






使用方法链的关键之一是知道在链条的每个步骤中返回的确切对象。在Pandas中,这总是某个DataFrame、Series或标量值。
目录
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
使用DataFrame方法链
在1.9节“使用Series方法链”中展示了将若干个Series方法结合在一起形成方法链的示例。本章中的所有方法链都将从DataFrame开始。使用方法链的关键之一是知道在链条的每个步骤中返回的确切对象。在Pandas中,这总是某个DataFrame、Series或标量值。在此秘笈中,我们将统计movie数据集每一列中的缺失值。
实战操作
(1)使用.isnull 方法获取缺失值的计数。.isnull方法会将每个值更改为布尔值,以指示是否为缺失值。
>>> movies = pd.read_csv("data/movie.csv")
>>> def shorten(col):
... return col.replace("facebook_likes", "fb").replace(
... "_for_reviews", ""
... )
>>> movies = movies.rename(columns=shorten)
>>> movies.isnull().head()
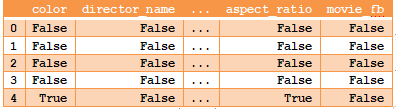
(2)在方法链上添加一个.sum方法,该方法将True和False分别解释为1和0。由于这是一种归约方法,因此结果将被聚合为一个Series。
>>> (movies.isnull().sum().head())

(3)这里还可以更进一步,取该Series的总和,这样就可以将整个DataFrame中缺失值总数的计数作为标量值返回。
>>> movies.isnull().sum().sum()
2654
(4)反过来,如果要确定整个DataFrame中是否包含缺失值,则可以在方法链中连续两次使用.any方法。
>>> movies.isnull().any().any()
True
原理解释
.isnull方法将返回一个与调用它的DataFrame相同大小的DataFrame,只是其所有值都已转换为布尔值。可以通过查看以下数据类型的计数来验证这一点。
>>> movies.isnull().dtypes.value_counts()
bool 28
dtype: int64
在Python中,布尔值的取值为0和1,这使得在步骤(2)中进行列求和成为可能。返回的Series本身也具有.sum方法,因此可以通过这种方式统计在DataFrame中包含的全部缺失值的数量。在步骤(4)中,DataFrame中的.any方法返回一个布尔值Series,指示每列是否至少存在一个True。再次将 .any方法链接到生成的布尔值Series上,即可确定是否有任何列包含缺失值。如果步骤(4)的评估结果为True,则整个DataFrame中至少有一个缺失值。
扩展知识
movie数据集中包含object数据类型的大多数列都包含缺失值。默认情况下,聚合方法(.min、.max和.sum)不会为object列返回任何内容。在以下代码片段中,选择了3个object列并尝试查找每个object列的最大值。
>>> movies[["color", "movie_title", "color"]].max()
Series([], dtype: float64)
为了强制Pandas为每一列返回值,必须填充缺失值。在本示例中,我们选择给缺失值填充一个空字符串。
>>> movies.select_dtypes(["object"]).fillna("").max()
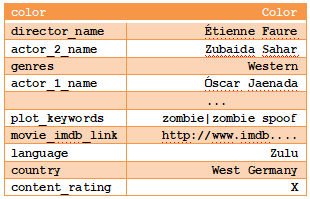
Length: 12, dtype: object
出于代码的可读性考虑,方法链通常被编写为每行一个方法调用,并通过括号将其括起来。在方法链每步返回的内容上,这将简化注释的阅读和插入;或者注释掉某些行进行调试。
>>> (movies.select_dtypes(["object"]).fillna("").max())

