






Python使用BeautifulSoup、Requests、Seaborn和Pandas从TripAdvisor上抓取任意城市的餐厅数据,并进行数据分析。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩

使用Python进行网络抓取
通过网络采集技术,可以从网站上提取多种数据,比如产品价格、评级和其他类型的信息。有了这些数据之后,就可以将其用于各种目的,比如数据分析、研究、商业智能和数据科学。在Python中,网络采集通常使用Beautiful Soup、Scrapy和Requests等库来完成,这些库可帮助我们更容易地从网页中获取和解析数据。
抓取餐厅数据进行分析
在这个项目中,旨在从任何国家的任何城市抓取餐厅的详细资料,同时从抓取的数据中进行探索性数据分析,这将能使你成为使用Python进行网络抓取的专家。

csv的格式什么样?
抓取的餐厅数据将包含:
-
餐厅名称
-
评论总数
-
评级
-
菜系
其他可用的信息包括页码、餐厅序列号和数据偏移。

采集自德国柏林的数据DataFrame

控制变量/输入参数
在这个项目中,我们选择了德国的柏林。例如,如果我们希望抓取卡纳塔克邦班加罗尔的所有餐馆,我们将在Tripadvisor上对其进行过滤,我们将获得一个如下所示的链接:
https://www.tripadvisor.in/Restaurants-g297628-Bengaluru_Bangalore_District_Karnataka.html。
在这个链接中,"297628"是地理代码,"Bengaluru_Bangalore_District_Karnataka"是城市名称。我们注意到,Tripadvisor上共显示班加罗尔有大约11127家餐馆。所以,输入参数是:
-
地理代码
-
城市名称
-
数据总量
选择好了城市及地理编码,让我们继续编写脚本。第一步是安装导入所需的库requests_html和bs4。
下一步是定义控制变量。由于我们将从德国柏林抓取餐厅数据,因此我们将相应地定义变量。另外,在TripAdvisor上每页共列出30家餐厅,这就构成了我们的页面大小。最后一页的数据偏移量为6330,这将是我们的数据总量。这些控制变量将根据我们要抓取的城市而改变。
pip install "requests_html"
pip install "bs4"
# 导入所需的库
import functools
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
from requests_html import HTMLSession
# 将控制变量存储在变量
scraping_control_variables = {
'city_name' : 'Berlin',
'geo_code' : '187323',
'data_offset_lower_limit' : 0,
'data_offset_upper_limit' : 6330,
'page_num' : 0,
'page_size' : 30
}
在这个脚本中将使用共计10个函数。
-
get_url
-
get_soup_content
-
get_card
-
parse_tripadvisor
-
get_restaurant_data_from_card
-
scrape_star_ratings
-
scrape_reviews
-
scrape_cuisines
-
scrape_title
-
save_to_csv
让我们逐一了解每个函数。
get_url
get_url将地理编码、数据偏移量和城市名称作为输入,并为每一个要抓取的页面创建一个不同的url。该url遵循一个模式,因为数据偏移量是30的倍数。例如:
-
https://www.tripadvisor.in/Restaurants-g187323-oa90-Berlin.html#EATERY_LIST_CONTENTS
-
https://www.tripadvisor.in/Restaurants-g187323-oa120-Berlin.html#EATERY_LIST_CONTENTS
-
https://www.tripadvisor.in/Restaurants-g187323-oa150-Berlin.html#EATERY_LIST_CONTENTS
# 获取每个页面 URL的函数
def get_url(gc, do, city):
data_offset_var = '-oa'+str(do)
if do == 0:
data_offset_var = ''
url = f"https://www.tripadvisor.in/RestaurantSearch-g{gc}{data_offset_var}-a_date.2023__2D__03__2D__05-a_people.2-a_time.20%3A00%3A00-a_zur.2023__5F__03__5F__05-{city}.html#EATERY_LIST_CONTENTS"
print("URL to be scraped: ","\n", url, "\n")
return url
get_soup_content
get_soup_content将地理编码、数据偏移和城市名称作为输入,调用get_url函数。同时,它使用得到的url创建一个响应对象。一旦HTML被访问,我们需要解析HTML并将其加载到BS4结构中。这个soup对象非常方便,用其可访问有用的信息,如标题、菜系、评级等。
-
https://www.tripadvisor.in/Restaurants-g187323-oa90-Berlin.html#EATERY_LIST_CONTENTS
-
https://www.tripadvisor.in/Restaurants-g187323-oa120-Berlin.html#EATERY_LIST_CONTENTS
-
https://www.tripadvisor.in/Restaurants-g187323-oa150-Berlin.html#EATERY_LIST_CONTENTS
# 获取 soup content 的函数
def get_soup_content(gc, do, city):
time.sleep(5)
url = get_url(gc, do, city)
# 开启HTML会话
print("HTML session started")
r = HTMLSession()
response_obj = r.get(url,verify=False)
soup_content = BeautifulSoup(response_obj.content, "html.parser")
return soup_content
get_card
get_card函数将根据餐厅序列号或餐厅数量来获取各个餐厅的卡片。卡片标签遵循这种模式:1_list_item, 2_list_item, 3_list_item,以此类推。屏幕截图供参考。

