






一份完整的Pandas初学者指南。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
简介
根据最新的估计,每天有3.2877亿兆字节的数据产生,预计在2025年将会有大约181兆字节的数据产生。因此,现在是我们利用如此大量的数据来拥有敏锐的洞察力并预测现在和未来结果的时候了。
在你的Python开发者或数据科学的旅程中,可能已经多次遇到了pandas这个术语,但仍然需要弄清楚它的作用。以及数据和pandas的关系。因此,首先简单介绍一下pandas。
Pandas是一个建立在NumPy和Matplotlib基础上的Python库,主要设计用于处理数据。它用于分析、清理、探索和操作数据。
它是由Wes McKinney在2008年开发的,用于数据分析目的。
为什么我们需要Pandas?
一般来说,我们通过智能手机、物联网设备、调查和其他各种来源收到的数据充满了相关和不相关的信息,其中包含了重复的、缺失的和不可操作的数值,使得我们很难直接得出结论。正因如此,Pandas让我们能够从数据中产生有意义和有价值的见解。
从以表格形式排列我们的数据、进行统计分析到生成图表,一切都可以通过pandas实现,使数据分析师和科学家可以在一个库下轻松完成所有任务。
简而言之,
pandas就像一个过滤器,我们可以使用它来提纯我们的原始数据,以产生有价值的见解。
如何使用Pandas?
在学习使用pandas的工具之前,必须了解数据在pandas中是如何存储和排列的。Pandas包含两种类型的数据结构:
-
Series
-
Dataframe
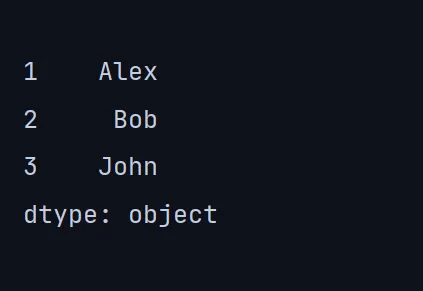
Series:它是一个一维数组,能够容纳任何数据类型的数据。
names = ['Alex', 'Bob', 'John']
df = pd.Series(names, index=[1, 2, 3])
print(df)
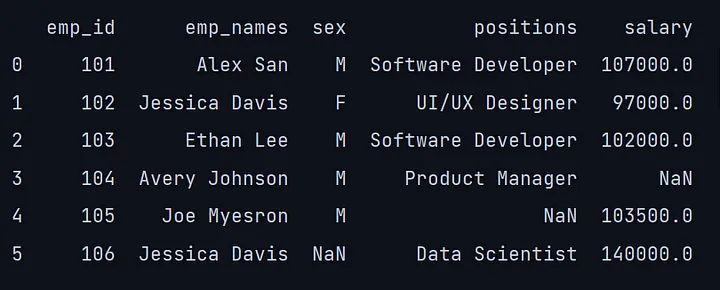