Length: 12, dtype: object
了解DataFrame的操作
在1.8节“了解Series的操作”中提供了有关运算符/操作符的入门知识,这将对你了解DataFrame的操作也有所帮助,因为Python的算术运算符和比较运算符可以与DataFrame协同工作,就像其与Series协同工作一样。当算术运算符或比较运算符与DataFrame协同工作时,每列的每个值都会对其应用操作。通常而言,当运算符或比较运算符与DataFrame协同工作时,列全部为数字,或全部为对象(通常为字符串)。如果DataFrame确实不包含同类数据,则该操作很可能失败。现在来看一个失败示例。在college数据集中,同时包含了数字和对象数据类型。尝试将5加到DataFrame的每个值上时,会引发TypeError(类型错误),这是因为不能将整数和字符串加到一起。
>>> colleges = pd.read_csv("data/college.csv")
>>> colleges + 5
Traceback (most recent call last):
...
TypeError: can only concatenate str (not "int") to str
因此,要成功将运算符与DataFrame配合使用,首先需要选择同类数据。在此秘笈中,我们将选择所有以 'UGDS_' 开头的列。这些列代表按种族划分的本科生(undergraduate student)的比例。我们将首先导入数据并使用机构名称作为索引的标签,然后使用 .filter方法选择所需的列。
>>> colleges = pd.read_csv(
... "data/college.csv", index_col="INSTNM"
... )
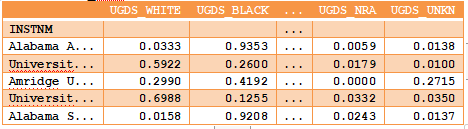
>>> college_ugds = colleges.filter(like="UGDS_")
>>> college_ugds.head()
此秘笈将使用多个运算符和一个DataFrame将本科生的列四舍五入到最接近的百分比值,其结果等效于.round方法。2.7.1 实战操作 (1)Pandas执行的是Bankers舍入规则,该规则简言之就是“四舍六入五成双”。“四舍六入”很好理解(例如,3.4取整为3,3.6取整为4),而“五成双”的意思则是保留位数后一位的数字为5时,根据前一位的奇偶性决定。为偶时向下取整,为奇数时向上取整。例如,3.5取整为4,而4.5同样取整为4。也就是说,取整结果必定为偶数。现在可以将该Series舍入到小数点后两位,看看UGDS_BLACK行会发生什么。
>>> name = "Northwest-Shoals Community College"
>>> college_ugds.loc[name]
UGDS_WHITE 0.7912
UGDS_BLACK 0.1250
UGDS_HISP 0.0339
UGDS_ASIAN 0.0036
UGDS_AIAN 0.0088
UGDS_NHPI 0.0006
UGDS_2MOR 0.0012
UGDS_NRA 0.0033
UGDS_UNKN 0.0324
Name: Northwest-Shoals Community College, dtype: float64
>>> college_ugds.loc[name].round(2)
UGDS_WHITE 0.79
UGDS_BLACK 0.12
UGDS_HISP 0.03
UGDS_ASIAN 0.00
UGDS_AIAN 0.01
UGDS_NHPI 0.00
UGDS_2MOR 0.00
UGDS_NRA 0.00
UGDS_UNKN 0.03
Name: Northwest-Shoals Community College, dtype: float64
如果在舍入之前先加.0001,则舍入结果会发生变化。
>>> (college_ugds.loc[name] + 0.0001).round(2)
UGDS_WHITE 0.79
UGDS_BLACK 0.13
UGDS_HISP 0.03
UGDS_ASIAN 0.00
UGDS_AIAN 0.01
UGDS_NHPI 0.00
UGDS_2MOR 0.00
UGDS_NRA 0.00