餐厅卡片标签
# 获取每个餐厅卡片的函数
def get_card(rest_cnt, soup_content):
card_tag = f"{rest_cnt}_list_item"
print(f"Scraping item number: {card_tag}")
card = soup_content.find("div",{"data-test":card_tag})
return card
parse_tripadvisor
parse_tripadvisor函数将前面步骤中定义的控制变量作为输入。这是该脚本中最重要的函数之一。变量data_offset_lower_limit、data_offset_upper_limit、page_num、page_size、geo_code和city_name的值来自scraping_control_variables字典。data_offset_current的值被设置为data_offset_lower_limit的值,在接下来的循环中每页都会增加30。这个while循环一直运行到要抓取的最后一个页面(大约212个页面)。page_start_offset和page_end_offset将采用(0,31),(31,61),(61,91)等值。因为每个页面一般包含30家餐厅。但是由于我们不能完全确定该页是否包含少于30家的餐厅,所以我们也在循环中加入了if条件,用以解决这个问题。函数get_restaurant_data_from_card用来抓取餐厅的详细信息,并将他们附加到空列表restaurants_scraped中。
# 解析每张餐厅卡片
def parse_tripadvisor(scraping_control_variables):
restaurants_scraped = []
data_offset_lower_limit = scraping_control_variables['data_offset_lower_limit']
data_offset_upper_limit = scraping_control_variables['data_offset_upper_limit']
page_num = scraping_control_variables['page_num']
page_size = scraping_control_variables['page_size']
geo_code = scraping_control_variables['geo_code']
city_name = scraping_control_variables['city_name']
data_offset_current = data_offset_lower_limit
while data_offset_current <= data_offset_upper_limit :
print("Scraping Page Number: ", page_num)
print("Scraping Data Offset: ", data_offset_current)
page_start_offset = (page_num*page_size) + 1
page_end_offset = (page_num*page_size) + page_size + 1
soup_content = get_soup_content(geo_code, data_offset_current , city_name)
for rest_cnt in range(page_start_offset , page_end_offset):
card = get_card(rest_cnt, soup_content)
if card is None:
break
restaurant_data = get_restaurant_data_from_card(rest_cnt, data_offset_current, page_num, card)
restaurants_scraped.append(restaurant_data)
print("Scraping Completed for Page Number: ", page_num, "\n" )
print("Data Offset: ", data_offset_current)
page_num = page_num + 1
data_offset_current = data_offset_current + 30
return restaurants_scraped
get_restaurant_data_from_card
get_restaurant_data_from_card函数将餐厅数量、当前数据偏移量、页数和卡号作为输入,并调用创建的各个抓取函数以获取餐厅详细信息。
# 调用scrape函数并将其存储在字典中
def get_restaurant_data_from_card(rest_cnt, data_offset_current, page_num, card):
restaurant_data = {
'title': scrape_title(card),
'cuisines': scrape_cuisines(card) ,
'reviews': scrape_reviews(card),
'star rating': scrape_star_ratings(card),
'page number': page_num,
'data offset': data_offset_current,
'restaurant serial number': rest_cnt
}
return restaurant_data
获取餐厅详细信息的抓取功能
以下所有函数都以卡片作为输入,其中包含了与某一特定餐厅有关的所有信息。
-
scrape_star_ratings (获得该餐厅的星级/客户评价)
-
scrape_reviews (获得该餐厅的总评论)
-
scrape_cuisines (获得该餐厅提供的所有菜系)
-
scrape_title (获得餐厅的名称)
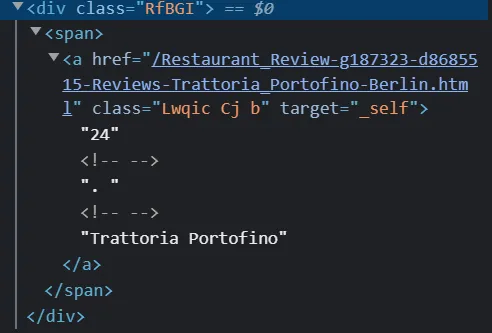
名称标签

