







业务场景概要
游戏场景
《逆水寒》是一款武侠题材的端游 MMO (Massively Multiplayer Online) 大作,玩家扮演古代侠客,在游戏世界中与其它玩家、NPC 进行交互,体验厚重的历史与多彩的江湖。
本次案例分享的场景,是《逆水寒》中的一个核心玩法“流派竞武”。“流派竞武”是单人 PK 玩法,玩家争夺排行榜名次,进攻方发起挑战,防守方无法应战时由机器人代为出战。传统机器人基于规则编写,一方面开发起来费时费力,另一方面水平有限难以满足玩家需要。而使用强化学习训练出来的 RLAI 机器人进行战斗,具有玩家适配、风格多样、水平高超、难度可控等特点。玩家角色的可选技能有几十个,战斗中携带的技能只有十个,实际玩家技能搭配的排列组合非常多,RLAI 机器人在各种技能组合下都有对应的策略,差异明显的搭配下也呈现不同的战斗风格,这是传统规则 AI 无法实现的。
AI 建模
在该场景下,对强化学习算法而言,主要存在以下两个问题:
- 地图较大,AI 需要靠近对手后才能进攻并获得奖赏,存在探索困难的问题
- 随机技能组合,动作组合数共有
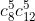
=44352种,AI 需学会在不同技能组合下存在的不同套路打法。
针对第一个问题,我们采用了课程学习的方式,对第二个问题,我们将是否携带了技能作为模型特征编码至网络原始输入状态中。
出于对训练速度的要求,未采用直接的图像输入,输入状态中的信息是通过游戏内置接口获得。
输入状态主要包含:
- AI 自身及对手相对位置(包括距离及角度)
- 表示当前可用动作的 0-1 向量
- 表示当前装备技能的 0-1 向量
- 状态信息(自身及对手的当前属性状态以及Buff信息)
动作主要包含:
- 位移相关:移动、跳、躲避等
- 技能相关(共 10 个)
奖励函数主要包括:
- 胜/负,稀疏,仅在一局游戏结束后才给
- 与 HP 有关的 Reward,包括进攻防守等,稠密
神经网络方面,我们使用的是简单的三层全连接网络。为了加速训练,减少无效动作的探索,我们将状态中的 legal action 信息作为 mask,在网络输出动作前将无效动作进行过滤。

训练框架及环境介绍
单机及多机训练构架
为了对比单机训练和分布式训练方式在本文所述的场景下的区别,我们分别配置了以下两种训练环境:
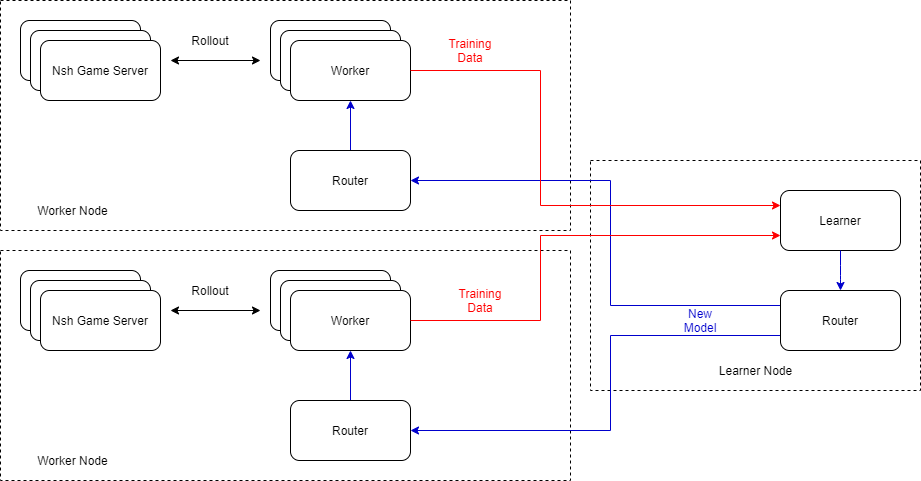
其中,Worker 模块和 Learner 模块上均会维护一套 TensorFlow 的神经网络计算图,区别在于 Worker 上的计算图仅进行推断而不进行训练,计算梯度和反向传播部分操作均在 Learner 模块上进行。Worker 模块在此处负责与游戏模块进行交互,收集训练样本。为了增加样本获取速率,我们会在单个节点上启动多个 Worker 模块。为了不阻塞 Learner 的训练,我们将模型分发模块独立出来,做成了 Router,专门用于分发模型到 Worker 模块。
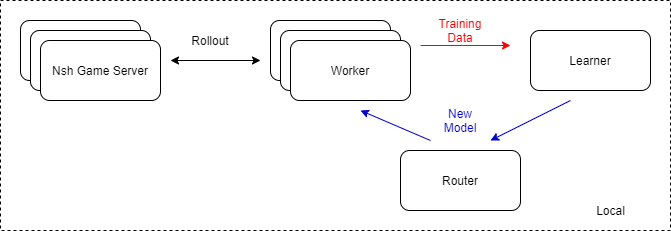
与单机训练模式不同的是,在分布式训练配置下,节点被区分为 Worker 节点与 Learner 节点。Worker 节点仅负责与游戏模块进行交互获取训练数据,Learner 节点仅负责模型训练。节点间的模型分发由各节点上的 Router 模块进行转发。
核心代码
网络定义部分
由于框架支持通过配置文件自动生成网络结构,此处对 TensorFlow 定义网络部分做了一定的包装
- 创建图,Saver 以及对应的配置参数