UGDS_UNKN 0.03
Name: Northwest-Shoals Community College, dtype: float64
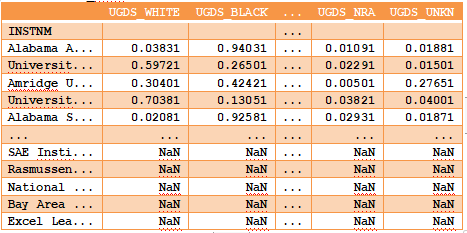
(2)我们可以对DataFrame执行此操作。要开始使用运算符执行舍入计算,可以首先将.00501添加到college_ugds的每个值中。
>>> college_ugds + 0.00501
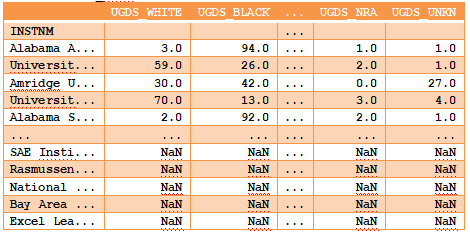
(3)使用向下取整除法运算符(//)向下舍入到最接近的整数百分比。
>>> (college_ugds + 0.00501) // 0.01
(4)要完成舍入运算,需要除以100。
>>> college_ugds_op_round = (
... (college_ugds + 0.00501) // 0.01 / 100
... )
>>> college_ugds_op_round.head()
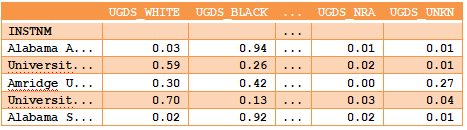
(5)使用DataFrame方法round自动进行舍入。由于Pandas采用的是Bankers舍入规则,因此在舍入前可以添加一个小数.00001。
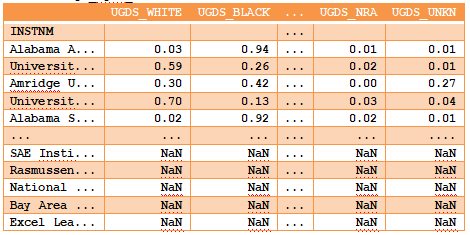
>>> college_ugds_round = (college_ugds + 0.00001).round(2)
>>> college_ugds_round
(6)使用DataFrame方法equals测试两个DataFrame的相等性。
>>> college_ugds_op_round.equals(college_ugds_round)
True
原理解释
步骤(1)和步骤(2)均使用了加法运算符,该运算符尝试将标量值添加到DataFrame每列的每个值上。由于列都是数字,因此此操作可以按预期进行。每列中都有一些缺失值,但是在操作后这些缺失值将保持缺失。从数学上讲,添加.005应该足够让下一步中的向下取整除法正确舍入到最接近的整数百分比。但是,这也可能由于浮点数的不精确性而出现问题。
>>> 0.045 + 0.005
0.049999999999999996
这就是为什么要在舍入之前对每个数字都加.00001,以确保浮点表示的前四位数字与实际值相同。这样之所以可行,是因为数据集中所有点的最大精度是4个小数位。步骤(3)将向下取整除法运算符(//)应用于DataFrame的所有值中。实际上,当我们使用小数除时,取整除法运算符会将每个值乘以100并舍去任何小数。在表达式的第一部分周围需要使用括号,这是因为向下取整除法的优先级高于加法。步骤(4)使用了除法运算符将小数返回正确的位置处。在步骤(5)中,我们使用round方法重现了先前的步骤。在执行此操作之前,由于与步骤(2)不同的原因,我们必须再次向每个DataFrame值中添加一个额外的.00001。NumPy和Python 3的舍入规则就是上面介绍过的Bankers舍入规则,该规则通常不是学校正式教授的规则(学校教授的规则一般是四舍五入)。在本示例中,有必要舍入以使两个DataFrame值相等。.equals方法将确定两个DataFrame之间的所有元素和索引是否完全相同,并返回一个布尔值。
扩展知识
与Series一样,DataFrame也具有与运算符等效的方法。分析人员可以将运算符替换为其等效的方法。
>>> college2 = (
... college_ugds.add(0.00501).floordiv(0.01).div(100)
... )
>>> college2.equals(college_ugds_op_round)
True
推荐书单
《Pandas1.x实例精解》

本书详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
购买链接:https://u.jd.com/9IOYicg
精彩回顾
微信搜索关注《Python学研大本营》
访问【IT今日热榜】,发现每日技术热点















 7539
7539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