评级标签
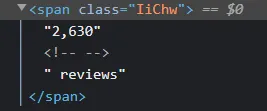
评论标签
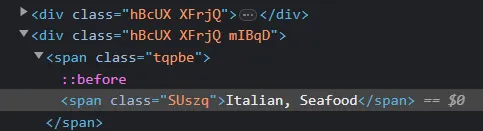
菜系标签
# 抓取函数
def scrape_star_ratings(card):
star_rating = card.find_all('svg',class_ = "UctUV d H0")
scraped_star_ratings = star_rating[0]['aria-label'] if len(star_rating) >= 1 else None
return scraped_star_ratings
def scrape_reviews(card):
reviews = card.find_all('span', class_ = "IiChw")
scraped_reviews = reviews[-1].text if len(reviews) >= 1 else None
return scraped_reviews
def scrape_cuisines(card):
cu_1 = card.find('div', class_ = 'hBcUX XFrjQ mIBqD')
try:
scraped_cuisines = cu_1.find('span', class_ = 'SUszq').get_text()
except AttributeError:
scraped_cuisines = None
return scraped_cuisines
def scrape_title(card):
title = card.find_all('div', class_ = 'RfBGI')
scraped_title = None if len(title) < 1 else title[0].text
return scraped_title
将抓取的文件保存为CSV文件
最后,让我们把DataFrame保存为本地存储库中的csv,这个csv可以用于任何数据分析和数据科学项目。
def save_to_csv(restaurants_scraped):
# 最后,将输出存储到csv文件中
print("storing the data in csv")
output_df = pd.DataFrame(restaurants_scraped)
output_df.drop_duplicates(inplace=True)
output_df.to_csv("ta_berlin_restaurants_scraped.csv", index= False)
print("csv stored")
def scrape_and_save(scraping_control_variables):
restaurants_scraped = parse_tripadvisor(scraping_control_variables)
save_to_csv(restaurants_scraped)
return restaurants_scraped
# 禁用安全证书警告
requests.packages.urllib3.disable_warnings()
restaurants_scraped = scrape_and_save(scraping_control_variables)
# 输出DataFrame
scraped_df = pd.DataFrame(restaurants_scraped)
print("Reastaurant Data Scraped:\n",scraped_df.head(20) )
脚本输出
# 让我们检查一下抓取的餐厅总数
print("Total Restaurants scraped:\t", len(scraped_df)
探索性数据分析

