无限norm,即l-infinity norm:
一眼看上去上面的公式还是有点tricky的。我们通过一个简单的数学变换,假设X_j是向量中最大的元素,则根据无限大的特性,我们可以得到:
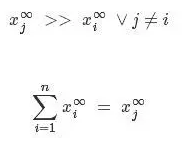
则根据公式无穷范数的定义,我们可以得到:
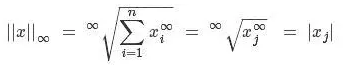
因此我们便可以说l-infinity norm是X向量中最大元素的长度。
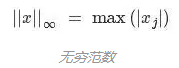
L0正则、L1正则和L2正则
正则化:机器学习中正则化项L1和L2的直观理解_阿拉丁吃米粉的博客-CSDN博客_l1 l2正则化
正则化方法:L1和L2 regularization、数据集扩增、dropout:正则化方法:L1和L2 regularization、数据集扩增、dropout_wepon_的博客-CSDN博客_l2 regularization
机器学习中的范数规则化之(一)L0、L1与L2范数:机器学习中的范数规则化之(一)L0、L1与L2范数_zouxy09的博客-CSDN博客_l1范数














 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