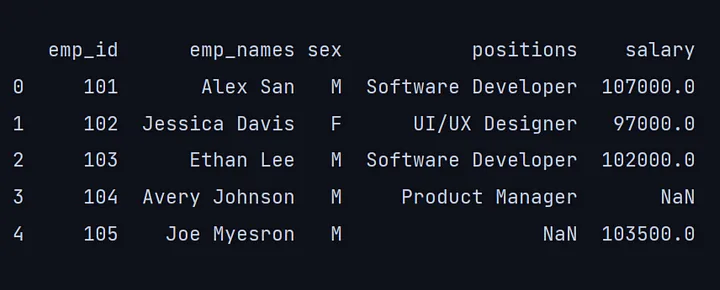
Dataframe:Dataframe是一种由行和列组成的二维数据结构,就像一个表格。它是pandas中最流行的数据结构。
df = pd.read_csv("E:\emp_report.csv")
print(df)
我们导入了一个CSV(Comma Separated Values),这是一个使用逗号分隔数值的分隔文本文件。在pandas中,可以使用read_csv()命令导入一个CSV文件,然后传递文件位置。
1. head()
head方法默认返回dataframe的前五行。
print(df.head())
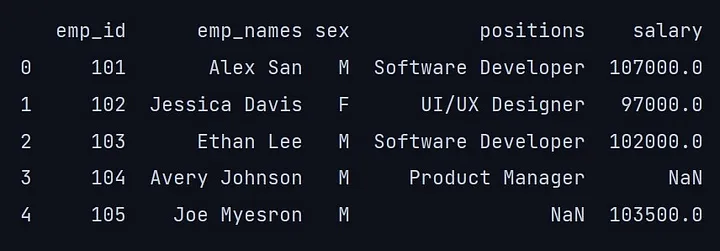
如上可以看到主数据框中有六行,但是使用head命令,它输出了数据框的前五行。
甚至可以用head(n)指定想要的行数;如果我们传递head(12),它将输出数据框的前12行。
2. tail()
tail方法与head类似,但它不是输出最上面的行,而是默认返回数据框的最后五行。
print(df.tail())
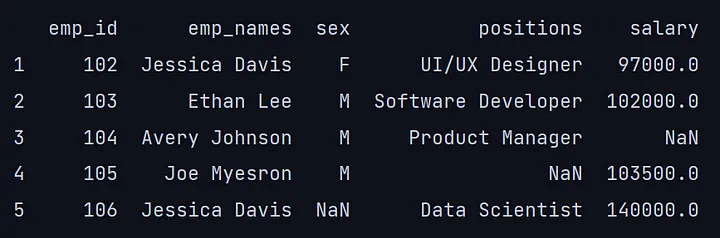
我们甚至可以使用tail(n)指定我们想要的底层行数;如果我们传递tail(10),它将输出数据框的最后10行。
3. info()
info()方法给出了数据框的完整描述,比如列的数量,每一列的数据类型,数据框的内存使用情况等。
print(df.info())
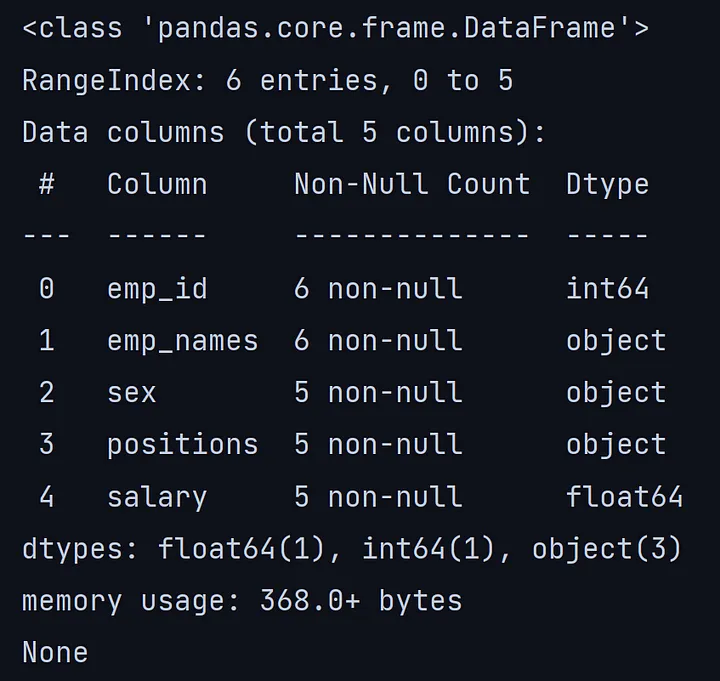
4. describe()
describe()方法给出了数据框的完整统计分析,如每一列的最大值、最小值、百分位数、总非空值和标准差。
print(df.describe())
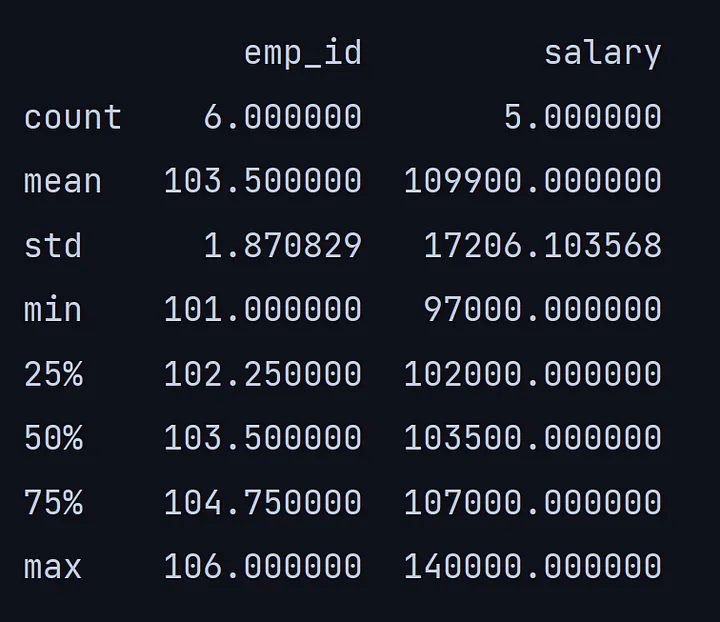
5. shape
Pandas中的shape属性为我们提供了关于数据框形状的信息,即数据框中的行和列的数量。
print(df.shape)