接下来,我们对抓取来的数据做一些探索性数据分析。我们将尝试使用Seaborn进行绘图。
-
德国柏林最受欢迎的十大菜系。
-
德国柏林餐厅的评论数量与星级评分。
clean_dataframe函数负责清理抓取的输出DataFrame,例如从餐厅名称中拆分序列号、删除不必要的列、拆分菜系(因为它们在同一行中用逗号连接)以及从某些列中去除噪音。
scatter_plot_viz函数使用Seaborn创建了一个柏林流行菜系的条形图。它通过可视化评级和评论数量之间的关系来显示柏林的最佳就餐场所。正如图中所描述的那样,我们更喜欢具有高评分和高评论数量的餐厅。
popular_cuisines函数通过将数据集按菜系数量汇总,创建了一个最受欢迎的菜系的条形图。为了计算菜系的数量,我们首先需要将每种菜系用逗号分开,并将其放入单独的行中。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['figure.figsize'] = [12, 8]
# 将输入作为抓取的输出
ta_restaurants = scraped_df
def clean_dataframe(df):
# 清理标题,分割 sr _ no 和名称
df[['sr_no','restaurant_name']] = df["title"].str.split(" ", 1, expand=True)
df["restaurant_name"] = df["restaurant_name"].str.strip(" ")
# 删除不必要的列
df = df.drop('sr_no', axis=1)
df = df.drop('page number', axis=1)
df = df.drop('data offset', axis=1)
# 拆分菜系
df[['cuisine_1','cuisine_2']] = df["cuisines"].str.split(",", expand=True)
df = df.melt(id_vars=["title", "cuisines", "reviews", "star rating", "restaurant serial number", "restaurant_name"],
var_name="cuisines_melt",
value_name="cuisines_all"
)
# 清理列
df["reviews"] = df["reviews"].str.replace('reviews', '').str.replace('review', '').str.replace(',', '').str.strip(" ")
df["star rating"] = df["star rating"].str.replace(' of 5 bubbles', '').str.strip(" ")
df["cuisines_all"] = df["cuisines_all"].str.replace('₹', '').str.replace('₹₹ - ₹₹₹', '').str.replace('-', '').str.strip(" ")
return df
清洗后的DataFrame
def popular_cuisines(df):
# df_popular_cuisines = df.where(df['cuisines_all'] != '').groupby(['cuisines_all'])['restaurant_name'].nunique().sort_values(ascending=False).head(20)
df_popular_cuisines = df.where(df['cuisines_all'] != '').groupby("cuisines_all").agg(total_restaurants_offering_cuisines=('restaurant_name', 'nunique'))
df_popular_cuisines = df_popular_cuisines.sort_values(by = ["total_restaurants_offering_cuisines"],ascending=False).head(10)
df_popular_cuisines['cuisines'] = df_popular_cuisines.index
df_popular_cuisines = df_popular_cuisines.reset_index(drop=True)
print(df_popular_cuisines.head(10))
ax_1 = sns.barplot(data=df_popular_cuisines, x="cuisines", y="total_restaurants_offering_cuisines")
ax_1.set_title('Popular Cuisines in Berlin, Germany', size = 14, font = 'sans', fontweight='bold')