- 具体网络结构分步构建

- 网络输入部分的 PlaceHolder 构建

- 网络中间层构建方式


Learner 模块训练部分
核心其实就是一个循环,训练后把模型分发给 Worker 模块


Worker 模块
核心逻辑为将交互的得到的训练数据发送给 Learner 模块,更新 Learner 模块发送来的模型


实验设置和结果
实验设置
本次实验对比了单机模式下及分布式(3 节点)模式下训练逆水寒流派竟武 1v1 对战的场景。实验通过对比达到相同测试指标下所消耗的时间差异,来评判分布式训练方式相对于单机的提升效果。
硬件及框架配置:
- 单个节点硬件配置:
- CPU:Intel Xeon Gold 6266C@3GHz
- 内存:192GB
- 单机模式下,框架配置的Worker数量为 40 个
- 分布式模式下,使用四个节点,其中三个为 Worker 节点,每个节点上配置 40 个 Worker(共 120 个Worker),剩余的一个节点为 Learner 节点
算法配置:
- 使用算法:IMPALA [1]
- Batch Size: 256
- Learning Rate: 2.5e-4
- # 优化器参数
- Optimizer: Adam
- Adam Beta_1:0.9
- Adam Beta_2: 0.999
- Adam Epsilon 1.0e-8
- # IMPALA算法计算V-Trace参数
- Rho: 1.0
- C: 1.0
游戏配置:
- 训练角色:血河(近战角色)
- 训练方式:RLAI vs 内置流程图 AI
测试评估方式:双方均配置随机血量/随机技能组合情况下,测试 100 局对战后各项指标取平均值(采用此种方式进行评估是为了能够综合评价 RLAI 在不同情况下对于内置流程图AI的测试指标情况,如:出生时血量较对手少,技能组合较对手差等劣势情况)。
结果分析
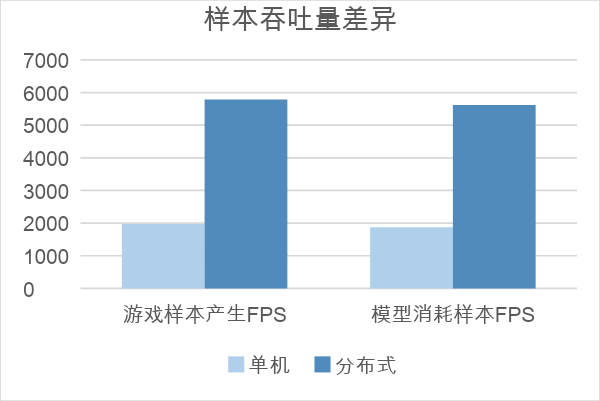