在上图中六指的是行的数量,五指的是列的数量。
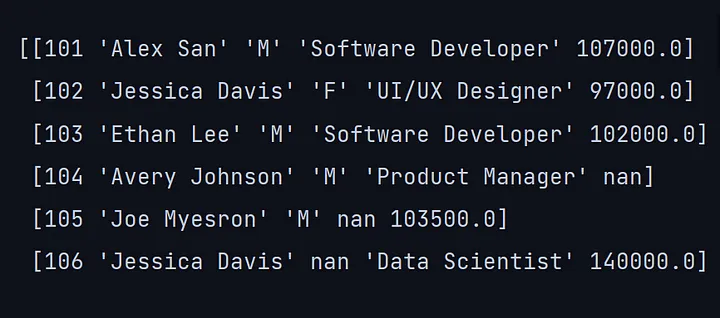
6. values
在一个二维数组中返回数据框的所有值。
print(df.values)
7. columns
columns属性返回数据框中每一列的标签或名称。
print(df.columns)

8. index
index属性返回数据框的索引信息。
print(df.index)

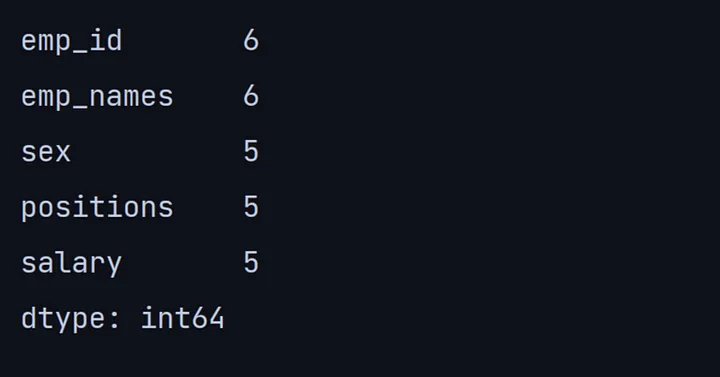
9. count()
count()方法返回每行或每列的非空值或非NA的总数。
print(df.count())
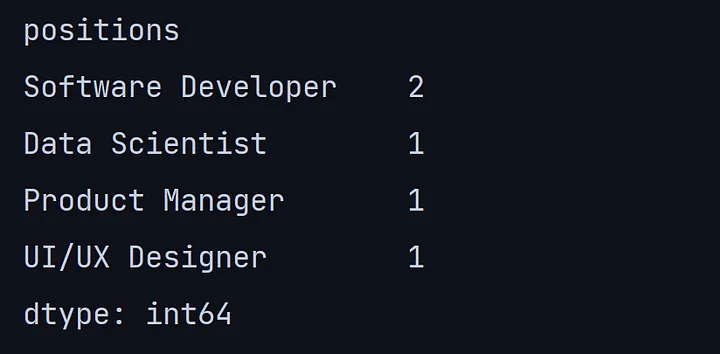
10. value_counts()
value_counts()方法返回唯一值的计数。
print(df.value_counts('positions'))
11. sort_values()
排序意味着以升序或降序的方式排列数据。在Pandas中,我们可以使用sort_values()方法对列进行排序,方法是通过传递列名,然后将ascending参数设置为True或False。
print(df.sort_values('salary', ascending=True))
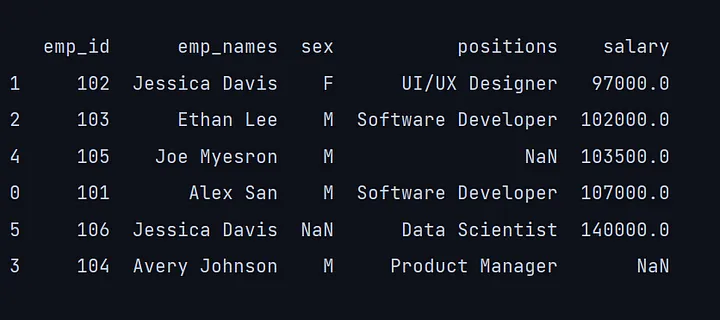
在这里,本文传递了工资列,并将升序参数设置为True,以获得升序排列;升序参数设置为False,将以降序排列工资列。
print(df.sort_values('salary', ascending=False))
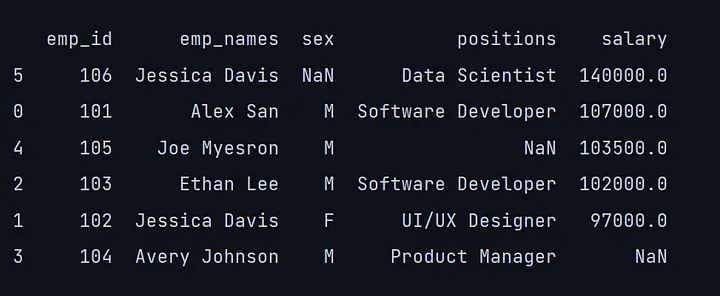
还有一些参数,例如na_position和inplace。na_position允许我们通过first或last来选择如何排列NaN。而当inplace设置为True时,就地执行操作。
12. groupby()
分组使我们能够根据类别对数据进行分组,然后对这些类别执行功能。
print(df.groupby('sex')['salary'].sum())
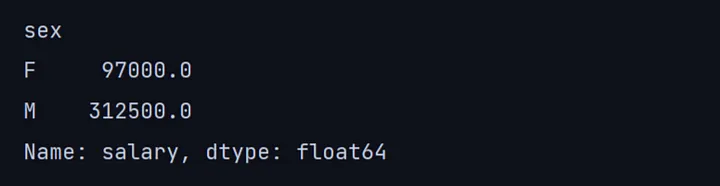
在这里,我们根据性别栏将所有员工分为两类,M代表男性,F代表女性,然后根据性别计算总工资。
13. isna()
使用isna()方法,我们可以检查数据框中的缺失值或NaN(非数字),如果是NaN值则返回True,否则返回False。
print(df.isna())