ax_1.set_xlabel("Cuisines", size = 10, font = 'sans', fontweight='bold')
ax_1.set_ylabel("Total Restaurants Offering Cuisines", size = 10, font = 'sans', fontweight='bold')
for i in ax_1.containers:
ax_1.bar_label(i,)
plt.show()
return df_popular_cuisines
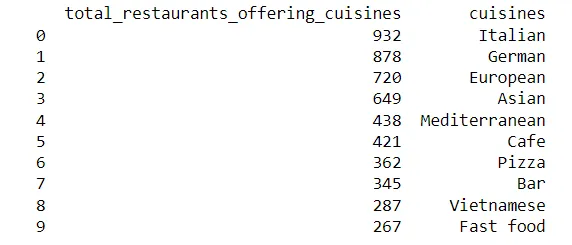
热门菜系DataFrame
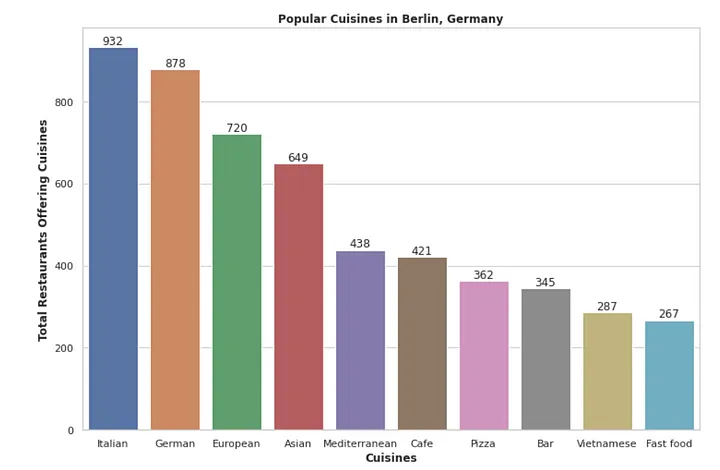
热门菜系条形图
def scatter_plot_viz(df):
df_subset = df[["restaurant_name","reviews","star rating"]]
df_subset = df_subset.drop_duplicates()
df_subset['reviews'] = df_subset['reviews'].fillna(0).astype(int)
df_subset['star rating'] = df_subset['star rating'].fillna(0).astype(float)
df_subset = df_subset.where(df_subset['star rating'] != -1.0)
print(df_subset.head(10))
sns.set( style = "whitegrid" )
ax = sns.scatterplot(x="reviews",
y="star rating",
data=df_subset.sort_values("reviews", ascending= False),
style="star rating",
hue ="star rating",
palette = 'tab10'
)
ax.set_title('Restaurant Rating v/s No. of Reviews', size = 14, font = 'sans', fontweight='bold')
ax.set_xlabel("Reviews", size = 10, font = 'sans', fontweight='bold')
ax.set_ylabel("Ratings", size = 10, font = 'sans', fontweight='bold')
plt.grid(color = 'grey', linestyle = '--', linewidth = 0.5)
ax.set(xscale="linear")
ax.set(xlim = (100,8000))
ax.set(ylim = (1,6))
plt.show()
散点图DataFrame
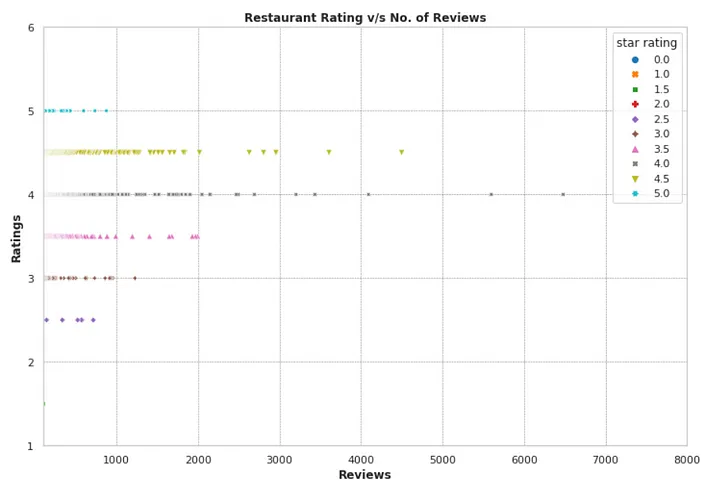
评分与评论可视化
ta_restaurants_clean = clean_dataframe(ta_restaurants)
popular_cuisines_df = popular_cuisines(ta_restaurants_clean)
scatter_plot_viz(ta_restaurants_clean)推荐书单
《Python网络爬虫从入门到精通》
《Python网络爬虫从入门到精通》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python实现网络爬虫开发应该掌握的技术。全书共分19章,内容包括初识网络爬虫、了解Web前端、请求模块urllib、请求模块urllib3、请求模块requests、高级网络请求模块、正则表达式、XPath解析、解析数据的BeautifulSoup、爬取动态渲染的信息、多线程与多进程爬虫、数据处理、数据存储、数据可视化、App抓包工具、识别验证码、Scrapy爬虫框架、Scrapy_Redis分布式爬虫、数据侦探。书中所有知识都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,读者可轻松领会网络爬虫程序开发的精髓,快速提高开发技能。
 https://item.jd.com/13291912.html
https://item.jd.com/13291912.html
精彩回顾
《流式计算来袭,使用Python和PySpark处理流式数据》
《使用Python机器学习预测足球比赛结果:第一篇 数据采集 (下)》
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点

















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