首先,我们对比了不同配置下,训练样本产生速率及消耗速率的差异,从图上看,分布式配置下,样本产生和消耗速率的提升基本与 Worker 个数增加成正比。
此外,我们还对比了游戏中相关的指标(包括测试胜率,技能失败率,战斗结束剩余血量比例,平均死亡率);可以看出,达到相同的指标,分布式训练耗时差不多是原有 40% 左右。
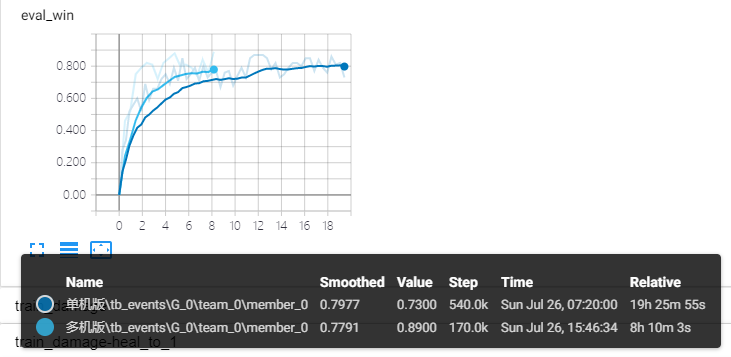
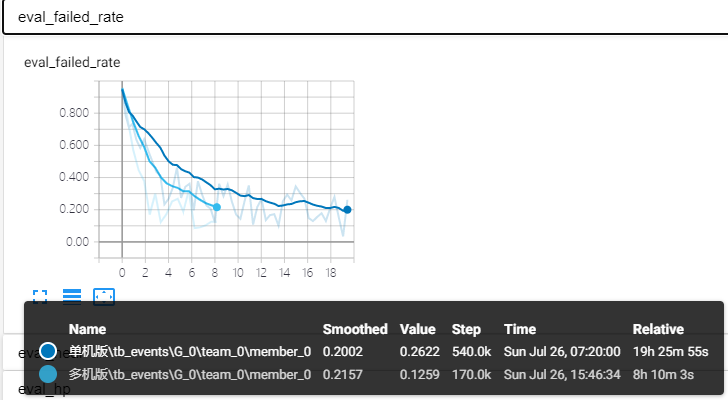
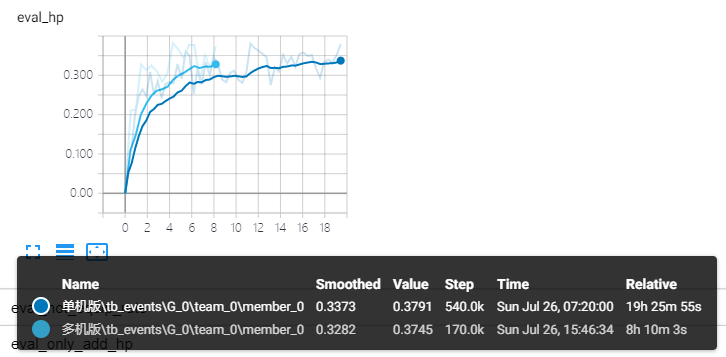
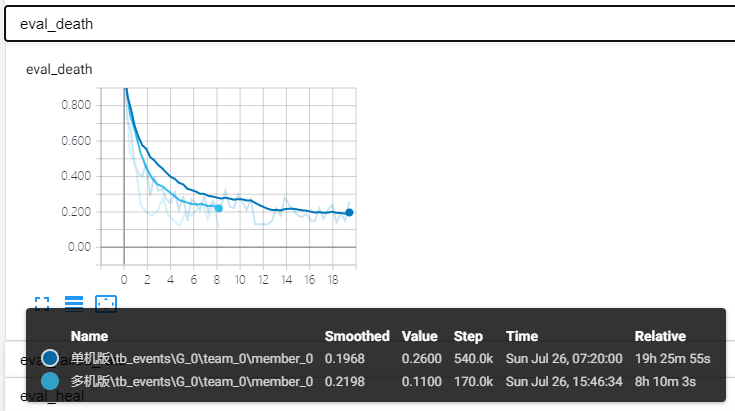
由此,可以说明借助 TensorFlow 实现的分布式强化学习训练方案,在训练逆水寒 1v1 的 RLAI 过程中,能够较为有效的缩短训练时长,同时模型依旧保持较高的水准。
总结
本文以逆水寒游戏场景为例,介绍了网易伏羲实验室如何使用 TensorFlow 实现分布式训练,生产用于线上使用的 RL-GameAI。上线后,AI 对战玩家的胜率可以达到 90% 以上,其效果已接近人类顶尖高手操作水平。
后续我们将继续探索,将前沿技术、先进算法、TensorFlow 框架与实际游戏工业场景相结合,更高效优质的生产游戏 AI,提供人工智能在游戏场景中的解决方案。
文 / 南北, @网易伏羲AI实验室
— 参考文献 —
[1] Espeholt, Lasse, et al. "Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures." arXiv preprint arXiv:1802.01561 (2018).
想了解更多 TensorFlow 落地应用?欢迎关注 TensorFlow 官方微信公众号(TensorFlow_official)!


















 2971
2971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