14. fillna()
fillna()方法将数据框中的缺失值或NaN(非数字)替换为指定值。
print(df.fillna({'sex':'F', 'positions': 'Developer', 'salary': 90000}))
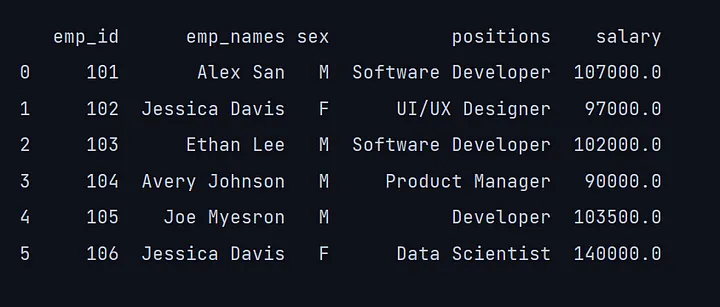
15. dropna()
我们甚至可以使用dropna()方法删除数据框中的具有缺失值或NaN(非数字)的行。
print(df.dropna())
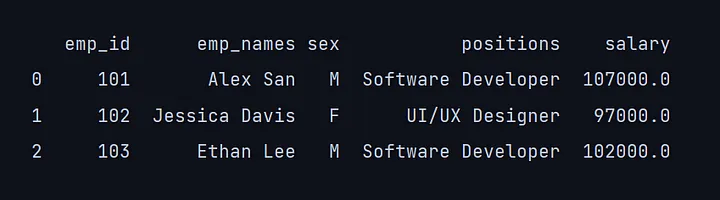
16. duplicated()
duplicated()方法允许我们检查数据框中是否有重复的值。对于重复的值,返回True;否则返回False。
print(df.duplicated(subset='emp_names'))

17. drop_duplicates()
drop_duplicates()方法允许我们删除具有重复值的行。
print(df.drop_duplicates(subset='emp_names'))
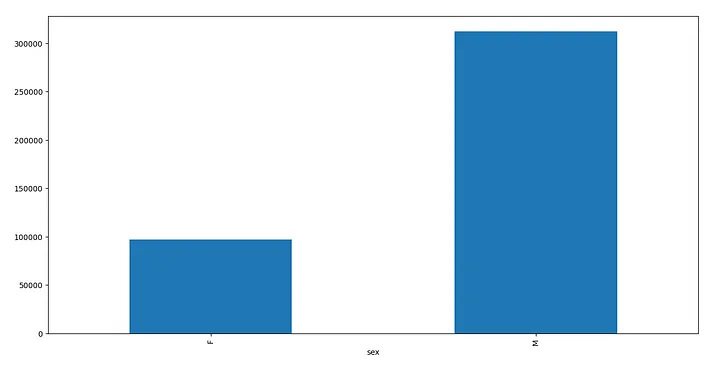
18. plot()
我们可以使用Pandas库和matplotlib库的plot方法绘制图形。下面是一个绘制简单条形图的示例。
import matplotlib.pyplot as plt
g = df.groupby('sex')['salary'].sum()
g.plot.bar(g)
plt.show()
总结
上面的诸多示例表明,Pandas命令快速而灵活,可以让我们分析数据,处理缺失的数据,甚至帮助我们删除重复的数值,并将数据可视化。
推荐书单
《Pandas1.x实例精解》
《Pandas1.x实例精解》详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。《Pandas1.x实例精解》适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。

精彩回顾
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点















 652
652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









